DeepSeek-V3 리뷰: 하드웨어-소프트웨어 협업이 이끈 비용 효율적 초대규모 모델 학습 전략
2024년은 GPT-4o, LLaMA 3, Claude 3.5 Sonnet, Grok-2 등 굵직한 LLM이 잇달아 등장하며 ‘스케일의 시대’가 한층 가속화되었습니다. 그 흐름 속에서 DeepSeek-AI가 공개한 DeepSeek-V3는 단 2,048대의 NVIDIA H800 GPU만으로 SOTA 성능을 달성해 업계의 이목을 집중시켰습니다. 본 리뷰에서는 논문의 기술적 기여와 하드웨어-소프트웨어(Co-Design) 관점에서의 시사점을 정리하고, 실제 PaaS / AI 인프라 설계 시 고려할 요소를 제안합니다.
핵심 기여 요약
| 과제 | DeepSeek-V3의 해법 | 효과 |
|---|---|---|
| 메모리 병목 | Multi-head Latent Attention (MLA)로 KV Cache 압축 | HBM 사용량 대폭 절감, 장문 대화 효율 ↑ |
| 연산-통신 균형 | DeepSeekMoE (Mixture-of-Experts) + 노드 제한 라우팅 | 토큰당 FLOPs ↓, IB 트래픽 중복 제거 |
| 훈련 비용 | FP8 Mixed-Precision 전면 도입 | 동일 품질 대비 비용·전력 ↓ |
| 추론 속도 | Multi-Token Prediction (MTP) + 듀얼 마이크로배치 오버랩 | TPOT 이론 한계 14.8 ms → 67 TPS |
| 네트워크 비용 | Multi-Plane 2-계층 Fat-Tree | 3계층 대비 스위치 수·비용 절감 |
DeepSeek-V3 아키텍처 개요
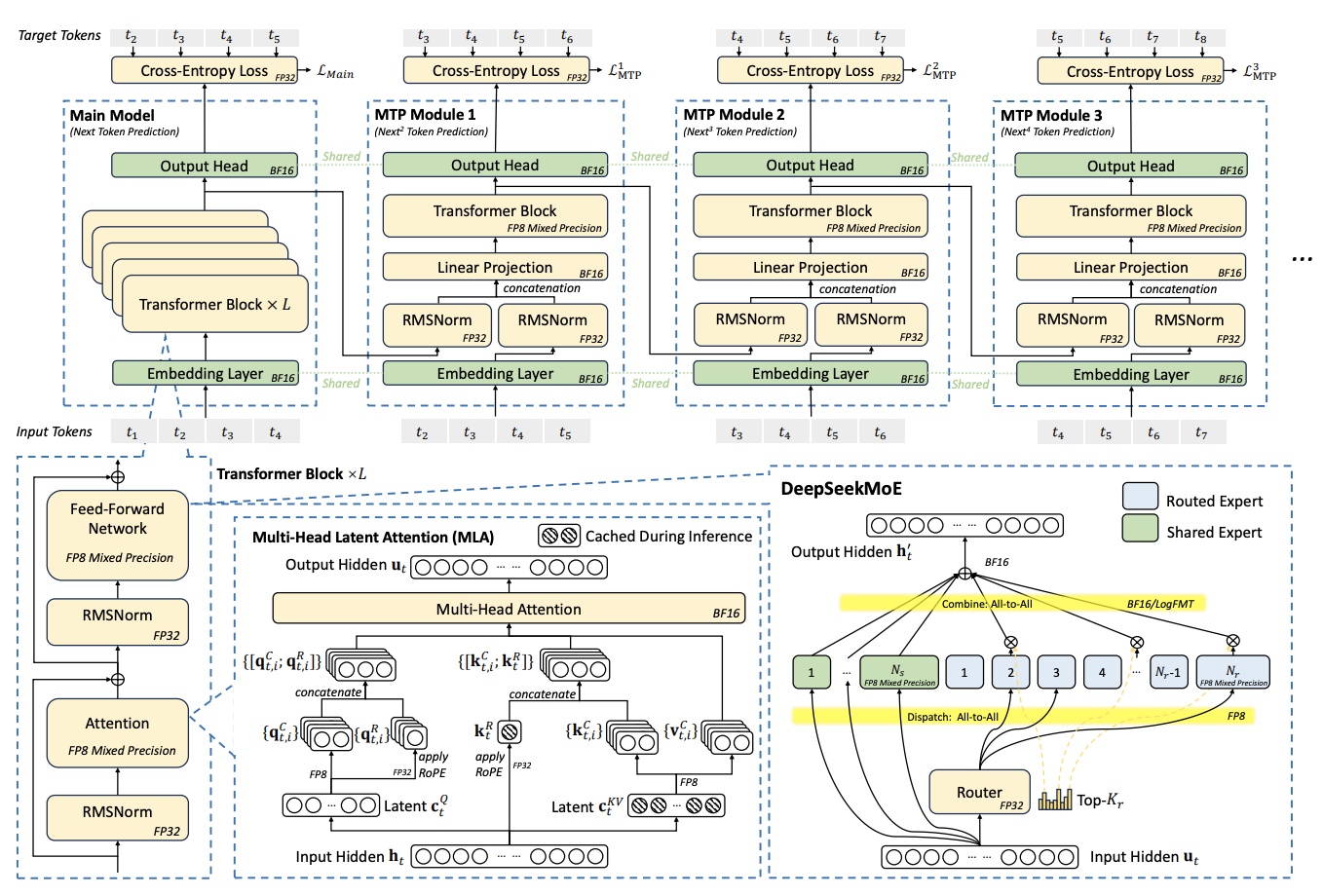 Figure 1: DeepSeek-V3의 기본 아키텍처. MLA(Multi-head Latent Attention), DeepSeekMoE, Multi-Token Prediction 모듈, FP8 mixed-precision 훈련이 통합된 구조를 보여줍니다.
Figure 1: DeepSeek-V3의 기본 아키텍처. MLA(Multi-head Latent Attention), DeepSeekMoE, Multi-Token Prediction 모듈, FP8 mixed-precision 훈련이 통합된 구조를 보여줍니다.
위 다이어그램에서 볼 수 있듯이, DeepSeek-V3는 여러 혁신적인 구성 요소들이 유기적으로 결합된 아키텍처를 채택하고 있습니다. 특히 MTP(Multi-Token Prediction) 모듈이 메인 모델과 병렬로 동작하며, FP8 mixed-precision이 모든 컴포넌트에 적용되어 있는 점이 주목할 만합니다.
기술 요소 심층 분석
MLA: KV Cache 압축의 정석
Transformer 디코딩은 토큰 수에 비례해 KV Cache가 기하급수로 증가합니다. MLA는 각 헤드의 KV를 라티언트 벡터로 투영해 저장 공간을 대폭 줄였습니다. GQA/MQA 대비 정확도 손실 없이 HBM 소모를 절반 수준으로 억제—장문 컨텍스트 서비스에 실질적 이점이 있습니다.
DeepSeekMoE & 노드 제한 라우팅
MoE는 ‘모두 큰 모델, 토큰엔 작은 모델’ 전략입니다. V3(671 B)에서 토큰 활성 파라미터가 37 B에 불과해 Dense Qwen-2.5-72 B보다 연산량이 36% 낮습니다. 다만 EP (all-to-all) 트래픽이 병목이 되는데, V3는 한 토큰당 최대 4개 노드로만 라우팅하여 IB 대역폭 요구를 50% 이상 줄였습니다.
FP8 Mixed-Precision 훈련
Hopper Tensor Core의 FP8 누산 정밀도 제약을 타일-단위 스케일링(1×128)으로 극복했습니다. 16 B와 230 B 모델로 계층적 검증 후 대규모 학습에 적용—BF16 대비 <0.25% 미세 손실. 향후 Blackwell GPU의 마이크로스케일링 지원과 맞물려 더 큰 효과가 기대됩니다.
MTP: 자기 Drafting 방식 추론 가속
한 스텝에 후보 토큰을 여러 개 생성-검증하는 Speculative Decoding의 경량 버전입니다. 2번째 토큰 수용률 80~90% → TPS 1.8×. RL · DPO 파이프라인에선 샘플링 속도가 곧 비용이므로 가치가 큽니다.
Multi-Plane Fat-Tree
64-포트 400 G IB 스위치를 2계층으로만 구성하되, NIC 8개를 서로 다른 Plane에 매핑하여 트래픽 격리와 포트 집적도를 동시에 달성했습니다. 실측 결과 MRFT(싱글 Plane) 대비 훈련 MFU, All-to-All 지연 차이가 오차 범위 내였습니다.
한계 및 향후 하드웨어 제언
- FP8 누산 정확도 → 차세대 GPU는 FP32 누산 옵션과 미세 스케일링을 Tensor Core에 통합해야 합니다.
- SM 통신 부담 → NVLink ↔ IB 데이터 포워딩을 전담하는 코프로세서 / I/O Die 필요.
- RoCE 지연 → AI 특화 저지연 RoCE 스위치 + Adaptive Routing + VOQ 구현 시 IB 대비 TCO 강점 확보 가능.
- CPU-GPU PCIe 병목 → NVLink-CXL 융합 또는 SoC 패키징으로 해결; 확장 DRAM 대역폭(>1 TB/s)도 필수.
- Silent Data Corruption → ECC를 넘어 Checksum + HW Redundancy 지원과 실시간 진단 도구 표준화가 시급.
실무 적용 인사이트
- 프라이빗 클라우드: MLA + MoE 조합은 GPU 수량이 제한된 온프레미스 환경에서 가성비가 극대화됩니다.
- Inference 서비스: 듀얼 마이크로배치 + MTP 설계는 멀티-테넌트 LLM API에서 P99 Latency를 안정적으로 낮추는 열쇠입니다.
- 네트워크 설계: 2-계층 MPFT는 10k GPU 이하 규모에서 비용-효율 최적; 다만 IBGDA 같은 GPU 주도 RDMA 기능 지원 여부를 체크해야 합니다.
- MLOps 관점: FP8 훈련 파이프라인을 CI/CD에 도입하려면 세분화된 학습 안정성 모니터링과 가속기-버전 고정 정책이 필요합니다.
맺음말
DeepSeek-V3는 ‘스케일만이 답‘이라는 통념을 뒤집고, 하드웨어-소프트웨어 협업을 통해 합리적 자원으로도 SOTA를 달성할 수 있음을 증명했습니다. GPU 세대 교체 주기가 짧아지는 상황에서, 이러한 아키텍처-의식적 설계는 경쟁력이 될 것입니다. 프라이빗 AI 클라우드 및 개인화 LLM 시장을 겨냥한다면, DeepSeek-V3의 전략은 강력한 벤치마크이자 로드맵의 출발점이 될 것입니다.
“하드웨어의 한계를 인정할 때, 소프트웨어 혁신이 시작된다.”