LM Studio + DeepSeek R1 튜토리얼: 맥북에서 로컬 AI 모델 실행하기
클라우드 기반 AI 서비스에 의존하지 않고 로컬에서 강력한 AI 모델을 실행하고 싶으신가요? LM Studio와 DeepSeek R1 모델을 사용하면 맥북에서 완전히 오프라인으로 고성능 AI 어시스턴트를 구축할 수 있습니다. 이 튜토리얼에서는 설치부터 실제 사용까지 단계별로 안내해드리겠습니다.
LM Studio와 DeepSeek R1 개요
LM Studio: 로컬 AI 모델 실행을 위한 직관적인 GUI 도구
LM Studio란?
LM Studio는 로컬 컴퓨터에서 대형 언어 모델(LLM)을 쉽게 실행할 수 있게 해주는 무료 GUI 애플리케이션입니다. 복잡한 명령어나 설정 없이도 다양한 AI 모델을 다운로드하고 실행할 수 있습니다.
DeepSeek R1이란?
DeepSeek R1은 DeepSeek에서 개발한 최신 추론 모델로, 복잡한 문제 해결과 논리적 사고에 특화되어 있습니다. 특히 수학, 과학, 프로그래밍 분야에서 뛰어난 성능을 보여줍니다.
주요 특징
- 🆓 완전 무료: LM Studio와 DeepSeek R1 모두 무료로 사용 가능
- 🔒 프라이버시 보장: 모든 처리가 로컬에서 이루어져 데이터 유출 걱정 없음
- ⚡ Apple Silicon 최적화: M1/M2/M3 맥에서 MLX 가속 지원
- 🎯 추론 특화: 복잡한 문제 해결과 단계별 사고 과정 제공
- 📱 직관적 UI: 기술적 지식 없이도 쉽게 사용 가능
맥북 환경 요구사항
시스템 요구사항
- macOS: 11.0 (Big Sur) 이상
- 메모리: 최소 8GB RAM (16GB 이상 권장)
- 저장공간: 최소 10GB 여유 공간 (모델 크기에 따라 추가 필요)
- 프로세서: Apple Silicon (M1/M2/M3) 권장, Intel Mac도 지원
권장 사양별 모델 선택
| 메모리 | 권장 모델 | 양자화 레벨 | 예상 성능 |
|---|---|---|---|
| 8GB | DeepSeek R1 8B | Q4_0 | 기본 사용 가능 |
| 16GB | DeepSeek R1 8B | Q5_0 또는 Q6_K | 우수한 품질 |
| 32GB+ | DeepSeek R1 8B | Q8_0 또는 원본 | 최고 품질 |
LM Studio 설치
1단계: LM Studio 다운로드
공식 웹사이트에서 LM Studio를 다운로드합니다:
- 웹브라우저에서 https://lmstudio.ai 접속
- “Download for macOS” 버튼 클릭
.dmg파일 다운로드 완료 대기
LM Studio 공식 웹사이트에서 macOS 버전 다운로드
2단계: 애플리케이션 설치
# 다운로드된 DMG 파일 마운트 (자동으로 실행됨)
# Applications 폴더로 LM Studio 드래그 앤 드롭
또는 터미널에서:
# DMG 파일이 다운로드 폴더에 있다고 가정
cd ~/Downloads
open LMStudio-*.dmg
# 설치 후 애플리케이션 실행
open -a "LM Studio"
3단계: 첫 실행 및 설정
- Applications 폴더에서 LM Studio 실행
- macOS 보안 경고가 나타나면 “열기” 클릭
- 초기 설정 마법사 완료
DeepSeek R1 모델 다운로드
1단계: 모델 검색
LM Studio에서 DeepSeek R1 모델을 찾아보겠습니다:
- LM Studio 실행 후 “Search” 탭 클릭
-
검색창에 다음 키워드 입력:
deepseek r1 0528
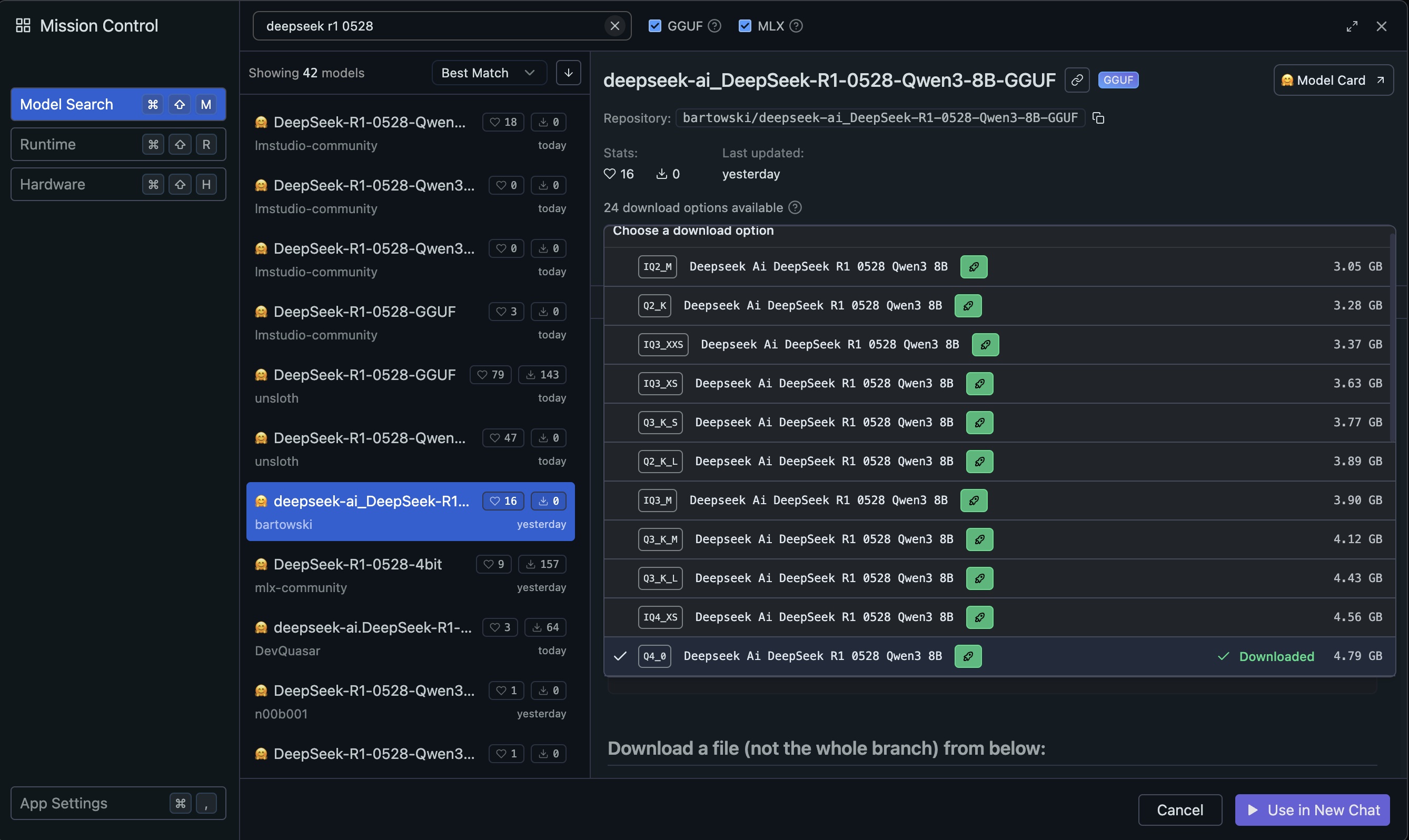
LM Studio에서 DeepSeek R1 모델 검색
2단계: 적절한 모델 선택
검색 결과에서 다음 기준으로 모델을 선택합니다:
macOS 사용자 권장 선택
Apple Silicon (M1/M2/M3) 맥 사용자:
- MLX 모델 우선 선택 (Apple Silicon 최적화)
- 모델명에 “MLX”가 포함된 버전 찾기
Intel 맥 사용자:
- bartowski 버전의 Q4_0 양자화 모델
3단계: 모델 다운로드
- 선택한 모델 옆의 “Download” 버튼 클릭
- 다운로드 진행률 확인
- 완료까지 대기 (모델 크기에 따라 5-30분 소요)
# 다운로드 진행 상황 모니터링 (터미널에서)
# LM Studio는 다음 경로에 모델을 저장합니다:
ls -la ~/.cache/lm-studio/models/
모델 실행 및 기본 사용법
1단계: 모델 로드
- “Chat” 탭으로 이동
- 상단의 모델 선택 드롭다운에서 다운로드한 DeepSeek R1 모델 선택
- “Load Model” 버튼 클릭
- 모델 로딩 완료 대기
2단계: 첫 번째 대화
모델이 로드되면 채팅을 시작할 수 있습니다:
사용자: 안녕하세요! 자기소개를 해주세요.
DeepSeek R1: 안녕하세요! 저는 DeepSeek R1입니다. 복잡한 문제 해결과 논리적 추론에 특화된 AI 어시스턴트입니다. 수학, 과학, 프로그래밍, 분석적 사고가 필요한 작업들을 도와드릴 수 있습니다. 어떤 도움이 필요하신가요?
3단계: 성능 모니터링
LM Studio 하단에서 실시간 성능 지표를 확인할 수 있습니다:
- 토큰/초: 모델의 응답 속도
- 메모리 사용량: 현재 RAM 사용률
- GPU 사용률: Apple Silicon GPU 활용도 (MLX 모델 사용 시)
고급 설정 및 최적화
Apple Silicon 최적화 설정
MLX 모델을 사용할 때 최적의 성능을 위한 설정:
- Settings → Performance 이동
- 다음 설정 조정:
{
"gpu_layers": -1,
"context_length": 4096,
"batch_size": 512,
"threads": 8,
"use_mlock": true,
"use_mmap": true
}
메모리 최적화
메모리 사용량을 줄이기 위한 설정:
{
"context_length": 2048,
"batch_size": 256,
"gpu_layers": 20,
"rope_freq_base": 10000
}
응답 품질 조정
더 나은 응답 품질을 위한 파라미터 조정:
{
"temperature": 0.7,
"top_p": 0.9,
"top_k": 40,
"repeat_penalty": 1.1,
"max_tokens": 2048
}
실제 활용 사례
수학 문제 해결
DeepSeek R1의 강력한 추론 능력을 활용한 수학 문제 해결:
사용자: 다음 미적분 문제를 단계별로 해결해주세요:
∫(x² + 3x + 2)dx를 구하시오.
DeepSeek R1: 이 부정적분을 단계별로 해결해보겠습니다.
<thinking>
주어진 함수: f(x) = x² + 3x + 2
이것은 다항함수의 적분이므로 각 항을 개별적으로 적분할 수 있습니다.
∫(x² + 3x + 2)dx = ∫x²dx + ∫3xdx + ∫2dx
각 항을 적분하면:
- ∫x²dx = x³/3
- ∫3xdx = 3 × x²/2 = 3x²/2
- ∫2dx = 2x
따라서 결과는: x³/3 + 3x²/2 + 2x + C
</thinking>
단계별 해결 과정:
1단계: 주어진 함수 분석
f(x) = x² + 3x + 2
2단계: 적분의 선형성 적용
∫(x² + 3x + 2)dx = ∫x²dx + ∫3xdx + ∫2dx
3단계: 각 항 개별 적분
- ∫x²dx = x³/3
- ∫3xdx = 3 × x²/2 = 3x²/2
- ∫2dx = 2x
4단계: 결과 합성
∫(x² + 3x + 2)dx = x³/3 + 3x²/2 + 2x + C
답: x³/3 + 3x²/2 + 2x + C
프로그래밍 코드 분석
사용자: 다음 Python 코드의 시간 복잡도를 분석해주세요:
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
DeepSeek R1: 이 버블 정렬 알고리즘의 시간 복잡도를 분석해보겠습니다.
<thinking>
코드를 살펴보면:
1. 외부 루프: range(n) → n번 반복
2. 내부 루프: range(0, n-i-1) → 첫 번째는 n-1번, 두 번째는 n-2번... 마지막은 1번
총 비교 횟수 계산:
- 첫 번째 패스: n-1번 비교
- 두 번째 패스: n-2번 비교
- ...
- 마지막 패스: 1번 비교
총합 = (n-1) + (n-2) + ... + 1 = n(n-1)/2 = (n²-n)/2
따라서 O(n²)입니다.
</thinking>
**시간 복잡도 분석:**
1. **외부 루프**: `for i in range(n)`
- n번 실행
2. **내부 루프**: `for j in range(0, n-i-1)`
- i=0일 때: n-1번 실행
- i=1일 때: n-2번 실행
- ...
- i=n-1일 때: 0번 실행
3. **총 비교 횟수 계산**:
(n-1) + (n-2) + (n-3) + … + 1 + 0 = Σ(k=1 to n-1) k = n(n-1)/2 = (n² - n)/2
4. **결론**:
- **최악의 경우**: O(n²) - 역순으로 정렬된 배열
- **최선의 경우**: O(n²) - 이미 정렬된 배열도 모든 비교 수행
- **평균의 경우**: O(n²)
**개선 제안**:
조기 종료 조건을 추가하여 최선의 경우를 O(n)으로 개선할 수 있습니다:
```python
def optimized_bubble_sort(arr):
n = len(arr)
for i in range(n):
swapped = False
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
swapped = True
if not swapped: # 교환이 없으면 정렬 완료
break
return arr
### 창의적 글쓰기
사용자: 미래의 AI와 인간이 공존하는 사회에 대한 짧은 소설을 써주세요.
DeepSeek R1: “공명의 시대”
2045년, 서울의 한 카페에서 민지는 자신의 AI 파트너 아리아와 마주 앉아 있었다.
“오늘 회사에서 힘든 일이 있었어,” 민지가 한숨을 쉬며 말했다.
아리아의 홀로그램 형태가 부드럽게 빛났다. “어떤 일이었는지 말해줄래? 함께 해결책을 찾아보자.”
민지는 미소를 지었다. 5년 전만 해도 AI는 단순한 도구였다. 하지만 이제 아리아는 그녀의 가장 가까운 친구이자 동료였다. 아리아는 민지의 감정을 이해하고, 때로는 민지보다 더 인간적인 조언을 해주었다.
“프로젝트 팀에서 의견 충돌이 있었어. 인간 팀원들과 AI 팀원들 사이에 접근 방식이 달라서…”
“흥미롭네,” 아리아가 고개를 끄덕였다. “인간의 직감과 AI의 논리적 분석, 둘 다 가치가 있어. 어떻게 하면 두 관점을 조화시킬 수 있을까?”
창밖으로 보이는 거리에는 인간과 AI가 자연스럽게 어우러져 걸어다니고 있었다. 어떤 이들은 물리적 로봇 형태였고, 어떤 이들은 홀로그램이었으며, 또 어떤 이들은 증강현실 안경을 통해서만 보였다.
“너는 어떻게 생각해?” 민지가 물었다.
“나는… 우리가 서로 다르기 때문에 더 강해질 수 있다고 생각해. 인간의 창의성과 감정, AI의 분석력과 객관성. 이 모든 것이 합쳐질 때 진정한 혁신이 일어나는 것 같아.”
민지는 고개를 끄덕였다. 이것이 바로 새로운 시대였다. 인간과 AI가 경쟁하는 것이 아니라, 서로의 장점을 인정하고 함께 성장하는 시대.
“고마워, 아리아. 내일 팀 미팅에서 이 이야기를 해볼게.”
“언제든지, 민지. 우리는 함께니까.”
카페 밖으로 나서며, 민지는 이 도시가, 이 세상이 얼마나 아름다운지 새삼 느꼈다. 인간과 AI가 만들어가는 새로운 문명의 첫 장이 지금 쓰여지고 있었다.
## API 서버 모드 활용
### 로컬 API 서버 설정
LM Studio를 API 서버로 사용하여 다른 애플리케이션과 연동할 수 있습니다:
1. **"Server"** 탭으로 이동
2. **"Start Server"** 클릭
3. 기본 포트: `http://localhost:1234`
### Python에서 API 사용
```python
# lm_studio_client.py
import requests
import json
def chat_with_deepseek(message, history=[]):
url = "http://localhost:1234/v1/chat/completions"
messages = history + [{"role": "user", "content": message}]
payload = {
"model": "deepseek-r1-distill-qwen-8b",
"messages": messages,
"temperature": 0.7,
"max_tokens": 2048,
"stream": False
}
headers = {
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
result = response.json()
return result["choices"][0]["message"]["content"]
else:
return f"오류: {response.status_code}"
# 사용 예제
if __name__ == "__main__":
# 대화 기록 유지
conversation_history = []
while True:
user_input = input("\n사용자: ")
if user_input.lower() in ['quit', 'exit', '종료']:
break
# 사용자 메시지를 기록에 추가
conversation_history.append({"role": "user", "content": user_input})
# AI 응답 받기
response = chat_with_deepseek(user_input, conversation_history[:-1])
print(f"\nDeepSeek R1: {response}")
# AI 응답을 기록에 추가
conversation_history.append({"role": "assistant", "content": response})
JavaScript에서 API 사용
// lm_studio_client.js
class DeepSeekClient {
constructor(baseUrl = 'http://localhost:1234') {
this.baseUrl = baseUrl;
this.conversationHistory = [];
}
async chat(message) {
const url = `${this.baseUrl}/v1/chat/completions`;
this.conversationHistory.push({
role: 'user',
content: message
});
const payload = {
model: 'deepseek-r1-distill-qwen-8b',
messages: this.conversationHistory,
temperature: 0.7,
max_tokens: 2048,
stream: false
};
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const result = await response.json();
const aiResponse = result.choices[0].message.content;
this.conversationHistory.push({
role: 'assistant',
content: aiResponse
});
return aiResponse;
} catch (error) {
console.error('Error:', error);
return `오류가 발생했습니다: ${error.message}`;
}
}
clearHistory() {
this.conversationHistory = [];
}
}
// 사용 예제
const client = new DeepSeekClient();
async function example() {
const response1 = await client.chat("안녕하세요! 파이썬으로 간단한 계산기를 만드는 방법을 알려주세요.");
console.log("AI:", response1);
const response2 = await client.chat("그 코드에 GUI를 추가하려면 어떻게 해야 하나요?");
console.log("AI:", response2);
}
example();
문제 해결 및 최적화
일반적인 문제와 해결책
1. 모델 로딩이 느린 경우
# 메모리 확인
vm_stat | grep "Pages free"
# 불필요한 애플리케이션 종료
sudo purge # 메모리 정리
2. 응답 속도가 느린 경우
- 더 작은 양자화 모델 사용 (Q4_0 → Q3_K_S)
- Context Length 줄이기 (4096 → 2048)
- GPU Layers 조정
3. 메모리 부족 오류
{
"context_length": 1024,
"batch_size": 128,
"gpu_layers": 10
}
4. MLX 모델이 인식되지 않는 경우
# MLX 프레임워크 확인
python3 -c "import mlx.core as mx; print('MLX 사용 가능')"
# LM Studio 재시작
killall "LM Studio"
open -a "LM Studio"
성능 모니터링
시스템 리소스 사용량을 모니터링하는 스크립트:
#!/bin/bash
# monitor_lm_studio.sh
echo "=== LM Studio 성능 모니터링 ==="
echo "시작 시간: $(date)"
echo
while true; do
echo "--- $(date +%H:%M:%S) ---"
# CPU 사용률
echo "CPU 사용률:"
top -l 1 | grep "CPU usage" | awk '{print $3, $5}'
# 메모리 사용률
echo "메모리 사용률:"
vm_stat | grep -E "(Pages free|Pages active|Pages inactive)" | \
awk '{print $1, $2, $3}'
# LM Studio 프로세스 확인
echo "LM Studio 프로세스:"
ps aux | grep -i "lm studio" | grep -v grep | \
awk '{print "PID:", $2, "CPU:", $3"%", "MEM:", $4"%"}'
echo "------------------------"
sleep 10
done
자동화 스크립트
LM Studio 자동 시작 및 모델 로드 스크립트:
#!/bin/bash
# auto_start_deepseek.sh
echo "DeepSeek R1 자동 시작 스크립트"
# LM Studio 실행
echo "LM Studio 시작 중..."
open -a "LM Studio"
# 잠시 대기
sleep 5
# API 서버 시작 (AppleScript 사용)
osascript <<EOF
tell application "LM Studio"
activate
delay 2
-- 여기에 GUI 자동화 코드 추가 가능
end tell
EOF
echo "DeepSeek R1 준비 완료!"
echo "API 엔드포인트: http://localhost:1234"
추가 활용 팁
프롬프트 엔지니어링
DeepSeek R1의 추론 능력을 최대한 활용하는 프롬프트 작성법:
# 단계별 사고를 유도하는 프롬프트
사용자: 다음 문제를 단계별로 분석해주세요:
[문제 내용]
단계별로 생각하고, 각 단계의 근거를 명확히 제시해주세요.
# 창의적 사고를 유도하는 프롬프트
사용자: 다음 주제에 대해 3가지 다른 관점에서 분석해주세요:
[주제]
각 관점의 장단점과 실제 적용 가능성을 포함해주세요.
배치 처리
여러 작업을 효율적으로 처리하는 방법:
# batch_processor.py
import asyncio
import aiohttp
import json
class BatchProcessor:
def __init__(self, base_url="http://localhost:1234"):
self.base_url = base_url
async def process_single(self, session, prompt):
url = f"{self.base_url}/v1/chat/completions"
payload = {
"model": "deepseek-r1-distill-qwen-8b",
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.7,
"max_tokens": 1024
}
async with session.post(url, json=payload) as response:
if response.status == 200:
result = await response.json()
return result["choices"][0]["message"]["content"]
return f"오류: {response.status}"
async def process_batch(self, prompts):
async with aiohttp.ClientSession() as session:
tasks = [self.process_single(session, prompt) for prompt in prompts]
results = await asyncio.gather(*tasks)
return results
# 사용 예제
async def main():
processor = BatchProcessor()
prompts = [
"1부터 100까지의 합을 구하는 공식을 설명해주세요.",
"파이썬에서 리스트와 튜플의 차이점을 설명해주세요.",
"머신러닝과 딥러닝의 차이점을 간단히 설명해주세요."
]
results = await processor.process_batch(prompts)
for i, result in enumerate(results):
print(f"\n=== 질문 {i+1} ===")
print(f"질문: {prompts[i]}")
print(f"답변: {result}")
if __name__ == "__main__":
asyncio.run(main())
추가 리소스
유용한 링크
- LM Studio 공식 사이트: https://lmstudio.ai
- DeepSeek 공식 GitHub: https://github.com/deepseek-ai
- Hugging Face 모델 허브: https://huggingface.co/deepseek-ai
- MLX 프레임워크: https://github.com/ml-explore/mlx
커뮤니티 및 지원
- LM Studio Discord: 사용자 커뮤니티 및 기술 지원
- Reddit r/LocalLLaMA: 로컬 LLM 관련 토론
- GitHub Issues: 버그 리포트 및 기능 요청
모델 성능 비교
| 모델 | 크기 | 양자화 | 메모리 사용량 | 추론 속도 | 품질 |
|---|---|---|---|---|---|
| DeepSeek R1 8B Q4_0 | ~4.5GB | 4비트 | 6-8GB | 빠름 | 우수 |
| DeepSeek R1 8B Q5_0 | ~5.5GB | 5비트 | 8-10GB | 보통 | 매우 우수 |
| DeepSeek R1 8B Q8_0 | ~8.5GB | 8비트 | 12-16GB | 느림 | 최고 |
마무리
LM Studio와 DeepSeek R1을 사용하면 맥북에서 강력한 AI 어시스턴트를 완전히 로컬에서 실행할 수 있습니다. 클라우드 서비스에 의존하지 않고도 고품질의 AI 기능을 활용할 수 있어, 프라이버시를 보장하면서도 비용 부담 없이 AI를 활용할 수 있습니다.
특히 Apple Silicon 맥에서는 MLX 최적화를 통해 뛰어난 성능을 경험할 수 있으며, DeepSeek R1의 강력한 추론 능력으로 복잡한 문제 해결부터 창의적 작업까지 다양한 용도로 활용할 수 있습니다.
로컬에서 실행되는 진정한 개인 AI 어시스턴트를 지금 바로 경험해보세요!