ميتا-سكيل تتعامل مع المهارات ‘كأنها برمجيات’: تقرير تحقّق مباشر من yao-meta-skill v1.1.0
 رسم مفاهيمي للميتا-سكيل التي تتعامل مع المهارة لا كموجّه لمرّة واحدة، بل كـ”أصل قابل لإعادة الاستخدام” مرفق بالإصدار والتحقّق والحوكمة.
رسم مفاهيمي للميتا-سكيل التي تتعامل مع المهارة لا كموجّه لمرّة واحدة، بل كـ”أصل قابل لإعادة الاستخدام” مرفق بالإصدار والتحقّق والحوكمة.
نظرة عامة
في بيئات الوكلاء مثل Claude Code وCursor وCodex CLI، لم تعد المهارة (Skill) مجرّد مجموعة من الموجّهات. إنها أقرب إلى منتج قدرات يغلّف العمل المتكرّر لإعادة استخدامه عبر عدّة أُطُر تشغيل (harness). لكن كلّما تكاثرت المهارات، كبرت في الوقت نفسه ثلاث مشكلات: تباين الجودة، وتصادم المُحفِّزات (triggers)، وتكلفة السياق. ومشروع yao-meta-skill مفتوح المصدر — الذي صار حديث الناس بعد أن أوصى به المؤثّر الصيني @vista8 (نحو 113K متابع) بوصفه “أقوى من Skill-creator الرسمية من Anthropic” — يستهدف هذه النقطة بالذات.
اسم YAO اختصار لـ “Yielding AI Outcomes”، ويصف المستودع نفسه بأنه “نظام صارم للهندسة والتقييم والحوكمة وقابلية النقل لمهارات الوكلاء القابلة لإعادة الاستخدام”. ولم آخذ هذا الادّعاء كما هو، بل استنسخته مباشرةً في بيئة عمل ThakiCloud ثم شغّلت فعليًّا بوابات التحقّق المحلية التي يوفّرها المستودع. هذا المقال تقرير تنفيذ يفكّك بنية yao-meta-skill انطلاقًا من تلك النتائج المقيسة، ويتأمّل ما يمكن استعارته من منظور تشغيل .claude/skills الداخلي.
ما هي هذه الأداة
yao-meta-skill هي “مهارة تصنع مهارات”، أي ميتا-سكيل. تأخذ العمل المتكرّر — مثل ملاحظات سير العمل، ومجموعات الموجّهات، ونصوص المحادثات، وكتب التشغيل (runbooks)، وأنماط المستندات — مُدخَلًا، وتحوّله إلى حزمة مهارة قابلة للتحقّق. ويتلخّص تصميمها الجوهري في ثلاثة أعمدة.
أولًا، Skill IR (التمثيل الوسيط — Intermediate Representation). تُوصَف أولًا النيّة والمُحفِّزات والمُدخَلات والمُخرَجات والحدود (boundaries) والمراجع والمخرجات المتوقّعة في تمثيل وسيط محايد للمنصّات. ثم تحوّل المُصرِّفات (compilers) والمحوّلات (adapters) المستهدفة هذا الـ IR إلى خمسة أهداف: OpenAI وClaude والمهارات العامة للوكلاء والحزم المتوافقة مع Agent-Skills وسير العمل الموجَّه نحو VS Code. وفكرة وصف المهارة مرّة واحدة وتصريفها إلى بيئات متعدّدة تستهدف بدقّة عبء إدارة المهارة نفسها مرّتين عبر Claude Code وCursor داخليًّا.
ثانيًا، Output Eval Lab. وهي طبقة تتحقّق من جودة مخرجات المهارة بالبيانات: فحص المُحفِّزات، وتأكيدات المخرجات (assertions)، وأدلّة التنفيذ، وأدلّة الزمن والرموز (tokens)، وقابلية إعادة إنتاج القياس المرجعي (benchmark)، وحُزَم المراجعة المُعمّاة. وما يلفت النظر أن البنية تجعل الكود يتحقّق فعليًّا، بدلًا من أن يدّعي النموذج “أن الأمر نجح”.
ثالثًا، Review Studio 2.0. تجمع النيّة والمُحفِّزات وتقييم المخرجات وتكلفة السياق وفحوص وقت التشغيل وأدلّة الإصدار في صفحة بوابة HTML واحدة. إنها بوابة تُثبّت بصريًّا ما الذي يجب اجتيازه قبل إصدار أي مهارة.
الرخصة MIT، ويُعلن البيان الوصفي (manifest) درجة النضج بأنها “governed”، ومرحلة دورة الحياة بأنها “library”، ودورية المراجعة بأنها “quarterly”. فالنيّة في إدارة المهارات كالكود — بالإصدارات والدرجات ودوريات المراجعة — تتجلّى من مستوى البيانات الوصفية نفسه.
 خطّ معالجة تمرّ فيه مُدخَلات العمل المتكرّر عبر Skill IR، فتُصرَّف إلى منصّات متعدّدة، ثم تجتاز بوابتَي Output Eval Lab وReview Studio لتنتهي كأدلّة إصدار.
خطّ معالجة تمرّ فيه مُدخَلات العمل المتكرّر عبر Skill IR، فتُصرَّف إلى منصّات متعدّدة، ثم تجتاز بوابتَي Output Eval Lab وReview Studio لتنتهي كأدلّة إصدار.
التثبيت والتكامل (أوامر حقيقية)
جرى التحقّق في صندوق رمل معزول. ووفقًا للقواعد الداخلية، وُضِعت شجرة العمل خارج المستودع وجرى تنظيفها بعد الانتهاء.
# 1) استنساخ المستودع الخارجي
git clone --depth 1 https://github.com/yaojingang/yao-meta-skill
# 2) تثبيت الاعتماد الأدنى في الـ .venv المشترك (قاعدة python-runtime)
VIRTUAL_ENV="$REPO_ROOT/.venv" uv pip install "PyYAML==6.0.3"
اعتماديات المستودع خفيفة على نحو مدهش. فمتطلّبات التكامل المستمر (requirements-ci.txt) كانت سطرًا واحدًا فقط: PyYAML==6.0.3. أي أن أدوات التحقّق مبنية حول مكتبة بايثون القياسية الخالصة بلا أُطُر تشغيل ثقيلة — وهذه إشارة جيّدة لإدراجها في خطّ تكامل مستمر.
والتركيب الفعلي الذي قِسته فور الاستنساخ كان كالآتي: 632 ملفًّا متتبَّعًا، و77 اختبارًا، و29 تقييمًا (evals)، و10 مدخلات في أطلس المهارات (skill_atlas)، و3 مخطّطات (schemas)، وقالبَين (templates). فهذه ليست “مهارة” واحدة، بل أقرب إلى مصنع صغير ينتج المهارات ويتحقّق منها ويحوكمها.
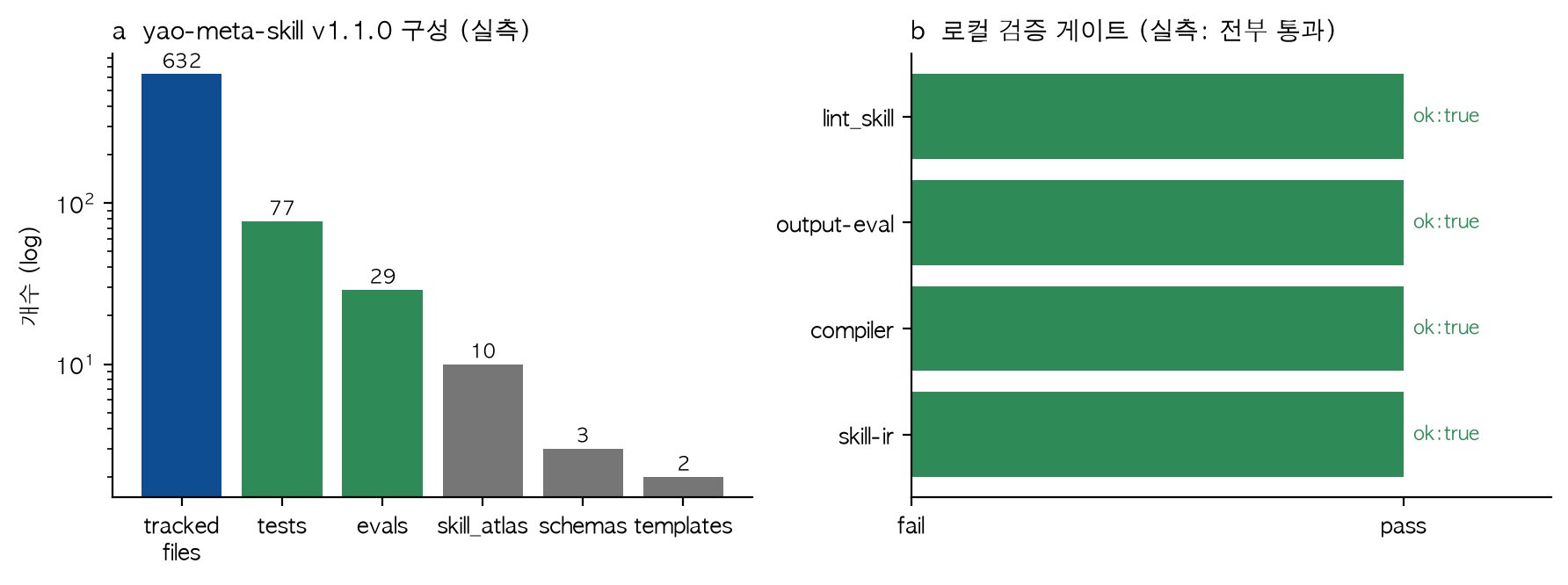 إلى اليسار: التركيب المقيس للمستودع (مقياس لوغاريتمي). وإلى اليمين: اجتياز بوابات التحقّق المحلية الأربع جميعها.
إلى اليسار: التركيب المقيس للمستودع (مقياس لوغاريتمي). وإلى اليمين: اجتياز بوابات التحقّق المحلية الأربع جميعها.
نتائج التحقّق الفعلية
عرّف ملف Makefile أكثر من 25 هدف تحقّق. وقد شغّلت فعليًّا أربعة منها — Skill IR والمُصرِّف وتقييم المخرجات والتدقيق (lint) — وقَيّدت النتائج.
make skill-ir-check
# python3 tests/verify_skill_ir.py -> {"ok": true}
# python3 tests/verify_skill_ir_paths.py -> {"ok": true}
make compiler-check
# python3 tests/verify_compile_skill.py -> {"ok": true}
make output-eval-check
# python3 tests/verify_output_eval_lab.py -> {"ok": true}
python3 scripts/lint_skill.py ./ # مقابل ملف SKILL.md المُرفق
# {"ok": true, "failures": [], "warnings": []}
اجتازت البوابات الأربع جميعها بـ ok: true، وأبلغ التدقيق عن صفر إخفاقات وصفر تحذيرات. وهذه الأرقام قَيّدتها بتشغيلها بنفسي، لا باقتباس من مصدر خارجي. والمثير للاهتمام أن خرج التحقّق يأتي بصيغة JSON حتمية على هيئة {"ok": true} لا نصًّا إنشائيًّا. وهذه صيغة قابلة للقراءة الآلية تستطيع خطوط المعالجة الأعلى أن تبني عليها البوابات تلقائيًّا — وهو الاتجاه ذاته الذي يقوم عليه مبدأ ThakiCloud القائل إن “الصيغة يملكها الكود”.
غير أن قيدًا واحدًا تكشّف أيضًا بالقياس. إذ أصدر lint_skill.py خطأ استخدام عند استدعائه بلا وسائط، واشترط تحديد دليل المهارة صراحةً. وأرجع سكربت قياس حجم السياق (context_sizer.py) تقديرًا للرموز قيمته 0 في بعض المسارات، وبدا حسّاسًا لطريقة تمرير الوسائط. أي إن التنبيه التشغيلي هو: “أهداف make تعمل جيّدًا، لكن استدعاء السكربتات الفردية مباشرةً يتطلّب مطابقة الواجهة بدقّة”.
التطبيق والدلالات لمنصّة ThakiCloud K8s AI/ML SaaS
تشغّل ThakiCloud بالفعل أكثر من ألف مهارة وقاعدة داخلية. وعند هذا الحجم، فإن أكبر تكلفة ليست المهارات نفسها، بل ضريبة السياق التي تدفعها كل مهارة مُفهرَسة في كل جلسة، إضافةً إلى تصادم المُحفِّزات. وتتلخّص النقاط الجديرة بالاستعارة من yao-meta-skill في ثلاث.
أولًا، التبنّي الجزئي لفكرة Skill IR. فبدلًا من إدارة المهارات الداخلية مرّتين عبر Claude Code وCursor، يقلّل وصف النيّة والمُحفِّزات والحدود وصفًا محايدًا مرّة واحدة ثم التصريف لكل بيئة من سطح الإدارة. وقد يكون التبنّي الكامل مبالغًا فيه، لكن بنينة وصف (description) المهارات الجديدة ومُحفِّزاتها كأنها مخطّط IR تفيد وحدها.
ثانيًا، استعارة بوابات على نمط Output Eval Lab. فلدينا داخليًّا بالفعل بوابات تحرير وسكربتات تحقّق حتمية، لكن تقييم المُحفِّزات — أي الفحص بالبيانات عمّا إذا كان المُحفِّز يُطلَق كما هو مقصود — ضعيف نسبيًّا. وهذا نمط قابل للاستخدام المباشر لتقليل ضوضاء المشتّتات (distractor noise) في موجّه المهارات.
ثالثًا، بوابة إصدار واحدة على نمط Review Studio. فبوابة تؤكّد النيّة والمُحفِّزات وتكلفة السياق ووقت التشغيل في صفحة واحدة قبل دمج مهارة جديدة، متماثلة فلسفيًّا مع بوابات النشر (ArgoCD وKueue) لمنصّة AI/ML SaaS العاملة فوق K8s. فكما نضع بوابة على نشر الكود، نضع بوابة على نشر المهارة.
القيود والحجج المضادة
تفاديًا للتلخيص المتفائل وحده، أُسجّل الحجج المضادة بوضوح.
أولًا، مصدر ادّعاء “أقوى من الرسمية” هو توصية مؤثّر. صحيح أن بنية المستودع والتحقّق المحلي متينان، لكن Skill-creator الرسمية من Anthropic تمتاز بحلقات إنشاء سريعة تبدأ بالمحادثة، وهذا غرض مختلف. والأداتان متكاملتان لا متنافستان. ومقارنة “الأقوى” تكون دقيقة فقط حين تُحصَر ببناء أصول فِرَق تحتاج إلى حوكمة.
ثانيًا، تكلفة التبنّي. فإدخال مصنع بحجم 632 ملفًّا كما هو مبالغة لفرد واحد أو فريق صغير. والمسار الواقعي هو الاستعارة الانتقائية للأفكار الجوهرية (IR، تقييم المُحفِّزات، البوابة الواحدة).
ثالثًا، حسّاسية الواجهة التشغيلية. فكما تأكّد بالقياس سابقًا، كانت السكربتات الفردية حسّاسة للوسائط وأرجع بعض القياسات قيمة 0. وعند الإدراج في التكامل المستمر، يُغلَّف الأمر على مستوى أهداف make وتُثبَّت واجهات السكربتات الفردية.
في الختام، تُعدّ yao-meta-skill من أكثر الأمثلة مفتوحة المصدر تجسيدًا ملموسًا لاتّجاه “هندسة المهارات كأنها برمجيات”. وحتى من دون تبنّيها بالكامل، فإن أي منظّمة تصير فيها المهارات أصولًا ستجد مبادئ تصميمها جديرةً بالدراسة.
المصادر
- yao-meta-skill (GitHub, MIT): github.com/yaojingang/yao-meta-skill
- البيان الوصفي للمستودع ونتائج التحقّق: جميع الأرقام في هذا المقال مقيسة محليًّا باستنساخ v1.1.0.