NVIDIA GLM-5.2-NVFP4: خدمة نموذج MoE رائد بحجم 753B بدقة 4 بت
 تصوّر مفاهيمي لتكثيف أوزان 16 بت إلى 4 بت.
تصوّر مفاهيمي لتكثيف أوزان 16 بت إلى 4 بت.
بالنسبة لأي فريق يحاول خدمة نموذج استدلال من الطراز الرائد على بنيته التحتية الخاصة، فإن أول جدار يصطدم به هو ذاكرة وحدة معالجة الرسوميات (GPU). تحميل 753 مليار معامل بدقة 16 بت يتطلب ما يقارب 1.5 تيرابايت، أي عدة عُقد GPU. نموذج nvidia/GLM-5.2-NVFP4، الذي صدر على Hugging Face في 25 يونيو 2026، يكمّم نموذج GLM-5.2 من ZAI (zai-org) إلى 4 بت في محاولة لخفض هذا الجدار.
هذه المقالة ليست تعريفاً بنموذج GLM-5.2 نفسه. كيف يعيد طول رموز الاستدلال في النموذج تشكيل حسابات تكلفة الاستضافة الذاتية مشروح في مقالة اقتصاديات رموز الاستدلال، وتكميم GGUF بدقة 1 بت للعتاد الاستهلاكي في مقالة Unsloth GGUF. هذه المقالة تنظر إلى مسار مركز البيانات: ما البنية التي اختارها تكميم NVFP4 الرسمي من NVIDIA، وعلى أي عتاد يُخدَم، وماذا يعني ذلك لمشغّل يدير خدمة متعددة المستأجرين.
كل رقم دقة هنا هو قياس رسمي منشور في بطاقة نموذج NVIDIA. النموذج بحجم 753B مخصص لـ Blackwell فقط ويتطلب توازياً موتّرياً بمقدار 8، لذا لم نتمكن من إعادة إنتاجه في بيئة تطوير ThakiCloud. لذلك فهذه المقالة تحليل مبني على مواد عامة ولم نختلق أي أرقام إعادة إنتاج. الأرقام التي تختلف بين المصادر مُعلَّمة بـ [تقديري].
نظرة عامة
nvidia/GLM-5.2-NVFP4 هو نسخة من zai-org/GLM-5.2 لـ ZAI مكمَّمة بأداة NVIDIA Model Optimizer (ModelOpt). النموذج الأساس هو بنية مزيج خبراء (MoE) للاستدلال والبرمجة، بإجمالي 753 مليار معامل يُفعَّل منها 40 مليار فقط لكل رمز. بنيته الشبكية هي GlmMoeDsaForCausalLM، ويستخدم انتباهاً متناثراً مع مُفهرِس IndexShare لدعم سياق يصل إلى مليون رمز. الترخيص هو MIT، مثل النموذج الأساس، ويتيح الاستخدام التجاري وغير التجاري.
جوهر الأمر في جملة واحدة: MoE يقلّل الحوسبة، والتكميم الانتقائي بـ NVFP4 يقلّل الذاكرة، والأجزاء الحسّاسة للدقة تُستثنى عمداً من التكميم. بفضل بنية MoE، حتى عند 753B تظل الحوسبة لكل رمز محصورة في خبراء الـ 40B المفعَّلين. ثم يُنزِل NVFP4 أوزان الخبراء الموجَّهين، التي تشكّل معظم بصمة الذاكرة، من 16 بت إلى 4 بت، مع إبقاء الخبير المشترك غير مكمَّم بدقة BF16 لتقليل خسارة الدقة.
التوقيت مهم. صدور نموذج مفتوح الأوزان قوي بترخيص MIT يتزامن مع إعادة NVIDIA إصداره، مُحسَّناً لعتادها، في صيغة قابلة للخدمة مباشرة. بالنسبة للمؤسسات التي توازن سيادة النماذج، هذه ليست قضية سياسات مجردة بل خيار معماري آنيّ: أي GPU يشغّل ماذا، وكيف.
ما هو هذا النموذج
GLM-5.2 هو نموذج استدلال وبرمجة من نوع MoE من ZAI. على عكس النموذج الكثيف (dense) التقليدي، يضع عدة شبكات خبراء داخل كل كتلة محوِّل ويفعّل مجموعة فرعية فقط لكل رمز إدخال. يحمل GLM-5.2 إجمالي 753 مليار معامل، لكن 40 مليار فقط تشارك فعلياً في توليد رمز معيّن. “سعته المعرفية” من فئة 753B، بينما حوسبة الاستدلال أقرب إلى نموذج كثيف بحجم 40B.
علاوة على ذلك، يستخدم GLM-5.2 انتباهاً متناثراً مع مُفهرِس IndexShare. التصميم يدعم سياق مليون رمز مع تجنّب تكلفة الانتباه الكامل الذي يقارن كل زوج رموز. تسمّي بطاقة النموذج هذه البنية glm_moe_dsa وتتطلب transformers>=5.3.0 للتشغيل. هاتان الطبقتان من التناثر، تناثر MoE وتناثر الانتباه، تتكاملان لتقديم استدلال من الطراز الرائد بحوسبة اقتصادية نسبياً، وهذه نقطة انطلاق GLM-5.2.
NVFP4 هو نوع بيانات عائم بدقة 4 بت عرّفته NVIDIA. المفتاح أنه عائم وليس عدداً صحيحاً بـ 4 بت. على وجه التحديد، يحزم قيماً عائمة صغيرة (E2M1) في كتل من 16 عنصراً ويرفق بكل كتلة مقياس FP8 (E4M3)، وهو تحجيم على مستوى الكتل بمرحلتين. لأن كل كتلة تتتبّع مداها الديناميكي الخاص، يحافظ على أذيال التوزيع أفضل بكثير من التكميم الصحيح البسيط. تذكر NVIDIA بوضوح في بطاقة النموذج أن هذا ليس نموذجاً درّبته من الصفر بل نسخة مكمَّمة من نموذج طرف ثالث، أُنتجت بأداة NVIDIA Model Optimizer مفتوحة المصدر.
المفتاح هو التكميم “الانتقائي”
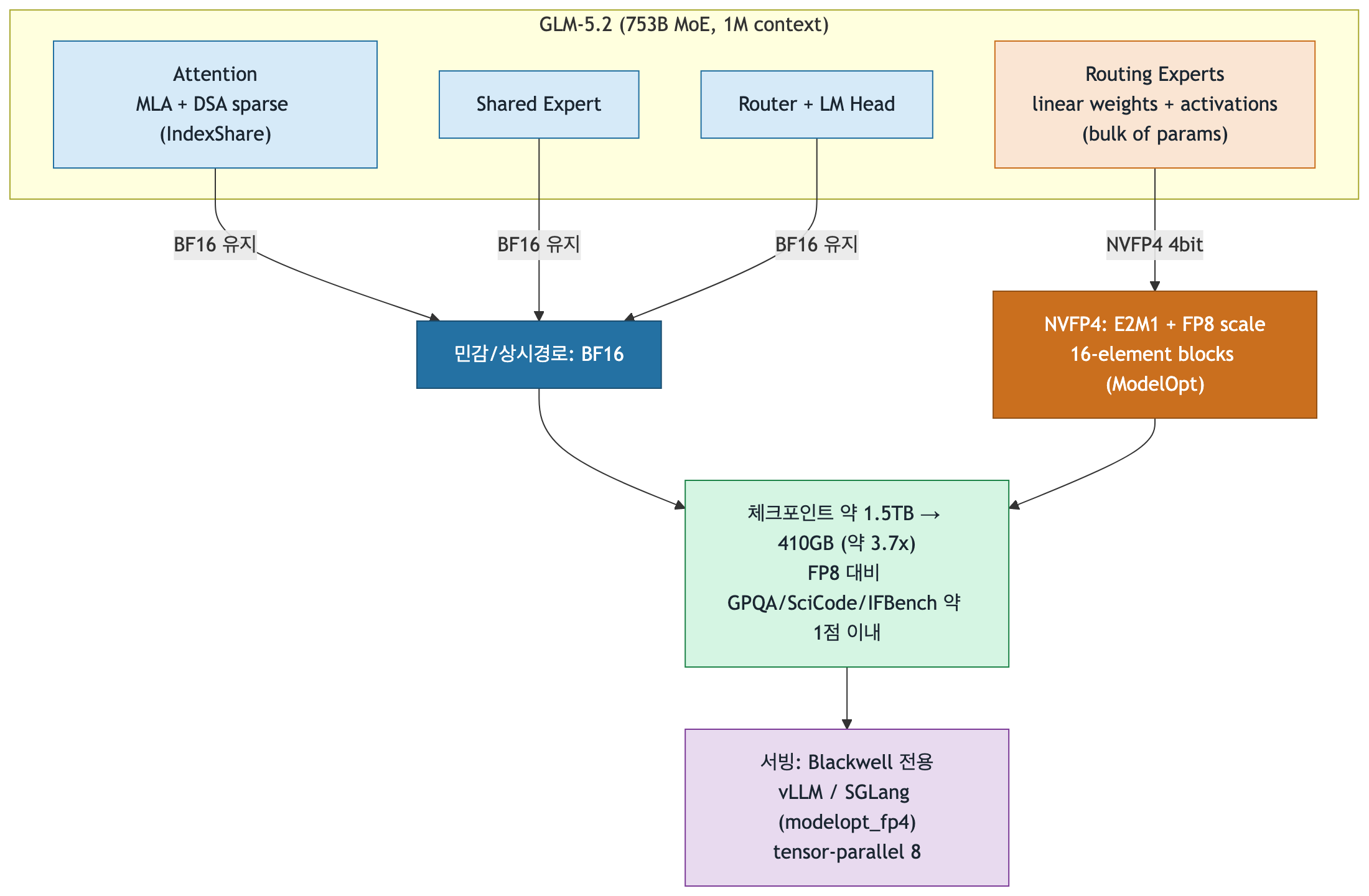 تُكمَّم فقط المعاملات الخطية لخبراء MoE الموجَّهين إلى NVFP4؛ ويبقى الخبير المشترك والانتباه بدقة BF16.
تُكمَّم فقط المعاملات الخطية لخبراء MoE الموجَّهين إلى NVFP4؛ ويبقى الخبير المشترك والانتباه بدقة BF16.
أهم قرار تصميمي في هذا النموذج هو “ما الذي لم يُكمَّم”. باقتباس بطاقة النموذج مباشرة: “تُكمَّم فقط أوزان وتنشيطات المعاملات الخطية داخل كتل المحوِّل في خبراء MoE. الخبير المشترك غير مكمَّم.” باختصار:
- مكمَّم إلى NVFP4 (4 بت): أوزان وتنشيطات المعاملات الخطية لخبراء MoE الموجَّهين. بما أن هنا تعيش معظم معاملات الـ 753B، يأتي تقريباً كل توفير الذاكرة من هنا.
- محفوظ بدقة BF16 (16 بت): الخبير المشترك، ومسار الانتباه المتناثر IndexShare. هذه يعبرها كل رمز، فلها أثر كبير على الدقة.
الاستراتيجية منطقية بسبب كيفية توزيع معاملات MoE. الخبراء الموجَّهون كثيرون ويهيمنون على إجمالي عدد المعاملات، لكن كل رمز يستخدم القليل منهم فقط. أما الخبير المشترك والانتباه فيحملان حصة أصغر من المعاملات لكن يعبرهما كل رمز. لذا فإن “4 بت بقوة حيث يوجد الكثير المستخدَم بتناثر، و16 بت بدقة حيث يوجد القليل لكنه يُستخدم دائماً” مقايضة سليمة تلتقط الذاكرة والدقة معاً. هذا التكميم الانتقائي هو السبب الجذري لبقاء جدول الدقة شبه خالٍ من الخسارة.
استخدمت المعايرة (calibration) مجموعات بيانات عائلة Nemotron من NVIDIA. تسمّي بطاقة النموذج Nemotron-SFT-Instruction-Following-Chat-v2 وNemotron-Science-v1 وNemotron-Competitive-Programming-v1 وNemotron-SFT-Agentic-v2 وNemotron-Math-v2 وNemotron-SFT-SWE-v2 وNemotron-SFT-Multilingual-v1 كبيانات معايرة. المزيج يشمل الاستدلال والعلوم والبرمجة والوكلاء والرياضيات ومتعدد اللغات، بما يتماشى مع طبيعة معايير التقييم.
القياسات المنشورة: الدقة مقابل FP8
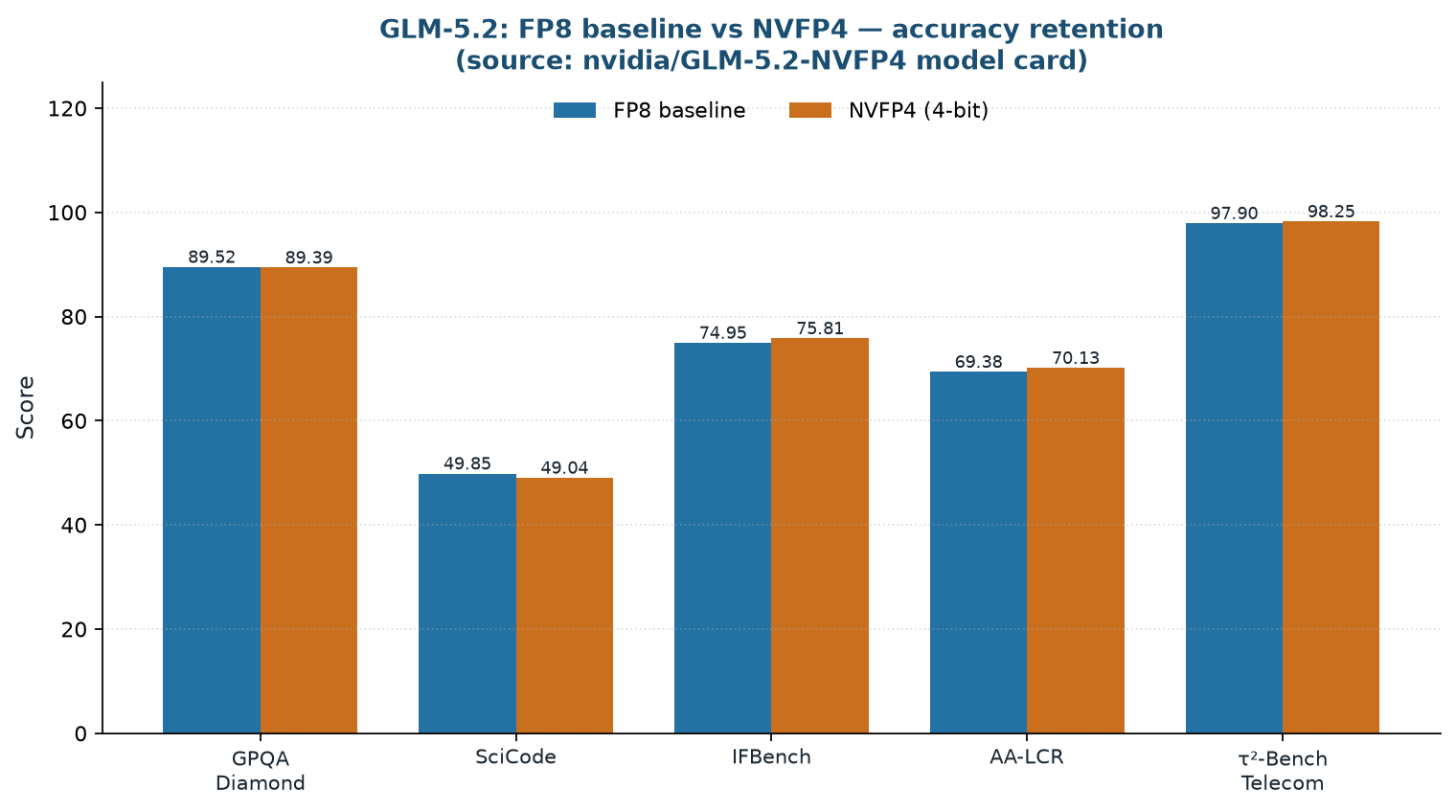 قياسات عامة من بطاقة نموذج nvidia/GLM-5.2-NVFP4. خط الأساس هو GLM-5.2-FP8.
قياسات عامة من بطاقة نموذج nvidia/GLM-5.2-NVFP4. خط الأساس هو GLM-5.2-FP8.
المقارنة التي نشرتها NVIDIA في بطاقة النموذج أدناه. اللافت أن خط الأساس ليس BF16 بل GLM-5.2-FP8 المضغوط أصلاً. أي أن هذا هو السؤال الأصعب: “كم يخسر 4 بت مقارنة بنموذج خُفِّض أصلاً إلى 8 بت”، بدلاً من “مقارنة بالأصل غير المضغوط”.
| المعيار | خط الأساس (FP8) | NVFP4 |
|---|---|---|
| GPQA Diamond | 89.52 | 89.39 |
| SciCode | 49.85 | 49.04 |
| IFBench | 74.95 | 75.81 |
| AA-LCR | 69.38 | 70.13 |
| τ²-Bench Telecom | 97.9 | 98.25 |
كانت إعدادات القياس درجة حرارة 1.0 وtop_p 0.95، بحد أقصى للرموز الجديدة 100000 لـ GPQA Diamond و64000 للبقية. قِيس AA-LCR بـ SGLang؛ والبقية بـ vLLM. المعايير الخمسة تقيّم على التوالي الاستدلال العلمي بمستوى الدراسات العليا (GPQA Diamond، 448 سؤالاً)، والبرمجة العلمية (SciCode)، واتّباع التعليمات (IFBench)، واستذكار السياق الطويل (AA-LCR)، واستخدام الأدوات الوكيلي (τ²-Bench Telecom).
انخفض GPQA (−0.13) وSciCode (−0.81) قليلاً، بينما كان IFBench (+0.86) وAA-LCR (+0.75) وτ²-Bench Telecom (+0.35) أعلى فعلياً تحت NVFP4. قد يبدو تفوّق 4 بت على 8 بت غير بديهي، لكن فروقاً بهذا الحجم تُقرأ بأمان أكبر كضوضاء تباين أخذ العينات لا كخسارة تكميم. الرسالة الجوهرية أن “ضغط FP8 خطوة إضافية إلى 4 بت يُبقي الدقة ثابتة فعلياً”، وهي نتيجة مباشرة لاستراتيجية التكميم الانتقائي الموصوفة أعلاه.
النشر: vLLM وSGLang
يدعم هذا النموذج رسمياً بيئتي التشغيل SGLang وvLLM، ويتطلب عتاد NVIDIA Blackwell، ويعمل على Linux. لأن نوى موتّرات NVFP4 موجودة فقط في جيل Blackwell، فإن عدم القدرة على استخدام مسار 4 بت هذا مباشرة على وحدات GPU الأقدم قيد مهم. أمر الخدمة عبر SGLang الذي توفّره بطاقة النموذج هو:
pip install -U "transformers>=5.3.0" && \
python3 -m sglang.launch_server \
--model nvidia/GLM-5.2-NVFP4 \
--tensor-parallel-size 8 \
--quantization modelopt_fp4 \
--tool-call-parser glm47 \
--reasoning-parser glm45 \
--trust-remote-code \
--chunked-prefill-size 131072 \
--mem-fraction-static 0.80
بضع إشارات تستحق القراءة هنا. --tensor-parallel-size 8 يعني أن النموذج يفترض عُقدة من 8 وحدات GPU لا واحدة. --quantization modelopt_fp4 يخبر بيئة التشغيل بالتعرّف على صيغة NVFP4 التي أنتجها ModelOpt. --chunked-prefill-size 131072 يقسّم التعبئة المسبقة عند معالجة سياق المليون رمز لمنع قفزات الذاكرة، وهي قيمة تحكم الاستقرار في خدمة السياق الطويل. --tool-call-parser glm47 و--reasoning-parser glm45 يحلّلان صيغتَي استدعاء الأدوات ورموز الاستدلال لعائلة GLM، وهما يرتبطان مباشرة بأحمال العمل الوكيلية.
من ناحية الذاكرة، تقدير تقريبي: خدمة 753B بدقة BF16 تحتاج نحو 1.5 تيرابايت [تقديري]. بما أن الخبراء الموجَّهين يهيمنون على عدد المعاملات ويُنزَلون إلى 4 بت، تنخفض ذاكرة الأوزان الفعلية إلى نحو الثلث فتقع في نطاق قابل للتحميل على عُقدة واحدة بتوازٍ موتّري ثماني (تُبلِغ مرايا NVFP4 المجتمعية عن نحو 1.37 تيرابايت إلى 459 جيجابايت، أي نحو 3 أضعاف [تقديري]). لأن بطاقة النموذج لا تذكر الحجم الدقيق بالجيجابايت قبل التكميم وبعده، يحمل هذا الرقم علامة [تقديري]. ما لا لبس فيه أن أمر --tensor-parallel-size 8 نفسه يشير إلى أن “8 وحدات Blackwell يمكنها خدمة نموذج استدلال بحجم 753B بسياق مليون رمز”.
تطبيقه على منصة ThakiCloud السحابية لخدمات AI/ML على K8s
تشغّل ThakiCloud منصة متعددة المستأجرين تجدوِل وحدات GPU عبر Kueue على K8s وتخدم النماذج عبر vLLM. في هذه البيئة، يهمّ نموذج مكمَّم مسبقاً من الطراز الرائد مثل nvidia/GLM-5.2-NVFP4 بثلاث طرق.
أولاً، يتّسع نطاق مرشّحي الخدمة. يُستبعَد نموذج استدلال من فئة 753B عادةً مبكراً من النظر في الاستضافة الذاتية، لكن إذا جعل تكميم 4 بت الأوزان مع هامش KV تناسب عُقدة Blackwell واحدة بـ 8 وحدات GPU، تصبح الخدمة الذاتية داخل المؤسسة خياراً واقعياً. باستخدام ResourceFlavor وClusterQueue في Kueue لتخصيص تجمّع عُقد Blackwell لاستدلال NVFP4، يتحوّل هامش الذاكرة المكتسب عبر التكميم مباشرة إلى عدد المستأجرين المخدومين معاً. بالنسبة للعملاء الذين لا يستطيعون إرسال البيانات إلى واجهات برمجية خارجية، خصوصاً القطاع العام والمالية حيث تُشترَط الاستضافة الذاتية وسيادة البيانات، فإن إبقاء الاستدلال الرائد داخلياً ميزة تنافسية بحد ذاتها.
ثانياً، لست مضطراً لتشغيل خط أنابيب التكميم بنفسك. معايرة وتكميم 753B بـ ModelOpt يتطلبان وقت GPU وهندسة كبيرين. إذا أمكننا أخذ نموذج معتمَد من NVIDIA ووضعه مباشرة على vLLM/SGLang، يمكننا تركيز الموارد على التوجيه متعدد المستأجرين والتوسّع التلقائي ومراقبة التكلفة بدلاً من التحقق من التكميم. ومع ذلك، يحوي نظام مهارات ThakiCloud بالفعل سير عمل داخلياً يكمّم عائلة Qwen3-MoE إلى NVFP4، لذا فإن الوصفة التي طبّقتها NVIDIA على GLM-5.2، أي “الخبراء إلى 4 بت، الخبير المشترك والانتباه بـ BF16”، تصبح نمطاً عاماً يمكننا اقتباسه مباشرة عند تكميم نماذج مجال العملاء بأنفسنا.
ثالثاً، يستحق التكميم الانتقائي الإدراج في معايير اعتماد النماذج لدينا. المبدأ الذي أظهره هذا النموذج، “بقوة حيث يوجد الكثير المتناثر، وبتحفّظ حيث يُستخدم دائماً”، ينطبق كما هو عند تكميم نماذج MoE أخرى داخلياً. بدلاً من سحق الكل ببساطة إلى 4 بت، يمكن أن يصبح الحفاظ على الخبير المشترك والانتباه بنداً في بوابة اعتماد النماذج. غير أن قيد Blackwell-only مرتبط مباشرة بتكوين تجمّع GPU لدينا، لذا يجب أن تذكر خارطة طريق الاعتماد أن استخدام مسار NVFP4 يفترض تأمين عُقد Blackwell.
القيود والاعتراضات
أكبر قيد هو التبعية للعتاد. يفترض مسار NVFP4 بـ 4 بت نوى موتّرات Blackwell، لذا فإن البيئات التي تملك أجيالاً أقدم فقط مثل Hopper (H100/H200) لا يمكنها تحقيق فوائد هذا النموذج كما هي. سردية “4 بت تجعله رخيصاً” تصحّ فقط عندما تكون عُقد Blackwell مؤمَّنة أو مخطَّطة، وهي فعلاً تفترض إنفاقاً رأسمالياً جديداً.
ثانياً، نطاق المعايير. جدول الدقة في بطاقة النموذج محصور في خمسة معايير، جميعها قريبة من مهام الاستدلال والبرمجة والوكلاء باللغة الإنجليزية. الجودة الواقعية متعددة اللغات بما فيها الكورية، واستقرار الاستذكار عند ملء سياق المليون رمز حتى آخره، لا يمكن استنتاجهما من الجدول العام وحده. تقييم منفصل على بيانات مجالنا يقيس التراجع مقابل BF16/FP8 ضروري قبل الاعتماد.
ثالثاً، عدم يقين أرقام الذاكرة. كما ذُكر، لا تنشر بطاقة النموذج الحجم الدقيق بالجيجابايت قبل التكميم وبعده. تقدير الذاكرة في هذه المقالة محسوب عكسياً من عدد المعاملات ونطاق التكميم، لذا في النشر الفعلي، إضافة ذاكرة KV ومخازن التعبئة المسبقة للمليون رمز تجعل الذاكرة الفعلية لكل عُقدة أكبر من تقدير الأوزان وحدها. يجب أن يبني التخطيط التشغيلي على ذروة الذاكرة لا على ذاكرة الأوزان.
رابعاً، وجها التكميم الانتقائي. إبقاء الخبير المشترك والانتباه بـ BF16 حمى الدقة، لكنه أيضاً يجعل توفير الذاكرة أصغر من “الكل بـ 4 بت”. أي أن هذا النموذج اختار “ضغطاً يحمي الدقة” لا “أقصى ضغط”. لبيئة تكلفة قصوى تهدف إلى تشغيله على وحدة GPU واحدة لمحطة عمل، تناسب مقايضة GGUF بـ 1 بت الأكثر جرأة، بجودة أدنى، بشكل أفضل.
باختصار، nvidia/GLM-5.2-NVFP4 حالة لإنزال نموذج استدلال MoE رائد بحجم 753B إلى 4 بت دون خسارة دقة، ما يجعل الخدمة الذاتية على عُقدة Blackwell بـ 8 وحدات GPU خياراً واقعياً. من منظور ThakiCloud، يضيف ورقة أخرى لتقديم الاستدلال الرائد للعملاء ذوي متطلبات الاستضافة الداخلية وسيادة البيانات، ومناسبة لإدراج المبدأ العام “التكميم الانتقائي” في معايير اعتماد النماذج. لكن ذلك الباب لا يُفتَح إلا بمفتاح Blackwell.