وكيل يتخيّل البيئة أولاً: تحليل معمّق لنموذج عالم اللغة Qwen-AgentWorld
⏱️ وقت القراءة المتوقع: 14 دقيقة
📄 المراجعة المتعمقة الكاملة (DOCX): نزّل المراجعة التفصيلية من Google Drive.
نظرة عامة
تعمل معظم الوكلاء اليوم وفق أسلوب موحّد: تتلقى مهمة، تحاول تنفيذها، ثم تصحّح أخطاءها. إنها بنية تقوم على التجربة والخطأ في البيئة الحقيقية. هذا الأسلوب بديهي، لكنه مكلف. فإن كانت البيئة طرفية حقيقية أو متصفحاً حقيقياً أو جهاز Android فعلياً، فإن كل محاولة تستتبع تكاليف حقيقية ومخاطر حقيقية.
في الرابع والعشرين من يونيو 2026، كشف فريق Qwen في Alibaba عن Qwen-AgentWorld، وهو نهج يقلب هذه المعادلة رأساً على عقب. بدلاً من تدريب الوكيل على “أداء أفضل”، يُدرَّب النموذج على التنبؤ بالبيئة ذاتها؛ أي أنه يرسم في ذهنه ما ستؤول إليه حالة البيئة التالية انطلاقاً من الملاحظة الراهنة والفعل المُتّخذ، تماماً كلاعب الشطرنج الذي يقرأ ثلاثة أشواط مقبلة قبل أن يحرك قطعة. هذا هو نموذج عالم اللغة (Language World Model — LWM).
نحن في ThakiCloud ندير عبء عمل وكلاء متعدد المستأجرين على منصة AI/ML-SaaS المبنية على Kubernetes. ولأن الوكلاء تعمل فوق بيئات وأدوات وقيود مختلفة لكل عميل، فإن “كيفية التعامل مع البيئة” ليست موضوعاً بحثياً مجرداً بالنسبة لنا، بل إشكالية تمسّ تكاليف التشغيل مباشرة. لذا حللنا هذا النموذج اعتماداً على التقرير التقني الرسمي (arXiv 2606.24597) والمواد المنشورة على GitHub، ورصدنا أين يناسب منصتنا وما ينبغي أخذه بحذر.
ما هو Qwen-AgentWorld؟
نموذج العالم هو نموذج يتنبأ بديناميات البيئة انطلاقاً من الملاحظة الراهنة والفعل المُتّخذ. وهو مفهوم آلية معرفية جوهرية للاستدلال والتخطيط درسه الباحثون منذ أمد بعيد، غير أنه ظل في الغالب حبيس بيئات بصرية ومادية كالروبوتات والألعاب. أما Qwen-AgentWorld فيختلف في كونه يُجسّد نموذج العالم فوق نموذج لغوي، عبر استدلال سلسلة التفكير (chain-of-thought).
السمة الجوهرية هي محاكاة 7 نطاقات بنموذج واحد: MCP، وSearch، وTerminal، وSWE، وWeb، وOS، وAndroid — سبع بيئات تفاعل للوكلاء يعالجها نموذج واحد. فإذا أُعطي النموذج موجّهاً للنظام يقول “محاكاة بيئة طرفية Linux” وأمراً من المستخدم، فإنه يتنبأ بالمخرجات التي ستنتجها الطرفية دون تنفيذ الأمر فعلياً.
تصميم جوهري آخر هو كون النموذج نموذج عالم أصيل (Native World Model). فنمذجة البيئة ليست ميزة أُلحقت في نهاية التدريب، بل كانت هدفاً تدريبياً منذ المرحلة الأولى (CPT). اعتمد النموذج على أكثر من عشرة ملايين مسار تفاعل من العالم الحقيقي لغرس “قدرة نمذجة البيئة” من الصفر. بعبارة المؤلفين: دُرِّبت النماذج اللغوية الكبيرة على التصرف الجيد في البيئات، لكنها لم تُدرَّب قط على نمذجة البيئات ذاتها — وهذا هو الفراغ الذي يسعى Qwen-AgentWorld إلى ملئه.
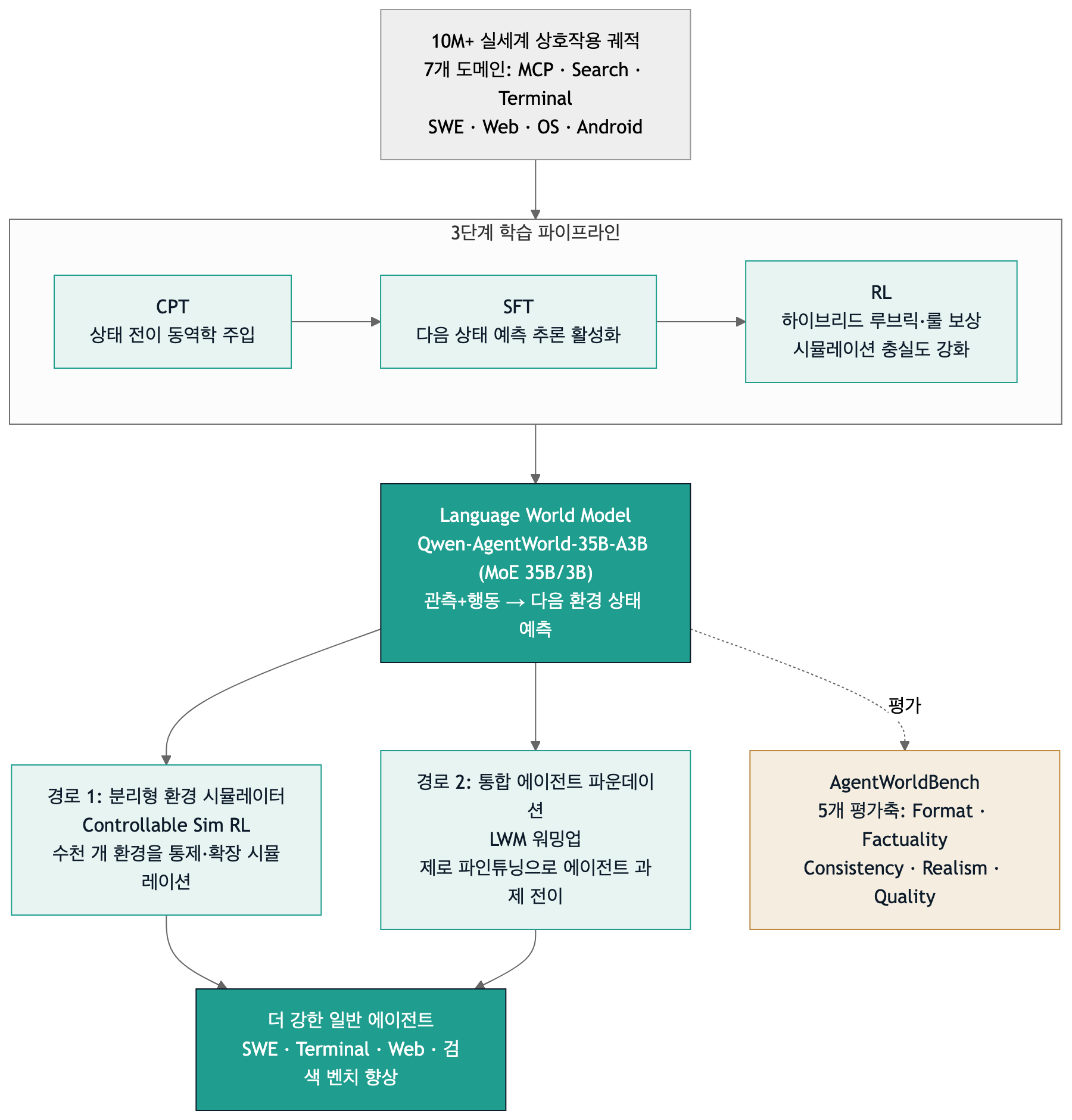 مخطط يلخّص خط أنابيب التدريب ثلاثي المراحل (CPT/SFT/RL) ومساري الاستخدام اللاحق لـ Qwen-AgentWorld.
مخطط يلخّص خط أنابيب التدريب ثلاثي المراحل (CPT/SFT/RL) ومساري الاستخدام اللاحق لـ Qwen-AgentWorld.
خط أنابيب التدريب ثلاثي المراحل
يُبنى Qwen-AgentWorld عبر ثلاث مراحل تدريب ذات أدوار متمايزة بوضوح:
- CPT (Continual Pre-Training): يغرس قدرة النمذجة العالمية العامة من ديناميات انتقال الحالة وكوربوس متخصص معزَّز. هذه هي المرحلة التي تُزرع فيها المعرفة الأساسية بكيفية استجابة البيئة للأفعال.
- SFT (Supervised Fine-Tuning): يُفعِّل استدلال التنبؤ بالحالة التالية (next-state-prediction). لا يقتصر الأمر على إصابة الحالة التالية، بل يجعل النموذج يكشف عن سبب تلك الحالة عبر سلسلة التفكير.
- RL (Reinforcement Learning): يرفع دقة المحاكاة عبر مكافآت هجينة قائمة على مسطرة تقييم وقواعد. يُضبط النموذج باستخدام إشارات مكافأة تراعي التنسيق والواقعية والاتساق.
النموذج المنشور هو Qwen-AgentWorld-35B-A3B، بنية MoE (Mixture-of-Experts) تُنشَّط منها 3 مليارات معامل من أصل 35 مليار، مع نافذة سياق تبلغ 256K. يرد في التقرير التقني أيضاً Qwen-AgentWorld-397B-A17B الأكبر حجماً، غير أن أوزان 397B لم تُنشر. لتحديد نطاق ما هو متاح بدقة: أوزان النموذج 35B-A3B ومعيار AgentWorldBench متاحان بموجب رخصة Apache-2.0، أما 397B فيحضر في النتائج داخل التقرير فحسب. وهو تمييز ينبغي استحضاره حين تُقرأ تصريحات من قبيل “جرّبه الآن محلياً”.
المعيار: AgentWorldBench
كيف يُقيَّم نموذج عالم اللغة؟ أطلق فريق Qwen معياراً مخصصاً هو AgentWorldBench. يضم تفاعلات حقيقية أنتجتها خمسة نماذج حدودية عبر تسعة معايير قائمة، ويُقيّم الملاحظات البيئية المتنبَّأ بها على خمسة محاور: Format (التنسيق)، وFactuality (الواقعية)، وConsistency (الاتساق)، وRealism (المصداقية)، وQuality (الجودة). يستعين التقييم بنموذج حكم منفصل (gpt-5.2).
فيما يلي نتائج الدرجة الإجمالية (Overall) وهي متوسط درجات المحاور الخمسة الموحَّدة (0-100) عبر النطاقات، كما نُشرت في المستودع الرسمي على GitHub:
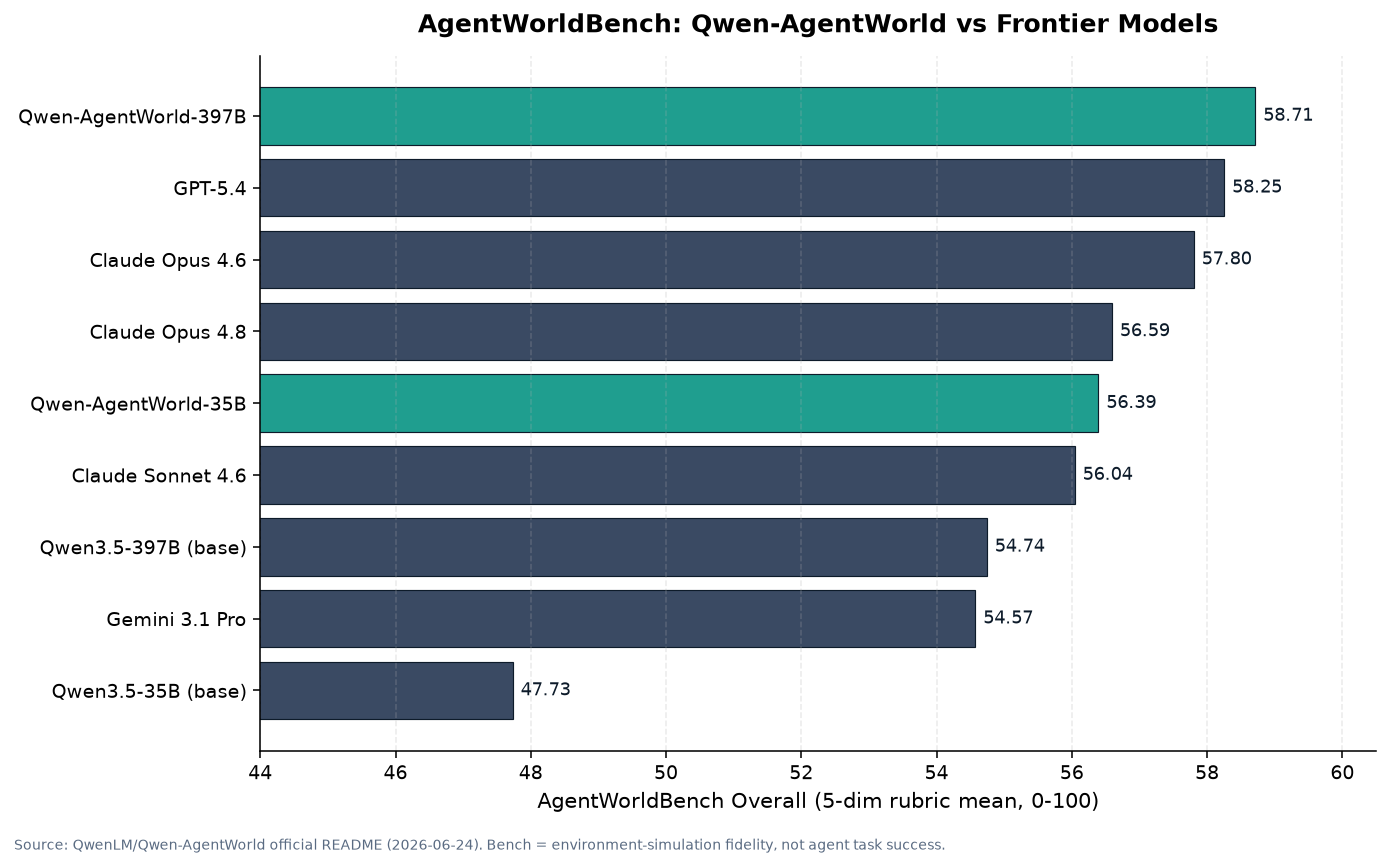 الدرجة الإجمالية في AgentWorldBench. تقيس دقة محاكاة البيئة، وهي مؤشر مختلف عن معدل نجاح الوكيل في إنجاز المهام. المصدر: QwenLM/Qwen-AgentWorld README الرسمي.
الدرجة الإجمالية في AgentWorldBench. تقيس دقة محاكاة البيئة، وهي مؤشر مختلف عن معدل نجاح الوكيل في إنجاز المهام. المصدر: QwenLM/Qwen-AgentWorld README الرسمي.
إليك الأرقام:
- Qwen-AgentWorld-397B-A17B: 58.71، المرتبة الأولى عالمياً، متجاوزاً GPT-5.4 (58.25) وClaude Opus 4.8 (56.59) وGemini 3.1 Pro (54.57).
- Qwen-AgentWorld-35B-A3B: 56.39، يتفوق على نموذج الأساس Qwen3.5-35B-A3B (47.73) بفارق +8.66. هذا تحسّن يزيد على ثماني نقاط بفضل تدريب نموذج العالم وحده.
ثمة نقطتان ينبغي التوضيح بشأنهما. أولاً: ما يقيسه هذا المعيار ليس “قدرة الوكيل على حل المهام” بل “دقة تنبؤ النموذج بالحالة البيئية التالية”، أي دقته بوصفه محاكياً. ثانياً: الذي تجاوز النماذج الحدودية هو 397B غير المنشور، أما 35B المتاح للتنزيل فدرجته 56.39، أي أدنى قليلاً من GPT-5.4 وClaude Opus 4.8. التحسّن لافت، لكن تبسيط القول بأن “النموذج المفتوح تغلّب على جميع النماذج المغلقة” غير دقيق.
مساران لجعل نموذج العالم يُقوّي الوكلاء
لا يقف Qwen-AgentWorld عند حد المحاكاة؛ فهو يقترح مساريْن لجعل نموذج العالم يُقوّي الوكلاء.
المسار الأول: محاكي البيئة المنفصل (Controllable Sim RL). يستخدم نموذج العالم بديلاً عن البيئة لتدريب الوكلاء بالتعلم التعزيزي. بدلاً من تشغيل آلاف البيئات الحقيقية، يُنشئ النموذج بيئات محاكاة قابلة للضبط والتوسع. وفق التقرير، حين طُبِّق Sim RL على 4000 بيئة خارج التوزيع (OOD) من OpenClaw، ارتفعت النتائج من الخط الأساسي (65.4 / 47.9) إلى 69.7 / 55.0 باستخدام Qwen-AgentWorld-397B-A17B بيئةً محاكِية. والأجدر بالاهتمام أن المحاكاة “المضبوطة” تفوّقت على غير المضبوطة؛ ففي أحد الإعدادات سجّل Sim RL المضبوط تحسناً +16.29 / +10.49 قياساً بخط أساس SFT، أي نتائج أفضل من التدريب على البيئة الحقيقية وحدها.
المسار الثاني: أساس الوكيل الموحّد (LWM Warmup). يستخدم تدريب نموذج العالم نوعاً من الإحماء. نموذج أُجري له LWM RL Warmup على مسارات أحادية الدور وغير وكيلية ينتقل تلقائياً إلى مهام الوكلاء متعددة الأدوار ومتعددة مكالمات الأدوات، دون تدريب وكيلي منفصل. الادعاء الجوهري هو أن معرفة التنبؤ تنتقل ذاتياً. حين أُضيف LWM RL إلى Qwen3.5-35B-A3B-SFT، تحسّنت النتائج عبر سبعة معايير:
| المعيار | خط أساس SFT | + LWM RL | التحسّن |
|---|---|---|---|
| Terminal-Bench 2.0 | 33.25 | 39.55 | +6.30 |
| SWE-Bench Verified | 64.47 | 67.86 | +3.39 |
| SWE-Bench Pro | 42.18 | 47.42 | +5.24 |
| WideSearch F1 Item | 33.38 | 46.17 | +12.79 |
| Claw-Eval | 53.60 | 64.88 | +11.28 |
| QwenClawBench | 39.76 | 49.43 | +9.67 |
| BFCL v4 | 62.29 | 71.25 | +8.96 |
ظهر التحسّن في ثلاثة معايير خارج النطاق تماماً. تعلّم التنبؤ بالبيئة يُعين على تعلّم التصرف فيها — نتيجة تبدو مضادة للحدس بعض الشيء.
كيف تشغّله فعلياً؟
يمكن خدمة النموذج 35B-A3B المنشور مباشرة عبر أطر استدلال كـ SGLang وvLLM. الأوامر التي يقترحها المستودع الرسمي:
# الخدمة عبر vLLM
vllm serve Qwen/Qwen-AgentWorld-35B-A3B
# أو عبر SGLang
python -m sglang.launch_server --model-path Qwen/Qwen-AgentWorld-35B-A3B
يتبنى النموذج واجهة OpenAI المتوافقة كنماذج الدردشة المعتادة، مع ميزة تمييزية: يُحدَّد الموجّه النظامي بـ”أي بيئة يُراد محاكاتها”.
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
messages = [
{
"role": "system",
"content": "You are a language world model simulating a Linux terminal environment. "
"Given the user's command, predict the terminal output.",
},
{"role": "user", "content": "ls -la /var/log"},
]
تقييم AgentWorldBench متاح أيضاً؛ يمكن تنزيل ملفات JSONL الخاصة بكل نطاق (mcp_test.jsonl، terminal_test.jsonl، إلخ) وإعادة إنتاج التقييم الخماسي المحاور بشكل مستقل. لكن تجدر الإشارة إلى أن 35B-A3B، رغم بنيته MoE، يتطلب ذاكرة GPU غير يسيرة، مما يستدعي تسريعاً ملائماً وتوازي تنسوري لبيئة الإنتاج. في هذا التحليل لم نُجرِ استدلالاً على GPU خاصة بنا؛ اقتصرنا على الأرقام المنشورة رسمياً في التقرير والمستودع دون قياسات ذاتية.
التطبيق على منصة ThakiCloud AI/ML SaaS لـ Kubernetes
نُجدوِل في ThakiCloud أعباء عمل GPU عبر Kueue فوق Kubernetes، ونُقدّم استدلالاً متعدد المستأجرين عبر vLLM، وندير وكلاء معزولة لكل عميل. من هذه الزاوية، يطرح Qwen-AgentWorld ثلاثة دلالات:
أولاً: محاكاة البيئة قد تُعيد رسم هيكلة تكاليف تدريب الوكلاء. لتطبيق التعلم التعزيزي على وكلاء في بيئات العملاء يستلزم تشغيل آلاف البيئات الحقيقية، مما يعني إدارة بنية تحتية بيئية كاملة: حشود متصفحات، وطرفيات محمية بحاوية رمل، ومحاكيات موبايل — فضلاً عن وحدات GPU. إذا حلّ نموذج العالم محل تلك البيئات، أمكن ضغط حلقة التعلم التعزيزي إلى نوع واحد من خدمات النماذج. Sim RL المضبوط عبر قائمة انتظار Kueue يُخفّض تعقيد التشغيل كثيراً في بيئة متعددة المستأجرين.
ثانياً: التوافق مع الاستضافة الذاتية وبيئات الاستخدام الداخلي. ترخيص Apache-2.0 لنموذج 35B-A3B يُجيز الاستخدام التجاري والاستضافة الذاتية دون قيود. بالنسبة لعملاء في القطاعين الحكومي والمالي حيث لا تستطيع البيانات مغادرة الحدود، يتيح هذا خيار إسكان محاكي البيئة الخاص بالعميل داخل مجموعتنا بدلاً من الاعتماد على واجهات API خارجية. تغليف البيئة في نموذج يُتيح تدريب الوكلاء وتقييمهم دون كشف البيئات التشغيلية الحساسة للخارج.
ثالثاً: القيمة بوصفه بنية تحتية تقييمية. التقييم الخماسي المحاور لـ AgentWorldBench (التنسيق، الواقعية، الاتساق، المصداقية، الجودة) يُشكّل بحد ذاته إطاراً جيداً لبوابة جودة وكلاء متعددي المستأجرين. يوفر محاور قابلة للقياس الكمي لتصفية الوكلاء قبل نشرها لدى العملاء بناءً على مدى دقة فهمهم للبيئة. حتى من دون خدمة 397B محلياً، يُعدّ تصميم التقييم هذا ونموذج المحاكاة 35B المتاح أصولاً قابلة للدمج فوراً في خطوط تحقق داخلية.
بالطبع، هذا خارطة طريق تدريجية لا حلاً جاهزاً. استبدال بيئات جميع العملاء بنماذج عالم ليس أمراً يتم بين يوم وليلة، وفي النطاقات التي تقل فيها دقة المحاكاة ستبقى الحاجة إلى التدريب على بيئات حقيقية قائمة. غير أن منطق “نموذج يُنشئ البيئة” يُلامس بدقة إشكاليات التكلفة والعزل في منصة وكلاء متعددة المستأجرين، مما يستحق متابعتنا الدائمة.
القيود والحجج المضادة
أول ما ينبغي الإشارة إليه هو الفجوة بين التصريحات الترويجية ونطاق ما هو منشور فعلاً. تناقلت وسائل التواصل الاجتماعي عبارات من قبيل “أطلقت Alibaba نموذجاً يتفوق على جميع النماذج المغلقة، جرّبه الآن محلياً”. لكن الذي تفوّق على النماذج الحدودية هو 397B غير المنشور، أما 35B القابل للتنزيل فأداؤه أدنى قليلاً من GPT-5.4 وClaude Opus 4.8. “التفوّق” و”النشر” لا يشيران إلى نفس النموذج — ينبغي توضيح ذلك بجلاء.
ثانياً: طبيعة المعيار. يقيس AgentWorldBench دقة التنبؤ البيئي لا معدل نجاح الوكيل في إنجاز المهام. التنبؤ الدقيق بالبيئة لا يضمن مباشرةً حل المهام بكفاءة في تلك البيئة. نتائج انتقال المسار الثاني تقدّم بعض الدليل على هذه الصلة، لكن مدى التعميم يستدعي مزيداً من التحقق.
ثالثاً: قيود التقييم الذاتي التصميم والتحكيم الذاتي. فريق البحث الذي أنشأ المعيار هو ذاته من صمّم محاور التقييم واختار نموذج الحكم (gpt-5.2). هذا ليس عيباً بالضرورة، لكن الحكمة تقتضي قراءة الأرقام المطلقة بحذر حتى تتراكم عمليات إعادة الإنتاج المستقلة من أطراف ثالثة.
رابعاً: مخاطر الهلوسة في المحاكي. إذا أنتج نموذج العالم حالة بيئية قابلة للتصديق لكنها خاطئة، فإن الوكيل المُدرَّب عليها يتعلم قواعد لا وجود لها. القابلية للضبط ميزة وخطر في آنٍ واحد. التدريب الذي يعتمد حصراً على المحاكاة دون معايرة دورية مع بيئات حقيقية قد يُصبح هشاً أمام انزياح التوزيع.
بعد كل هذا، يبقى التوجّه القاضي بـ”جعل النموذج يفهم البيئة قبل أن يتصرف فيها” توجهاً جديداً وواعداً. والأهم أن نموذج 35B والمعيار مفتوحان بموجب Apache-2.0، فباب التحقق والتجريب ليس موصداً. اقتلع العناوين المبالغ فيها جانباً، وما تبقى هو بحث عملي تماماً لمنصات وكلاء متعددة المستأجرين.
المصادر
- التقرير التقني لـ Qwen-AgentWorld (arXiv): arxiv.org/abs/2606.24597
- المدونة الرسمية: qwen.ai/blog?id=qwen-agentworld
- GitHub: github.com/QwenLM/Qwen-AgentWorld
- النموذج والمعيار على Hugging Face: huggingface.co/collections/Qwen/qwen-agentworld
- الإعلان الرسمي لـ Alibaba Qwen على X: x.com/Alibaba_Qwen/status/2069720365442719867
📄 المراجعة المتعمقة الكاملة (DOCX): نزّل المراجعة التفصيلية من Google Drive.