Treating Skills Like Software: A Hands-On Verification of yao-meta-skill v1.1.0
 A conceptual view of treating skills not as one-off prompts but as reusable assets carrying versioning, verification, and governance.
A conceptual view of treating skills not as one-off prompts but as reusable assets carrying versioning, verification, and governance.
Overview
In agent environments like Claude Code, Cursor, and Codex CLI, a Skill is no longer just a bundle of prompts. It is closer to a capability product that packages repetitive work for reuse across multiple harnesses. But as skills multiply, three problems grow at once: quality variance, trigger collisions, and context cost. yao-meta-skill, an open-source project that went viral after Chinese influencer @vista8 (~113K followers) recommended it as “more powerful than Anthropic’s official Skill-creator,” takes direct aim at this.
YAO stands for “Yielding AI Outcomes,” and the repository describes itself as “a rigorous engineering, evaluation, governance, and portability system for reusable agent skills.” Rather than take that claim at face value, I cloned it into a ThakiCloud workspace and actually ran the local verification gates the repo ships with. This is an implementation report that dissects yao-meta-skill’s structure from those measured results and considers what we can borrow for our own .claude/skills operations.
What This Tool Is
yao-meta-skill is a “skill that makes skills” — a meta-skill. It takes repetitive work such as workflow notes, prompt sets, conversation transcripts, runbooks, and document patterns, and converts them into a verifiable skill package. Its core design rests on three pillars.
First, Skill IR (Intermediate Representation). Intent, triggers, inputs, outputs, boundaries, references, and expected artifacts are first described in a platform-neutral intermediate representation. Target compilers and adapters then convert this IR into five targets: OpenAI, Claude, generic agent skills, Agent-Skills-compatible packages, and VS Code-oriented workflows. Describing a skill once and compiling it to many environments precisely targets the burden of maintaining the same skill twice across Claude Code and Cursor.
Second, the Output Eval Lab. It is a layer that verifies skill output quality with data: trigger checks, output assertions, execution evidence, timing and token evidence, benchmark reproducibility, and blind-review packs. The fact that code actually verifies, instead of the model merely claiming “it worked,” is striking.
Third, Review Studio 2.0. It consolidates intent, triggers, output evaluation, context cost, runtime checks, and release evidence into a single HTML gate page — a checkpoint that fixes exactly what a skill must pass before release.
The license is MIT, and the manifest declares a maturity tier of “governed,” a lifecycle stage of “library,” and a review cadence of “quarterly.” The intent to manage skills like code — with versions, tiers, and review cadences — is visible at the metadata level itself.
 Repetitive-work inputs pass through Skill IR, compile to multiple platforms, then clear the Output Eval Lab and Review Studio gates to finish as release evidence.
Repetitive-work inputs pass through Skill IR, compile to multiple platforms, then clear the Output Eval Lab and Review Studio gates to finish as release evidence.
Installation and Integration (Real Commands)
Verification ran in an isolated sandbox. Per our rules, the worktree lived outside the repository and was cleaned up afterward.
# 1) Clone the external repo
git clone --depth 1 https://github.com/yaojingang/yao-meta-skill
# 2) Install the minimal dependency into the shared .venv (python-runtime rule)
VIRTUAL_ENV="$REPO_ROOT/.venv" uv pip install "PyYAML==6.0.3"
The dependencies are surprisingly light. The CI requirements (requirements-ci.txt) were a single line: PyYAML==6.0.3. This means the verification tooling is built around the pure-Python standard library rather than heavy runtimes — a good sign for slotting it into a CI pipeline.
The actual composition I measured right after cloning was: 632 tracked files, 77 tests, 29 evals, 10 skill-atlas entries, 3 schemas, and 2 templates. This is not a single “skill” but closer to a small factory that produces, verifies, and governs skills.
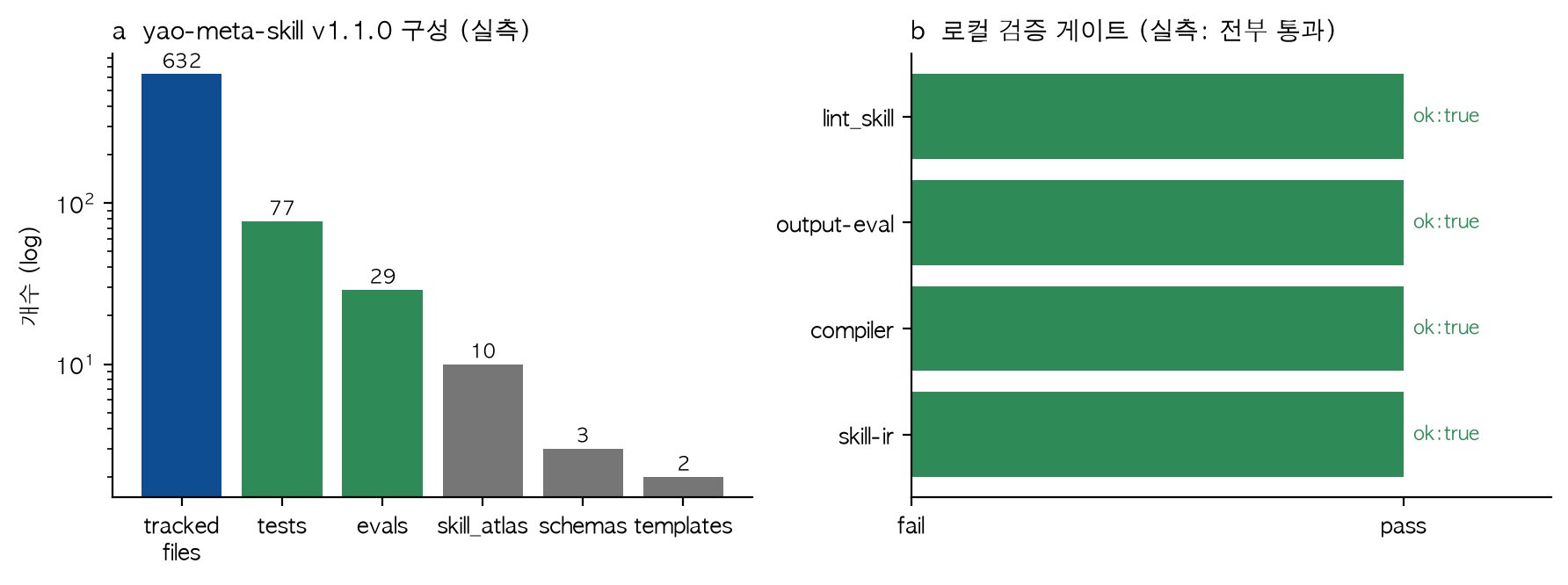 Left: the repository’s measured composition (log scale). Right: all four local verification gates passing.
Left: the repository’s measured composition (log scale). Right: all four local verification gates passing.
Real Verification Results
The Makefile defined more than 25 verification targets. I actually ran four of them — skill IR, compiler, output eval, and lint — and captured the results.
make skill-ir-check
# python3 tests/verify_skill_ir.py -> {"ok": true}
# python3 tests/verify_skill_ir_paths.py -> {"ok": true}
make compiler-check
# python3 tests/verify_compile_skill.py -> {"ok": true}
make output-eval-check
# python3 tests/verify_output_eval_lab.py -> {"ok": true}
python3 scripts/lint_skill.py ./ # against the bundled SKILL.md
# {"ok": true, "failures": [], "warnings": []}
All four gates passed with ok: true, and lint reported zero failures and zero warnings. These numbers were captured by running it myself, not quoted from elsewhere. What is notable is that the verification output is deterministic JSON in the form {"ok": true} rather than prose. This is a machine-readable format an upstream pipeline can gate on automatically — the same direction as ThakiCloud’s own principle that “format is owned by code.”
One limitation also surfaced through measurement. lint_skill.py raised a usage error when called without arguments and required an explicit skill directory. The context-sizing script (context_sizer.py) returned a token estimate of 0 on some paths, appearing sensitive to how arguments are passed. In short, “the make targets work well, but calling individual scripts directly requires matching the interface precisely” is a practical caveat.
Application and Implications for the ThakiCloud K8s AI/ML SaaS Platform
ThakiCloud already operates over a thousand in-house skills and rules. At this scale, the biggest cost is not the skills themselves but the context tax every indexed skill pays each session, plus trigger collisions. There are three points worth borrowing from yao-meta-skill.
First, partial adoption of the Skill IR idea. Instead of maintaining in-house skills twice across Claude Code and Cursor, describing intent, triggers, and boundaries neutrally once and compiling per environment reduces the management surface. Full adoption may be overkill, but structuring new skills’ descriptions and triggers like an IR schema already helps.
Second, borrowing the Output Eval Lab style of gating. We already have editorial gates and deterministic verification scripts, but trigger evaluation — checking with data whether a trigger fires as intended — is relatively weak. This pattern is directly usable for reducing skill-router distractor noise.
Third, a Review Studio-style single release gate. A checkpoint that confirms intent, triggers, context cost, and runtime on one page before merging a new skill is philosophically isomorphic to the deployment gates (ArgoCD, Kueue) of an AI/ML SaaS running on K8s. Just as we gate code deployment, we gate skill deployment.
Limitations and Counterarguments
To avoid a one-sided endorsement, here are the counterarguments.
First, the “more powerful than the official” claim traces back to an influencer recommendation. The repository structure and local verification are solid, but Anthropic’s official Skill-creator excels at fast, conversation-first creation loops — a different purpose. The two are complementary rather than competitive. The “more powerful” comparison is accurate only when scoped to building governed team assets.
Second, adoption cost. Bringing in a 632-file factory wholesale is overkill for a solo or small team. Selectively borrowing the core ideas (IR, trigger evaluation, single gate) is the realistic path.
Third, interface sensitivity. As measured above, individual scripts were sensitive to arguments and some metrics returned 0. When slotting into CI, wrap things at the make-target level and pin the interfaces of individual scripts.
In conclusion, yao-meta-skill is one of the most concrete open-source examples of “engineering skills like software.” Even without adopting all of it, any organization where skills become assets will find its design principles worth studying.
Sources
- yao-meta-skill (GitHub, MIT): github.com/yaojingang/yao-meta-skill
- Repository manifest and verification results: all numbers in this article were measured locally by cloning v1.1.0.