Connecting Claude Code to Self-Hosted Models with free-claude-code: A Real-World Test of a 17-Provider Routing Proxy
Overview
Claude Code is a powerful coding agent. However, because every request goes directly to the Anthropic API, it creates a constraint for organizations that need to control costs or keep data within their own boundaries. The recently trending free-claude-code project addresses this exact point. It is a proxy layer that intercepts Claude Code traffic and routes it to 17 different providers. It is an MIT-licensed project with 36.7k GitHub stars, 5.7k forks, and 712 commits.
The project’s marketing tagline is “Claude Code forever free.” The approach routes traffic to free or low-cost tier providers, and this framing is frankly overstated in some respects and sits in a gray area from a Terms of Service perspective. This article therefore focuses not on the “free” angle, but on what this tool means for organizations like ThakiCloud that serve their own models on Kubernetes and want to connect Claude Code to their own infrastructure. The key points are that code and prompts never leave the tenancy boundary, per-token cloud billing disappears, and no client-side modifications are needed because the endpoint is Anthropic-compatible.
Note: A previous article, “Routing Claude Code to In-House Models - claude-code-router,” focused on cost arbitrage between cloud models (glm, MiniMax, Kimi). This article is about a different tool (
free-claude-code), covering the connection to self-hosted backends (Ollama, vLLM) — not cloud models — and the deployment risks that surfaced in the process.
What This Tool Does
free-claude-code is a local proxy server that receives requests sent by Claude Code (and Codex). Its core feature is that it exactly mimics an Anthropic-compatible endpoint. From the client’s perspective, it is indistinguishable from the real Anthropic API, so the backend can be swapped without changing a single line of Claude Code.
The server is written in FastAPI and exposes the following endpoints:
/v1/messages- Anthropic Messages API compatible (the primary path for Claude Code)/v1/models- Model listing/v1/responses- OpenAI Responses API compatible (for Codex; internally converted to Messages)
When a request arrives, a model router decides which provider to send it to, and a normalizer transforms thinking blocks, tool_calls, and error responses into the shape each client expects. Because response formats differ across providers, this normalization layer is where the real complexity lies.
To elaborate on why normalization is difficult: Claude Code assumes Anthropic’s own response structure. For instance, reasoning steps arrive as thinking blocks and tool calls as tool_use content blocks. DeepSeek, however, exports reasoning as a separate field, and OpenAI-compatible providers return tool calls as a tool_calls array. Even though they all mean “a tool was called,” the wire format differs in each case. The normalizer must absorb these differences and ensure Claude Code receives identically shaped responses regardless of which backend is used. The Codex path (/v1/responses) goes one step further, converting OpenAI Responses requests internally to Anthropic Messages before sharing the same router, normalizer, and provider adapters. This means protocol conversion happens in both directions — the key distinction between a simple reverse proxy and a routing proxy.
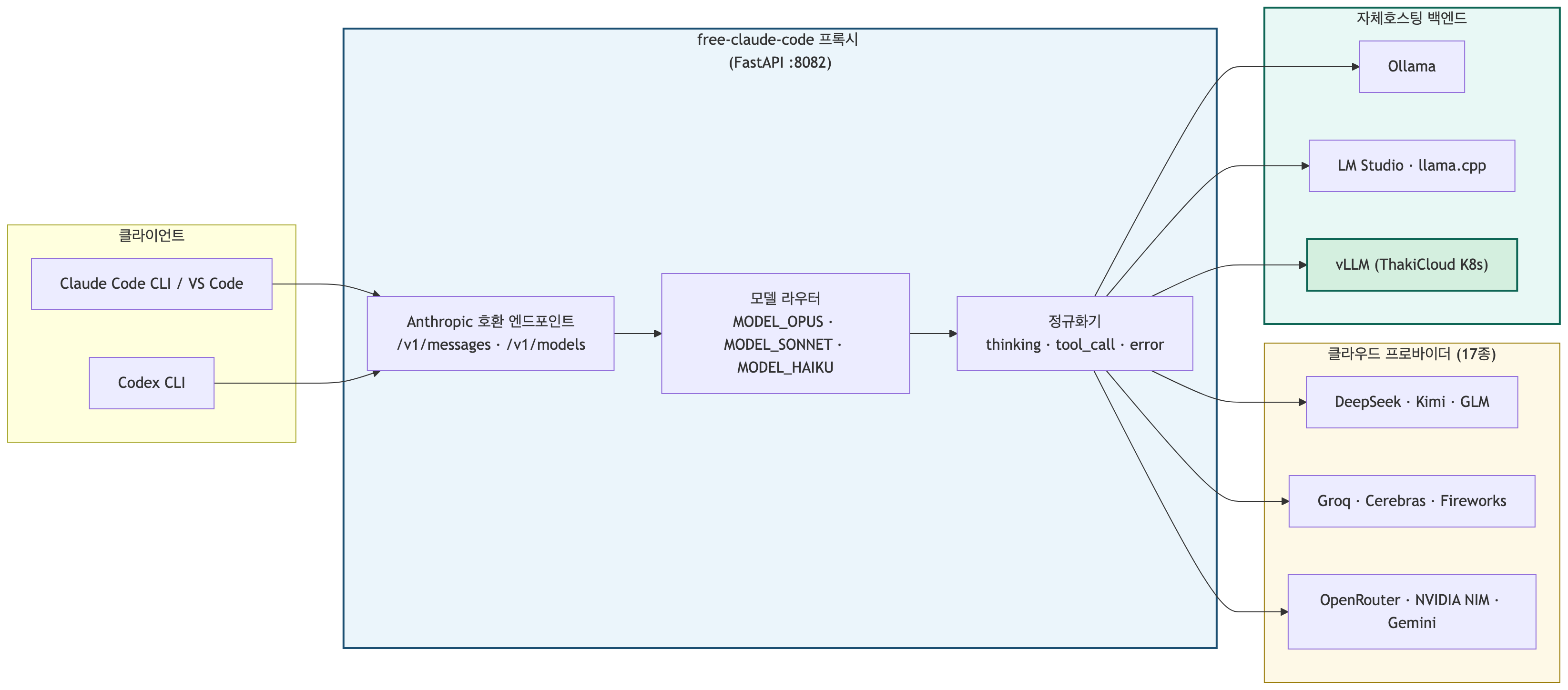 Figure 1. The FastAPI proxy receives Anthropic-compatible traffic from Claude Code and routes it to 17 providers. From ThakiCloud’s perspective, the important paths are the self-hosted backends on the right (Ollama, LM Studio, vLLM).
Figure 1. The FastAPI proxy receives Anthropic-compatible traffic from Claude Code and routes it to 17 providers. From ThakiCloud’s perspective, the important paths are the self-hosted backends on the right (Ollama, LM Studio, vLLM).
The supported providers number 17. On the cloud side: NVIDIA NIM, OpenRouter, Google AI Studio (Gemini), DeepSeek, Mistral La Plateforme, Mistral Codestral, OpenCode Zen, OpenCode Go, Wafer, Kimi, Cerebras, Groq, Fireworks, and Z.ai. On the self-hosted side: LM Studio, llama.cpp, and Ollama. The last three are the meaningful ones from ThakiCloud’s perspective. Since Ollama and llama.cpp expose OpenAI-compatible endpoints, a vLLM server deployed the same way on Kubernetes can be attached identically.
Tier-based routing is controlled via environment variables. MODEL_OPUS, MODEL_SONNET, and MODEL_HAIKU each specify which model to route to for the three Claude tiers; if unspecified, the fallback MODEL is used. This enables differentiated placement — for example, routing lightweight Haiku traffic to a small local model and heavier Opus traffic to a larger one.
Installation and Integration
The official installation path is a shell one-liner:
# macOS / Linux
curl -fsSL "https://github.com/Alishahryar1/free-claude-code/blob/main/scripts/install.sh?raw=1" | sh
# Windows PowerShell
irm "https://github.com/Alishahryar1/free-claude-code/blob/main/scripts/install.ps1?raw=1" | iex
Rather than the shell one-liner, I verified the package by installing it directly in an isolated sandbox, in order not to contaminate ThakiCloud’s shared virtual environment per our Python runtime rules.
# Isolated worktree + ephemeral venv (shared .venv is 3.12.8 and would conflict)
uv venv --python 3.14 .expenv
VIRTUAL_ENV=.expenv uv pip install "git+https://github.com/Alishahryar1/free-claude-code.git"
The package itself installs cleanly. Dependencies such as fastapi, uvicorn, httpx, pydantic, openai, and loguru resolve successfully, and console scripts like fcc-server, fcc-init, and fcc-claude are created. After starting the server, Claude Code is directed to the proxy as follows:
fcc-server # Start the FastAPI proxy (default http://127.0.0.1:8082)
# Self-hosted backend example (Ollama):
# MODEL_HAIKU=ollama/llama3.2:3b
# MODEL_SONNET=ollama/qwen2.5:7b
# Specify the base URL to point Claude Code at the proxy, then use as normal
The admin UI is at http://127.0.0.1:8082/admin and is only accessible from loopback. Provider keys, model routing, and messaging and voice settings are managed here.
Actual Experiment Results
During validation I encountered a point where reproduction was blocked, and I record it as-is. Not fabricating numbers is a principle of this report.
Boot Blocker: Hard Python 3.14 Requirement
free-claude-code v2.3.14 has hardcoded requires-python = ">=3.14.0". Python 3.14 is the latest version, only officially released in October 2025. The problem was that the only available 3.14 in the test environment was an alpha build (3.14.0a7). Running fcc-server on this alpha fails with the following error:
ImportError: cannot import name 'get_annotate_from_class_namespace'
from 'annotationlib'
This is a conflict where the pinned pydantic expects the annotationlib API of the final 3.14, but that symbol is not yet present in the early alpha. I then attempted to force-run it under the next lower stable version (3.13), but installation itself is rejected because of the hard requirement in the package metadata:
free-claude-code==2.3.14 cannot be used ... your requirements are unsatisfiable.
The conclusion is clear: in environments without a stable Python 3.14, this proxy will not boot. Reproduction attempt failed: the package hard-requires freshly released Python 3.14, but the only available 3.14 is an alpha that conflicts with the pinned pydantic. This is less a defect in the tool than a problem of aggressive version pinning that is at odds with the reality that production images typically remain on 3.11–3.12.
Direct Measurement of the Self-Hosted Routing Path
Although the proxy itself was blocked at boot, the mechanism this tool uses to call the ollama provider is the OpenAI-compatible endpoint. I therefore measured this path by calling local Ollama directly. These are the backend’s own routing performance numbers without the proxy overhead that fcc would add. The results of mapping Claude’s three tiers to local models are as follows (Apple Silicon, identical prompt, 64-token cap):
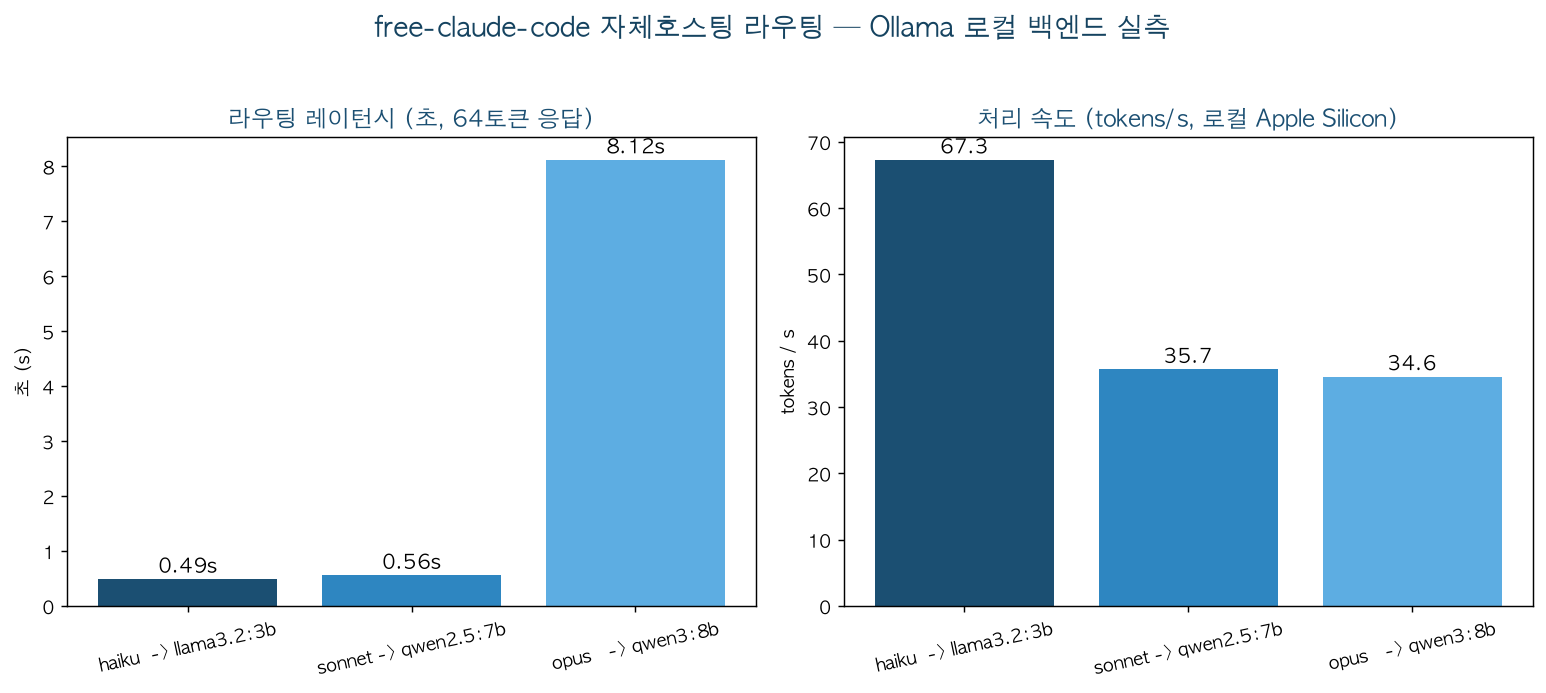 Figure 2. Latency and throughput when routing Claude tiers to local Ollama models. qwen3:8b placed on the opus path is a thinking model that outputs extended reasoning tokens, significantly increasing the time.
Figure 2. Latency and throughput when routing Claude tiers to local Ollama models. qwen3:8b placed on the opus path is a thinking model that outputs extended reasoning tokens, significantly increasing the time.
| Routing | Model | Latency | Completion Tokens | Throughput |
|---|---|---|---|---|
| haiku | llama3.2:3b | 0.49s | 33 | 67.3 tok/s |
| sonnet | qwen2.5:7b | 0.56s | 20 | 35.7 tok/s |
| opus | qwen3:8b | 8.12s | 281 | 34.6 tok/s |
The small model (llama3.2:3b) finishes responding in under 0.5 seconds — fast enough for Haiku replacement traffic. qwen2.5:7b at 0.56 seconds is also practical. The qwen3:8b placed on the opus path, however, took 8.12 seconds, because the thinking model first emits 281 reasoning tokens. The throughput itself (34.6 tok/s) is normal, but this measurement confirms that placing a reasoning model in a heavy tier causes a token explosion and significantly increases perceived latency. A practical lesson: when designing tier mappings, the reasoning-token behavior of the model must also be considered.
Application and Implications for ThakiCloud’s K8s AI/ML SaaS Platform
The real value of this tool lies not in “free” but in the connection pattern. Once an Anthropic-compatible proxy is inserted as a layer, commercial agents like Claude Code can be attached directly to our infrastructure.
ThakiCloud schedules GPUs with Kueue and serves models with vLLM on Kubernetes. Since vLLM provides an OpenAI-compatible endpoint (/v1/chat/completions), it can be connected to free-claude-code’s self-hosted provider path in the same way as Ollama or llama.cpp. The connection method is common across self-hosted providers: specify the base URL as the cluster’s vLLM service endpoint and add the provider prefix to the model identifier. Just as Ollama uses ollama/llama3.2:3b, an in-house model served on vLLM is added to the routing targets with the same prefix convention. This enables the following:
- Data sovereignty: Code and prompts never leave the tenancy boundary. This is essential in regulated environments such as on-premises deployment and NIS (National Intelligence Service) compliance requirements.
- Cost structure shift: Per-token metered billing is replaced by fixed GPU costs. The higher the usage, the faster self-serving reaches its break-even point.
- Tiered differentiated placement: Lightweight Haiku traffic can be routed to small models, and heavier workloads to larger ones, optimizing GPU occupancy. The measurements above provide baseline numbers for this differentiated placement.
That said, rather than adopting this tool as-is, it is more rational to borrow only the validated routing pattern. In a multi-tenant environment, the proxy must have per-tenant authentication, isolation, and observability, but free-claude-code’s admin UI assumes a single loopback user and is insufficient as-is. The idea behind the Anthropic-compatible normalization layer is worth borrowing, but authentication, quotas, and logging must be re-implemented to match our gateway standards.
Limitations and Counterarguments
First, there is the Terms of Service gray area. The “Claude Code for free” framing relies on routing through free-tier providers, which may conflict with each service’s terms. In enterprise environments, legitimate and sustainable use is strictly routing to owned backends (self-served models). This is why this article emphasizes only the self-hosting path.
Second, there is aggressive version pinning. As seen above, the hard Python 3.14 requirement immediately prevents booting in environments without a stable runtime. Considering the cost and risk of upgrading production container images to 3.14, inserting this tool directly into a deployment pipeline at this point carries too much friction.
Third, quality equivalence is not guaranteed. Replacing Claude’s Opus or Sonnet with different models does not preserve coding quality. Routing is a trade-off that gains cost savings and data sovereignty at the expense of response quality; which traffic to send where must be determined by measurement, depending on task difficulty.
Fourth, the measurements in this report are direct backend call numbers without going through the proxy. The normalization and routing overhead of fcc is not included. Once a stable Python 3.14 environment is secured, I plan to re-measure the round-trip latency through the proxy and supplement these results.
In summary, free-claude-code is risky if consumed as a “free hack,” but read as an open-source reference for Anthropic-compatible routing patterns, it is a solid starting point for the design of connecting commercial agents to self-hosted inference infrastructure.
Sources
- GitHub: Alishahryar1/free-claude-code (MIT, 36.7k stars, v2.3.14)
- Measurement data: Direct calls to local Ollama OpenAI-compatible endpoint (llama3.2:3b, qwen2.5:7b, qwen3:8b, Apple Silicon)
- Related article: ThakiCloud Tech Blog “Routing Claude Code to In-House Models - claude-code-router”