Agents That Imagine the Environment First: A Deep Dive into Qwen-AgentWorld Language World Models
⏱️ Estimated reading time: 14 min
📄 Full deep review (DOCX): Download the detailed peer review on Google Drive.
Overview
Most agents today work the same way. They receive a task, attempt it, and correct mistakes when they appear. Trial and error in the real environment. The loop is intuitive but expensive. When the environment is an actual terminal, an actual browser, or an actual Android device, every attempt carries real cost and real risk.
On June 24, 2026, Alibaba’s Qwen team released Qwen-AgentWorld, which flips that premise. Instead of training an agent to act better, the model is trained to predict the environment itself. Given the current observation and an action, it anticipates what the next environment state will look like before anything is executed. Think of a chess player reading three moves ahead before touching a piece.
At ThakiCloud, we run multi-tenant agent workloads in production on a Kubernetes-based AI/ML SaaS platform. Each customer brings a different environment, different tools, and different constraints, so “how you handle the environment” is not an abstract research question for us – it directly affects operating cost. That is why we analyzed this model against the official technical report (arXiv 2606.24597) and the publicly available GitHub materials, and summarized both where it fits our platform and what to watch out for.
What Is Qwen-AgentWorld
A world model predicts environment dynamics from the current observation and action. It has a long history as a core cognitive mechanism in reasoning and planning, studied mainly in robotics and games – physical or visual settings. Qwen-AgentWorld is different in that it implements the world model on top of a language model using chain-of-thought reasoning.
The defining characteristic is that a single model simulates 7 domains: MCP, Search, Terminal, SWE, Web, OS, and Android. Given a system prompt that says “simulate a Linux terminal environment” and a user command, the model predicts what the terminal would output without ever executing the command.
Another key design choice is the native world model approach. Environment modeling is not a capability bolted on at the end of training – it is the objective from the very first stage (CPT), with more than 10 million real-world interaction trajectories used to instill that ability from the ground up. As the authors put it, LLMs have been trained to act well in environments but never to model the environments themselves. Qwen-AgentWorld targets exactly that gap.
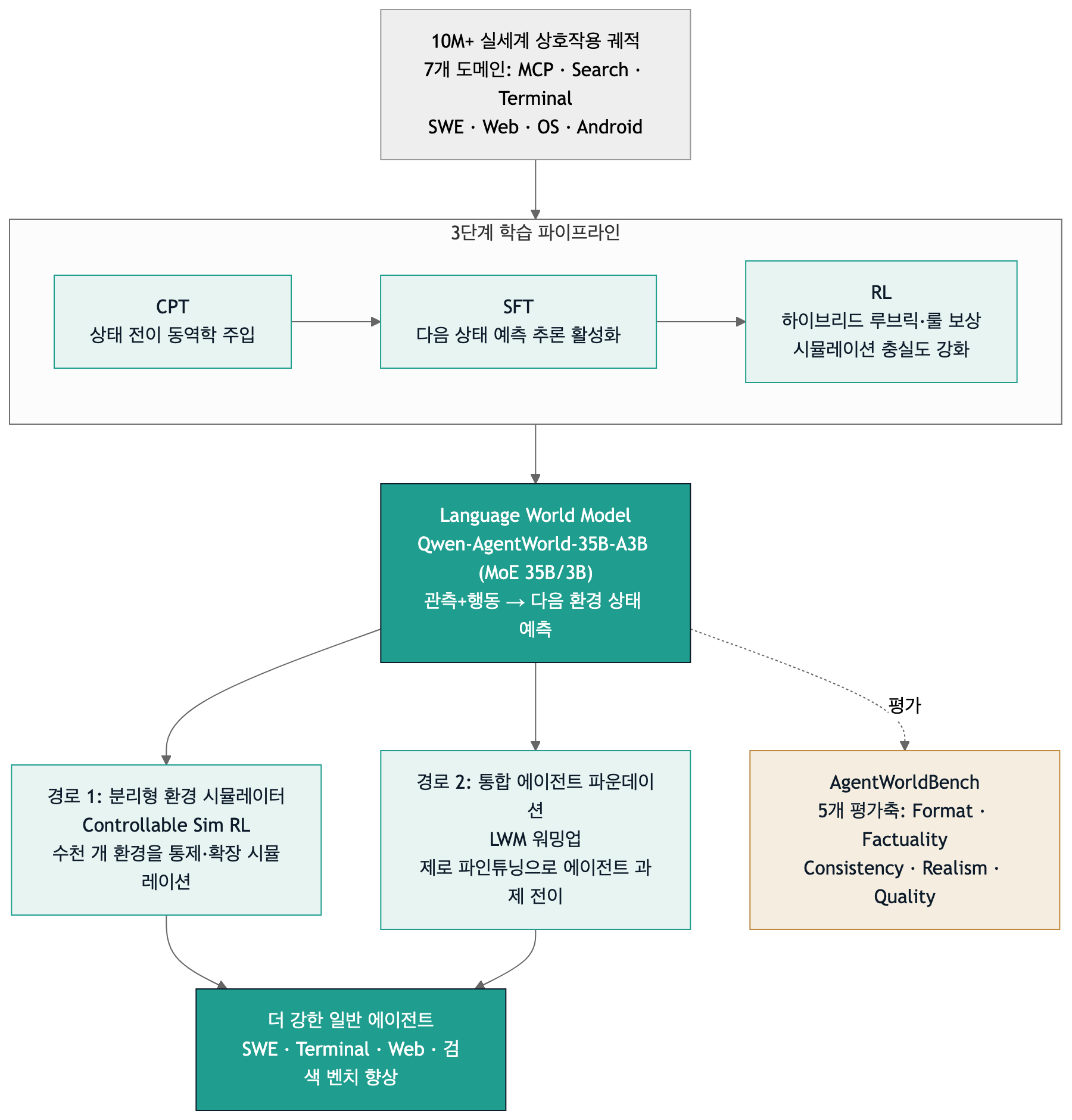 Architectural overview of the three-stage training pipeline (CPT/SFT/RL) and two downstream application paths for Qwen-AgentWorld.
Architectural overview of the three-stage training pipeline (CPT/SFT/RL) and two downstream application paths for Qwen-AgentWorld.
Three-Stage Training Pipeline
Qwen-AgentWorld is built through three distinct training stages, each with a clearly separated role.
- CPT (Continual Pre-Training): Injects general world-modeling capability from state-transition dynamics and an enriched domain corpus. This is where the model builds foundational knowledge of how environments respond to actions.
- SFT (Supervised Fine-Tuning): Activates next-state-prediction reasoning. Rather than simply predicting the correct next state, the model learns to reason through chain-of-thought about why that state arises.
- RL (Reinforcement Learning): Improves simulation fidelity using a hybrid rubric-and-rule reward. Signals covering format correctness, factual accuracy, and consistency are used to refine prediction quality.
The publicly released model is Qwen-AgentWorld-35B-A3B, a Mixture-of-Experts architecture with 35 billion total parameters and only 3 billion active at inference time, with a context length of 256K. The technical report also describes a larger Qwen-AgentWorld-397B-A17B, but those weights have not been released. To be precise about what is actually public: the 35B-A3B model weights and the AgentWorldBench benchmark are available under Apache-2.0, while the 397B exists only as results in the report. This distinction matters whenever you see marketing copy suggesting you can “run it locally right now.”
Benchmark: AgentWorldBench
How do you evaluate a language world model? The Qwen team released AgentWorldBench alongside the model. It collects real interaction traces produced by 5 frontier models across 9 existing benchmarks and scores predicted environment observations on five axes: Format, Factuality, Consistency, Realism, and Quality. Scoring uses a separate judge model (gpt-5.2).
The table below shows the Overall scores (average of the 5-axis rubric per domain, normalized 0-100) from the official GitHub repository.
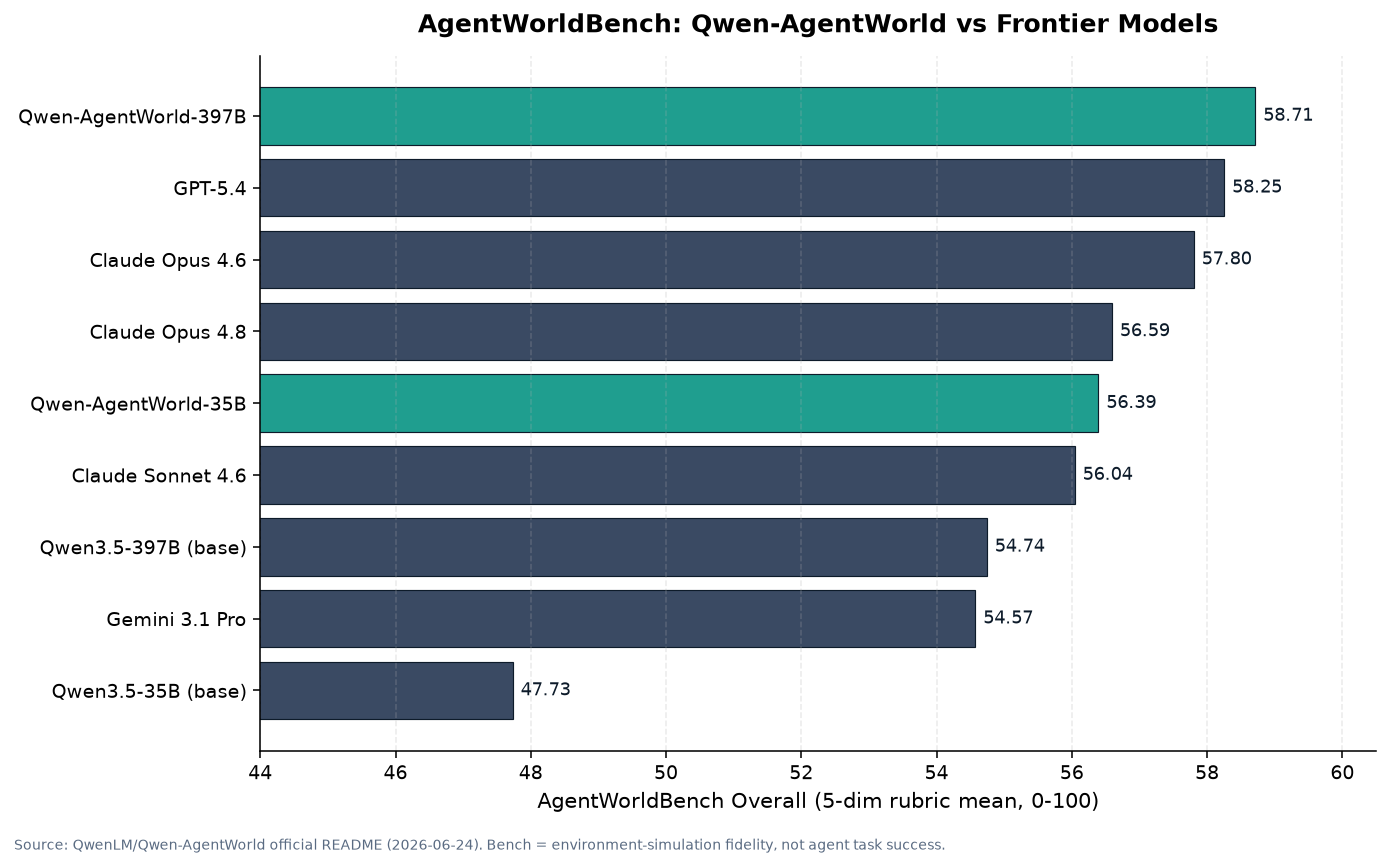 AgentWorldBench Overall scores. This measures environment simulation fidelity, not agent task success rate. Source: QwenLM/Qwen-AgentWorld official README.
AgentWorldBench Overall scores. This measures environment simulation fidelity, not agent task success rate. Source: QwenLM/Qwen-AgentWorld official README.
By the numbers:
- Qwen-AgentWorld-397B-A17B: 58.71, first overall. It surpasses GPT-5.4 (58.25), Claude Opus 4.8 (56.59), and Gemini 3.1 Pro (54.57).
- Qwen-AgentWorld-35B-A3B: 56.39, up +8.66 from the base model Qwen3.5-35B-A3B (47.73). That is more than 8 points gained purely through world-model training.
Two things deserve emphasis here. First, what this benchmark measures is not “how well can the agent solve tasks” but “how accurately can the model predict the next environment state” – simulator fidelity. Second, the model that beats all frontier models is the 397B, which has not been released. The publicly available 35B sits at 56.39, slightly below GPT-5.4 and Claude Opus 4.8. The improvement margin is impressive, but framing it as “the open model beat every closed model” is inaccurate.
Two Paths From World Model to Stronger Agent
Qwen-AgentWorld is more than a standalone simulator because it proposes two concrete paths through which the world model makes agents stronger.
Path 1: Decoupled Environment Simulator (Controllable Sim RL). The world model is used in place of the real environment for reinforcement learning. Instead of spinning up thousands of actual environments, the model generates a controllable, scalable simulation. According to the report, applying Sim RL across 4,000 out-of-distribution (OOD) OpenClaw environments with Qwen-AgentWorld-397B-A17B as the simulator raised scores from a base of 65.4 / 47.9 to 69.7 / 55.0. Notably, the controllable simulation outperformed the uncontrolled version. In one configuration, controllable Sim RL improved over the SFT base by +16.29 / +10.49 – better than training on the real environment alone.
Path 2: Unified Agent Foundation (LWM Warmup). World-model training is used as a form of pre-conditioning. A model that undergoes LWM RL warmup – on single-turn, non-agentic trajectories – transfers that predictive knowledge directly to multi-turn, tool-calling agent tasks, without dedicated agent-specific training. The claim is that learning to predict environments transfers to acting in them. Adding LWM RL to Qwen3.5-35B-A3B-SFT produced the following gains across 7 benchmarks:
| Benchmark | SFT Base | + LWM RL | Improvement |
|---|---|---|---|
| Terminal-Bench 2.0 | 33.25 | 39.55 | +6.30 |
| SWE-Bench Verified | 64.47 | 67.86 | +3.39 |
| SWE-Bench Pro | 42.18 | 47.42 | +5.24 |
| WideSearch F1 Item | 33.38 | 46.17 | +12.79 |
| Claw-Eval | 53.60 | 64.88 | +11.28 |
| QwenClawBench | 39.76 | 49.43 | +9.67 |
| BFCL v4 | 62.29 | 71.25 | +8.96 |
Three of these benchmarks were entirely out-of-domain, yet improvements still appeared. Learning to predict environments turns out to help with acting in them – a somewhat counterintuitive result.
How to Run It
The released 35B-A3B model can be served directly from inference frameworks like SGLang and vLLM. The official repository provides these commands:
# Serve with vLLM
vllm serve Qwen/Qwen-AgentWorld-35B-A3B
# Or with SGLang
python -m sglang.launch_server --model-path Qwen/Qwen-AgentWorld-35B-A3B
The usage pattern follows a standard OpenAI-compatible chat interface, with the distinction that the system prompt specifies which environment to simulate:
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
messages = [
{
"role": "system",
"content": "You are a language world model simulating a Linux terminal environment. "
"Given the user's command, predict the terminal output.",
},
{"role": "user", "content": "ls -la /var/log"},
]
AgentWorldBench evaluation is also public. Domain-specific JSONL files (mcp_test.jsonl, terminal_test.jsonl, etc.) can be downloaded to reproduce the 5-axis scoring yourself. That said, even with MoE, the 35B-A3B has non-trivial GPU memory requirements – production serving needs appropriate accelerators and tensor parallelism configured. We did not run inference on our own GPUs for this post; all analysis is based on the official report and publicly disclosed numbers from the repository. No self-measured results are included.
Implications for the ThakiCloud K8s AI/ML SaaS Platform
At ThakiCloud, we schedule GPU workloads with Kueue on Kubernetes, serve multi-tenant inference with vLLM, and operate per-customer isolated agents. From that vantage point, Qwen-AgentWorld raises three implications.
First, environment simulation can change the cost structure of agent training. Running reinforcement learning in a customer environment today means spinning up thousands of real environment instances – not just GPU compute, but also environment infrastructure: browser pools, sandboxed terminals, mobile emulators. If a world model replaces those environments, the RL loop collapses into a single model-serving workload. Controllable simulation RL gated behind a single Kueue queue significantly reduces operational complexity in a multi-tenant setting.
Second, it is on-premise and self-hosting friendly. The 35B-A3B is Apache-2.0, placing no restrictions on commercial use or self-hosting. For customers in regulated sectors – domestic public-sector or financial institutions where data cannot leave the building – this opens an option to host the environment simulator inside our cluster rather than calling an external API. Encapsulating the environment as a model means agents can be trained and evaluated without exposing sensitive operational environments to the outside.
Third, the evaluation infrastructure has standalone value. AgentWorldBench’s 5-axis scoring (Format, Factuality, Consistency, Realism, Quality) is a solid framework for a multi-tenant agent quality gate. Before deploying an agent to a customer environment, it gives us a quantitative way to measure how accurately the agent understands that environment. Even without serving the 397B ourselves, the evaluation design and the open 35B simulator are assets that slot directly into an internal validation pipeline.
This is a roadmap-level capability, not something to deploy wholesale today. Replacing all customer environments with world models immediately is not practical, and domains where the simulator’s fidelity is lower still require training in real environments. But the direction – “let the model generate the environment” – aligns precisely with the cost and isolation challenges of a multi-tenant agent platform, making it worth tracking closely.
Limitations and Counterarguments
The first thing to flag is the gap between the marketing and what is actually released. Social media spread a narrative along the lines of “Alibaba just open-sourced an agent model that beats every closed model – run it locally now.” But the model that beats the frontier is the unreleased 397B. The one you can actually download and run, the 35B, scores slightly below GPT-5.4 and Claude Opus 4.8. “Beat” and “released” refer to different models and that needs to be stated clearly.
Second, the nature of the benchmark. AgentWorldBench measures environment prediction fidelity, not agent task success. Accurately predicting what the environment will do next does not directly guarantee the agent will solve tasks well in that environment. The transfer results from Path 2 provide partial evidence of the connection, but how far it generalizes needs further validation.
Third, the self-construction and self-scoring limitation. The same team that built the model also designed the evaluation axes and chose the judge model (gpt-5.2). That is not inherently bad practice, but until independent third-party reproductions accumulate, the absolute numbers should be read conservatively.
Fourth, the hallucination risk in simulators. If the world model generates a plausible but incorrect next environment state, the agent trained on top of it learns rules that do not exist. Controllability is both the strength and the hazard. Learning that relies exclusively on simulation without periodic calibration against real environments may be vulnerable to distribution shift.
Even so, the direction – understanding the environment before making the agent smarter – is genuinely fresh. And because the 35B model and benchmark are open under Apache-2.0, the door to verification and experimentation is not closed. Strip away the overstated headlines and this is a practically useful piece of research for anyone running a multi-tenant agent platform.
Sources
- Qwen-AgentWorld technical report (arXiv): arxiv.org/abs/2606.24597
- Official blog: qwen.ai/blog?id=qwen-agentworld
- GitHub: github.com/QwenLM/Qwen-AgentWorld
- Hugging Face model/benchmark: huggingface.co/collections/Qwen/qwen-agentworld
- Alibaba Qwen official announcement (X): x.com/Alibaba_Qwen/status/2069720365442719867
📄 Full deep review (DOCX): Download the detailed peer review on Google Drive.