نموذج يفكر بـ 220 ألف رمز: كيف يقلب GLM-5.2 حسابات الاستضافة الذاتية
إذا احتاج نموذج إلى 220 ألف رمز ليحل مكعب روبيك واحداً، فمن يدفع تلك التكلفة؟ هذا بالضبط ما يطرحه Matt Pocock (@mattpocockuk)، صانع أدوات المطورين، حين جعل GLM-5.2 يحل مكعب روبيك عبر مهارة /teach الخاصة به. وقد رصد في أدنى مستويات الجهد (High) نحو 220 ألف رمز من آثار التفكير في ثلاث جولات فحسب. أن يكون نموذج الاستدلال أقوى يعني حتماً أنه يستهلك رموزاً أكثر، وأن يستهلك رموزاً أكثر يعني أن شخصاً ما يتلقى فاتورة بذلك الحجم.
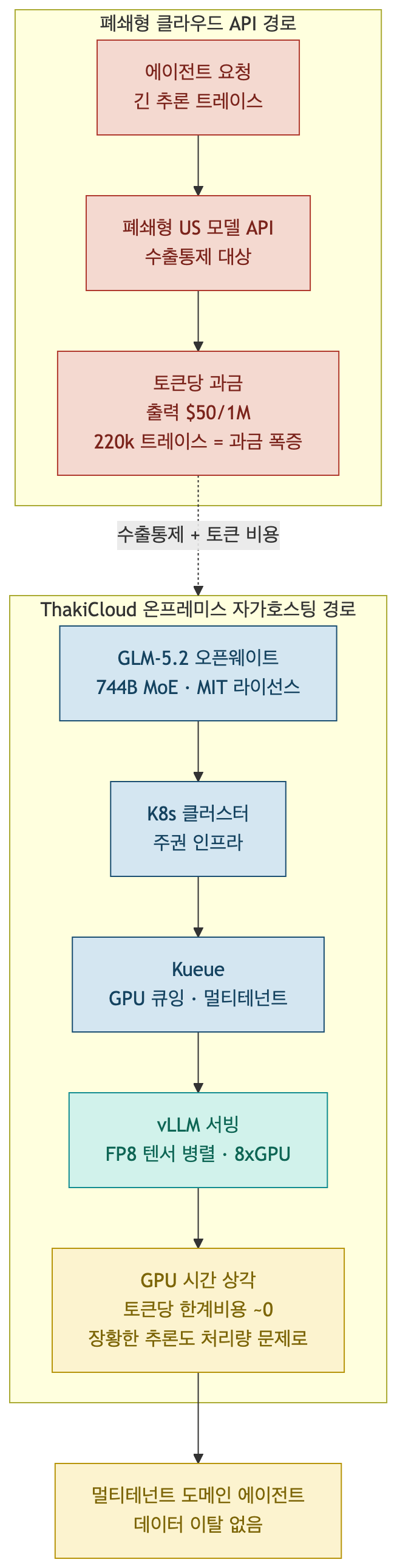
هذا المقال ليس عرضاً لنموذج GLM-5.2 ذاته. موضوع التكميم إلى بت واحد لتشغيل النموذج على أجهزة أصغر قد تناولناه في مقال مستقل. ما يعنينا هنا مستوى أعلى من ذلك: كيف تتباين حسابات التكلفة بين واجهات برمجية سحابية تُحاسب على الرمز وبين استضافة ذاتية داخل المقر تستهلك وقت المعالج الرسومي بشكل ثابت، حين يظهر نموذج استدلال بأوزان مفتوحة يفكر بإسهاب. والخلاصة المختصرة: كلما طال الاستدلال، كان ثمة نقطة واضحة تصبح عندها الاستضافة الذاتية الأوفر تكلفة، وهذا تحديداً ما تُوليه ThakiCloud اهتماماً في منصتها متعددة المستأجرين القائمة على K8s.
جميع الأرقام الواردة في هذا المقال مستقاة من قياسات نشرتها Z.ai ووسائل إعلام متعددة، أو محسوبة رياضياً من عدد المعاملات المُعلنة. لم يتسن لنا تشغيل نموذج 744B مباشرة في بيئتنا، لذا نستشهد بالأرقام العلنية بدلاً من معايير ذاتية، وأي تقدير رياضي نشير إليه بـ [تقديري].
نظرة عامة
GLM-5.2 نموذج لغوي ضخم بأوزان مفتوحة، أطلقته Z.ai (المعروفة سابقاً بـ Zhipu AI، مؤسسة تأسست عام 2019 انبثقت من مختبر الهندسة المعرفية بجامعة تسينغهوا في بكين) في 13 يونيو 2026. يعتمد النموذج بنية Mixture-of-Experts (MoE) بإجمالي نحو 744B معامل، يُفعَّل منها نحو 40B معامل لكل رمز، مع دعم لسياق يصل إلى مليون رمز وإخراج يبلغ 128 ألف رمز كحد أقصى. الأوزان منشورة بموجب رخصة MIT، مما يتيح لأي جهة تحميلها وتشغيلها تجارياً على بنيتها التحتية الخاصة.
للتوقيت دلالة بالغة. أفادت وسائل إعلام عديدة بأن GLM-5.2 صدر بعد يومين فقط من أمر أمريكي يقضي بمنع Anthropic من إتاحة نموذجَي Fable 5 وMythos 5 للوصول الدولي. بمعنى آخر، تزامنت في الأسبوع ذاته موجة تقييد وصول النماذج الحدودية المغلقة بقيود التصدير، مع ظهور نموذج مفتوح قوي قابل للاستضافة الذاتية برخصة MIT. بالنسبة للمنظمات التي تفكر في سيادة البيانات والنماذج معاً، هذا التناقض ليس قضية سياسية مجردة، بل خيار معماري آني.
الأداء أيضاً موضع تقدير عالٍ. وفقاً للمعايير المستقلة التي أوردها The Decoder وغيره، فضلاً عن بطاقة التقنية الصادرة عن Z.ai، اقترب GLM-5.2 من الصدارة في مهام الترميز الطويلة:
| المعيار | GLM-5.2 | Claude Opus 4.8 | GPT-5.5 | GLM-5.1 |
|---|---|---|---|---|
| SWE-bench Pro (ترميز) | 62.1 | 69.2 | 58.6 | 58.4 |
| Terminal-Bench 2.1 (عامل) | 81.0 | ~84 | n/a | 63.5 |
| FrontierSWE (ترميز طويل) | 74.4% | 75.4% | ~73% | n/a |
| AIME 2026 (رياضيات) | 99.2% | - | - | - |
حقق GLM-5.2 نتيجة 62.1 في SWE-bench Pro، متفوقاً على GPT-5.5 (58.6) وعلى الجيل السابق GLM-5.1 (58.4)، فيما قفز أداؤه في Terminal-Bench 2.1 من 63.5 إلى 81.0. يحتل بذلك المرتبة الأولى بين النماذج المفتوحة في جميع هذه البنود. (تتفاوت نتيجة FrontierSWE بين المصادر المختلفة في نطاق 73 إلى 75%.)
كيف يسعى GLM-5.2 إلى تقليص استهلاك الرموز
اللافت أن تصميم GLM-5.2 يواجه مباشرة مسألة “كيف نعالج سياقاً طويلاً ورموزاً كثيرة بتكلفة أقل”. كل نموذج يتبنى سياقاً بمليون رمز يصطدم بالعائق الهندسي ذاته: حين يمتد السياق، ينتقل عنق الزجاجة من الحساب الخالص إلى سعة ذاكرة التخزين المؤقتة للمفاتيح والقيم (KV cache) ومصاريف النواة. تعالج Z.ai هذا بآليتين.
الأولى هي IndexShare. في آلية DeepSeek Sparse Attention (DSA) القياسية، تشغّل كل طبقة محول مفهرساً مستقلاً لتحديد الرموز التي تستحق الاهتمام، وهو ما يُكلّف كثيراً عند التوسع. يحل IndexShare هذه المشكلة بتشغيل المفهرس في الطبقة الأولى من كل مجموعة رباعية فقط، ثم تُعيد الطبقات الثلاث التالية استخدام مؤشرات top-k ذاتها. النتيجة: انخفاض تكلفة الفهرسة الداخلية بنسبة 75% في تلك الطبقات، وتراجع عمليات الحساب لكل رمز بمقدار 2.9 مرة عند طول السياق مليون رمز. الثانية هي الجمع بين KVShare والتنبؤ بعدة رموز في آنٍ واحد (MTP)، مما يرفع سرعة فك التشفير بالتنبؤ بعدة رموز دفعة واحدة خلال تمريرة أمامية واحدة.
أما الرافعة التي يتحكم بها المستخدم مباشرة فهي إعداد مستوى الجهد. يوفر GLM-5.2 مستويَين: High وMax، وتوصي Z.ai باستخدام Max في مهام الترميز. القيمة الافتراضية لجلسة جديدة هي High. وفق القياسات المنشورة، يستهلك مستوى Max نحو 85 ألف رمز إخراج للمهمة الواحدة لاستخلاص أعلى جودة، فيما يتنازل مستوى High عن نقاط قليلة في الأداء مقابل خفض يبلغ فعلياً النصف في رموز الإخراج. بعبارة أخرى، استهلاك الرموز ليس قراراً داخلياً تلقائياً للنموذج، بل هو متغير يمكن للمشغّل ضبطه صراحةً. وهذا المتغير هو المفتاح المحوري في حسابات التكلفة التي نناقشها لاحقاً.
ما كشفته /teach: الاستدلال يلتهم الرموز
لنعد إلى ملاحظة Matt Pocock. في أدنى مستوى جهد، استغرق حل مكعب روبيك واحد ثلاث جولات وما يقارب 220 ألف رمز. ولو رُفع مستوى الجهد إلى Max، لارتفع هذا العدد أكثر. هذا ليس قصوراً في النموذج، بل هو طبيعة نماذج الاستدلال. كلما “فكر” النموذج أطول قبل الوصول إلى إجابة، ارتفعت جودة المخرجات، وكل ذلك التفكير يُحاسَب عليه كرموز إخراج.
المسألة هي: أين تُسوَّى تكلفة هذه الرموز؟ الـ220 ألف رمز ذاتها تُكلّف بأسعار مختلفة جذرياً بحسب هيكل المحاسبة. سعر إخراج واجهة Z.ai هو 4.40 دولار لكل مليون رمز (و1.40 دولار للإدخال، و0.26 دولار للإدخال المخزَّن مؤقتاً). النماذج الأمريكية الحدودية المغلقة تبلغ تكلفة الإخراج فيها نحو 50 دولاراً لكل مليون رمز. حين نحوّل هذين السعرين إلى تكلفة لكل مهمة وفق مستويات الجهد، يتضح الفارق:
| رموز الإخراج للمهمة | GLM-5.2 API (4.40 دولار/1M) | نموذج مغلق (50 دولار/1M) |
|---|---|---|
| نحو 8.5k (مهمة قصيرة) | 0.037 دولار | 0.425 دولار |
| نحو 42k (تقدير High [تقديري]) | 0.185 دولار | 2.10 دولار |
| 85k (مستوى Max) | 0.374 دولار | 4.25 دولار |
| 220k (ملاحظة /teach) | 0.968 دولار | 11.00 دولار |
يلفت النظر أولاً أن النموذج ذا الأوزان المفتوحة أرخص بستة أضعاف حتى عبر واجهة برمجية. لكن الدلالة الأعمق في مكان آخر: كلا الخيارين يُحاسبان على الرمز. كلما طال الاستدلال، ارتفعت الفاتورة بصورة خطية. إن كانت الأعباء تستهلك 220 ألف رمز في كل استدعاء وتُشغَّل عشرات الآلاف من المرات يومياً، فإن الكميّة ذاتها هي ما يتحكم في التكلفة، مهما انخفض سعر الرمز. وعند هذه النقطة تحديداً ترسم الاستضافة الذاتية منحنى مختلفاً تماماً.
نموذج تكلفة الخدمة: الاستضافة الذاتية تعكس المعادلة
في الاستضافة الذاتية، هيكل التكلفة يُحاسَب على الوقت لا على الرمز. منذ لحظة توفير عقدة المعالج الرسومي، تصبح التكلفة شبه ثابتة سواء أُنتج رمز واحد أو مليارات الرموز. لذا تتحول آثار الاستدلال الطويلة من “مشكلة محاسبة رموز” إلى “مشكلة إنتاجية وزمن استجابة”، وتغدو مسألة هندسية: كيف نحشد أكبر قدر ممكن من الاستدلال في وقت معالج رسومي ثابت؟
غير أن الاستضافة الذاتية تنطوي على حاجز دخول. لا بد من تحميل أوزان 744B في مكان ما. فيما يخص بصمة الذاكرة المحسوبة رياضياً من عدد المعاملات المُعلن (مع استثناء ذاكرة KV cache، وهي حسابات رياضية خالصة [تقديري]):
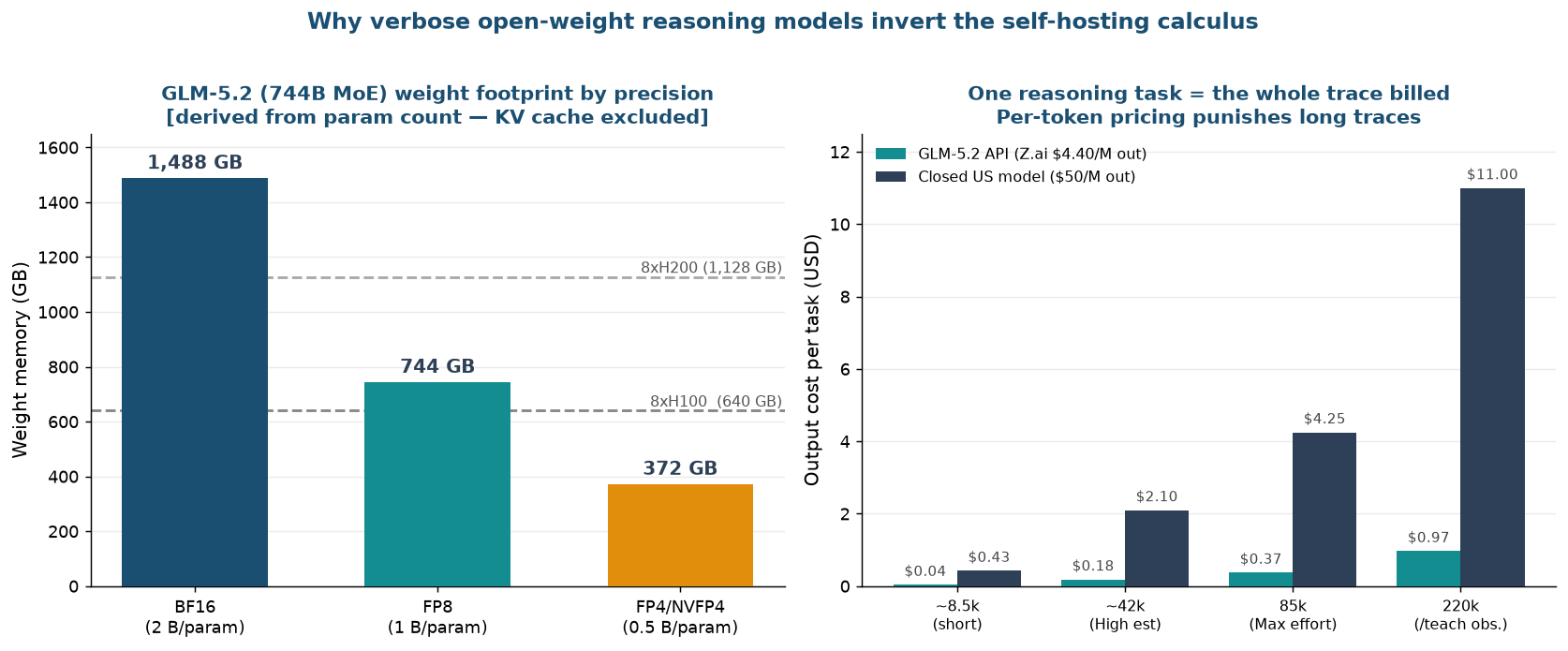
تبلغ البصمة نحو 1,488 جيجابايت بدقة BF16، ونحو 744 جيجابايت بدقة FP8، ونحو 372 جيجابايت بدقة FP4/NVFP4. ربط ثمانية معالجات H100 (80 جيجابايت) يوفر 640 جيجابايت، وربط ثمانية معالجات H200 (141 جيجابايت) يوفر 1,128 جيجابايت. بمعنى أن أوزان FP8 تدخل في عقدة H200 واحدة بارتياح، بينما تكون الأمور حرجة في عقدة H100 حين نأخذ بالاعتبار احتياطي ذاكرة KV cache. بالنزول إلى FP4 تُصبح عقدة H100 الواحدة كافية بمرونة. بمعنى آخر، استضافة نموذج استدلال على مستوى الحدود في عقدة معالج رسومي واحدة لم تعد فكرة بعيدة المنال.
هنا تنقلب المعادلة. حين تُضمَن عقدة مُقدَّمة عبر vLLM وتُستهلك تكلفة المعالج الرسومي بالكامل، فإن التكلفة الهامشية لعبء عمل يستهلك 220 ألف رمز تُحدَّد لا بعدد الرموز، بل بمدى إشغال إنتاجية تلك العقدة. كلما كان الاستدلال أكثر إسهاباً وكلما كانت الاستدعاءات أكثر تكراراً، كبُرت قاعدة استهلاك التكلفة الثابتة وانخفض التكلفة الفعلية لكل رمز. إن الحالة التي تكون فيها واجهات برمجية المحاسبة على الرمز في أسوأ أحوالها (آثار طويلة في استدعاءات متكررة) هي بالضبط الحالة التي تكون فيها الاستضافة الذاتية في أفضل أحوالها. وبما أن ذراع مستوى الجهد بيد المشغّل، يمكن خفض رموز مهام غير حساسة للجودة إلى النصف بمستوى High، والاحتفاظ بمستوى Max فقط للمهام بالغة الأهمية، مما يتيح ضبطاً دقيقاً بين التكلفة والجودة.
التطبيق على منصة ThakiCloud للذكاء الاصطناعي والتعلم الآلي على K8s والدلالات
تشغّل ThakiCloud منصة SaaS للذكاء الاصطناعي والتعلم الآلي متعددة المستأجرين قائمة على K8s، وتتولى خدمة النماذج داخل المقر وفي البيئات المعزولة (VPC) دون إخراج بيانات العملاء إلى الخارج. نماذج الاستدلال ذات الأوزان المفتوحة القوية كـGLM-5.2 تتوافق تماماً مع هذه القيمة المقدَّمة.
أولاً، الأمر يتعلق بتحقيق السيادة لا بالتحايل على قيود التصدير. حين تُغلَق نماذج أمريكية مغلقة أمام الوصول الدولي بقرار سياسي، فإن خدمة أوزان برخصة MIT مباشرة داخل مجموعة العميل تضمن سيادة على النموذج لا تتأثر بتغيرات السياسات الخارجية. البيانات والنموذج كلاهما يبقى داخل حدود المستأجر.
ثانياً، قوائم انتظار المعالج الرسومي القائمة على Kueue تلتقي باقتصاديات الرموز. نُدير أعباء عمل المعالج الرسومي متعددة المستأجرين عبر Kueue لتحديد الأولويات وتنسيق الطابور. وبما أن أعباء ذات آثار استدلال أطول تشغل العقدة وقتاً أطول، فإن ربط مستوى الجهد بأولوية الطابور يُمكّن من تحقيق الكفاءة الاقتصادية وهدف زمن الاستجابة معاً من مجمع معالجات رسومية واحد. مهام المستأجرين ذوي الأولوية العالية تعمل بمستوى Max وطابور متقدم، بينما تُعالَج الأعباء الدُّفعية بمستوى High لتعظيم الإنتاجية.
ثالثاً، يتكامل بسلاسة مع مكدّس خدمة vLLM. يوفر GLM-5.2 نقطة نهاية متوافقة مع Anthropic (https://api.z.ai/api/coding/paas/v4) تتصل بها أدوات كـClaude Code وOpenClaw وCline فوراً، لكن الأهم من ذلك إمكانية تلقّي الأوزان مباشرة وتشغيلها عبر vLLM بالتوازي الموتري لـFP8. هذا النمط ذاته الذي نطبقه بالفعل على النماذج المفتوحة الأخرى في منصتنا.
وفي مرحلة النضج، يصبح متاحاً تشغيل عوامل متخصصة بمجال معين باستخدام نماذج استدلال مفتوحة بمستوى GLM-5.2 داخلياً، مما يجمع بين انخفاض تكلفة الخدمة وعدم مغادرة البيانات للبيئة. الرسالة لعملاء المؤسسات الذين يوازنون بين التكلفة والامتثال التنظيمي: التحكم في تكلفة الاستدلال عبر استهلاك المعالج الرسومي لا عبر فاتورة الرموز ميزة تمييز واضحة.
القيود والاعتراضات
ثمة نقاط ضعف ينبغي الإفصاح عنها بصدق.
الاستضافة الذاتية ليست دائماً الأرخص. المعادلة تنقلب فقط عند “آثار طويلة واستدعاءات متكررة”، لا عند أعباء عمل صغيرة متفرقة الاستدعاء. حين تكون الاستدعاءات نادرة، يصبح القسط الثابت لعقدة المعالج الرسومي كبيراً نسبياً، وتغدو واجهة برمجية بالمحاسبة على الرمز أرخص فعلاً. لا يوجد ما هو أكثر تكلفة من إبقاء ثمانية معالجات رسومية في حالة خمول. نقطة التعادل تتوقف كلياً على ملف تعريف عبء العمل.
أرقام الذاكرة السابقة حسابات رياضية خالصة لعدد المعاملات، مستثنيةً ذاكرة KV cache. عند استخدام السياق الكامل البالغ مليون رمز فعلياً، تستنزف ذاكرة KV cache عشرات إلى مئات الجيجابايتات إضافية، مما قد يُضيّق هامش العقدة المنفردة بسرعة. إجمالي التزامن الممكن في الخدمة لا يمكن الجزم به من الأرقام العلنية وحدها، ولم يتسنَّ لنا تشغيل نموذج 744B مباشرة في بيئتنا. أرقام الإنتاجية والتزامن تحتاج إلى قياس فعلي.
نتائج المعايير تحتاج إلى سياق أيضاً. تتباين نتيجة FrontierSWE بين 73 و75% بحسب المصدر، وتفوق معيار واحد لا يضمن التفوق في مهام مجال محدد. أخيراً، أرقام استهلاك الرموز وفق مستوى الجهد (8.5k و85k وغيرها) تتفاوت تفاوتاً كبيراً بحسب نوع المهمة، لذا الصحيح قراءة اتجاه المنحنى “كلما طال الاستدلال كلما كانت محاسبة الرمز أشد وطأة” لا الاستناد إلى القيم المطلقة في الجدول.
ومع ذلك تظل الحجة المحورية صلبة. في حقبة تستهلك فيها نماذج الاستدلال ذات الأوزان المفتوحة القوية رموزاً كثيرة، ينتقل مفتاح التحكم في التكلفة من التفاوض على سعر الرمز إلى اختيار هيكل المحاسبة. محاسبة على الرمز أم على الوقت، وهل تمتلك البنية التحتية التي تجعل هذا الاختيار ممكناً، ذلك هو الفيصل.
المصادر (Sources)
- التغريدة الأصلية (مصدر الملخص): @hjguyhan, 2026-06-22
- تحليل GLM-5.2: felloai: GLM 5.2: Zhipu’s 1M-Context Open-Source Model Explained
- معايير وأسعار GLM-5.2: labellerr: GLM-5.2 Just Beat GPT-5.5 at a Sixth of the Cost
- الأوزان الرسمية: GitHub: zai-org/GLM-5
- مقال ذو صلة (التكميم): Unsloth GLM-5.2 1بت Dynamic GGUF تحليل داخل المقر