Building Your First AI Agent - Start with a Minimal Guarded Loop
Beginner guides titled “How to build your first AI agent” have a steady following. The good ones typically break an agent into four pieces: the LLM brain that handles reasoning, memory that holds state, tools that interact with the outside world, and the agent loop that ties all three together in repetition. The ReAct pattern - alternating between reasoning and acting - usually comes along as the de facto standard. All of that is correct. But when you actually run agents in production, the part that breaks is different. It is the guardrails that decide when to stop the loop. This post runs a minimal agent loop with guardrails in pure Python, calling no external LLM, and shows the difference in real numbers.
Overview
An agent loop is fundamentally a while loop. It observes, decides on the next action, executes a tool, and observes the result again. In the happy path that beginner materials show, this loop turns a few times, produces an answer, and exits. The problem is the unhappy path. In real operations, it is common for a model to call the same tool infinitely, hang on a task that never ends, or have a single request hold a GPU hostage. Guardrails are the mechanism that blocks this runaway behavior at the code level.
ThakiCloud runs agents and batch jobs from multiple customers on the same GPU pool in a multitenant environment. In that context, guardrails are a prerequisite, not an option. A runaway loop from one tenant cannot be allowed to paralyze the entire pool. That is why “how do you stop an agent loop” matters more from an operations perspective than “how do you build an agent.” This post shares the results of implementing that stopping mechanism in its smallest form and running it directly.
What This Technique Is
The skeleton of a ReAct loop is simple. A policy looks at the current state and decides what to do next. If it calls for a tool, the tool runs and produces an observation. If it calls for finishing, an answer is returned. In a real agent the policy is an LLM, but the control structure of the loop itself is independent of the model. So in this experiment the policy is replaced by a rule-based stub - to observe the control plane of the loop, not the model quality - which makes the results fully reproducible.
Guardrails add three stopping conditions to this loop. The step limit (max_steps) forces the loop to stop after a set number of iterations. The time budget (wall_budget) constrains wall-clock time per task. Repeat detection (repeat_guard) cuts the loop when the same action repeats, judging it a loop trap. Every task ends with exactly one termination reason: finished, max_steps, wall_budget, repeat_guard, or no_action.
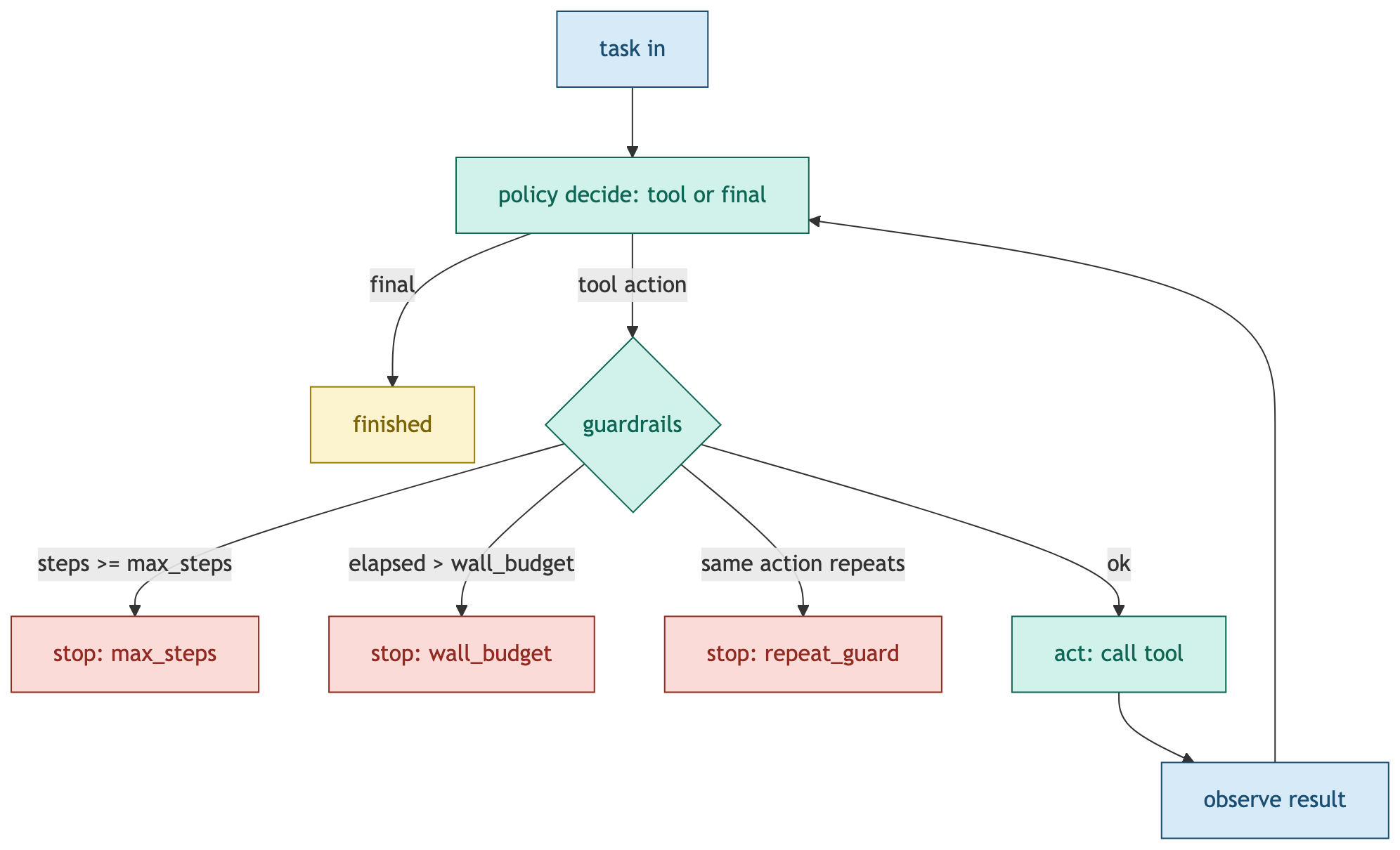
The key point in this diagram is that guardrail checks happen before every tool execution. Placing guardrails outside the loop or checking them after the fact means runaway behavior has already started. Checking on every iteration, immediately before each action, is what guarantees a stop.
Setup and Integration
This experiment has no external dependencies. It uses only the Python standard library, so no additional installation is needed. The policy picks a tool by applying regex to the task string, and there are two tools: a safely bounded arithmetic calculator and a small knowledge lookup.
@dataclass
class Guards:
max_steps: int = 6
wall_budget_s: float = 2.0
repeat_limit: int = 2
def run_task(task: str, g: Guards) -> Trace:
t0 = time.perf_counter()
tr = Trace(task=task)
repeats: dict[str, int] = {}
while True:
if tr.steps >= g.max_steps:
tr.terminal = "max_steps"; break
if (time.perf_counter() - t0) > g.wall_budget_s:
tr.terminal = "wall_budget"; break
act = policy(task, tr.scratch)
if "final" in act:
tr.answer = act["final"]
tr.terminal = "finished" if act["final"] is not None else "no_action"
break
sig = f"{act['tool']}:{act['input']}"
repeats[sig] = repeats.get(sig, 0) + 1
if repeats[sig] > g.repeat_limit:
tr.terminal = "repeat_guard"; break
obs = TOOLS[act["tool"]](act["input"])
tr.scratch.append({"tool": act["tool"], "input": act["input"], "obs": obs})
tr.steps += 1
tr.latency_ms = round((time.perf_counter() - t0) * 1000, 3)
return tr
Looking at the loop structure, all guardrails are placed immediately before each action. The step limit and time budget are checked at loop entry, and repeat detection is checked right before the tool call. When the policy says to finish, the loop exits immediately. Otherwise, only actions that pass the guardrails are executed. Run it with this single line:
.venv/bin/python scripts/experiments/minimal-guarded-agent-loop/agent_loop.py
The task set includes four tasks that complete normally, plus one loop-trap task deliberately designed to repeat the same lookup forever. Whether that trap task is caught by repeat detection is the central verification of this experiment.
Actual Experiment Results
Here are the real results from running five tasks. Guardrails were set to step limit 6, time budget 2.0 seconds, and repeat limit 2.
{
"n_tasks": 5,
"by_terminal": { "finished": 4, "repeat_guard": 1 },
"total_latency_ms": 0.115,
"total_steps": 7
}
The key is the termination reason distribution. Four tasks finished normally and one was blocked by repeat detection. The deliberately planted “loop forever please” task kept trying the same lookup and was stopped at exactly step 2 by repeat detection. The moment the same action exceeded the limit, the loop cut off. Without guardrails, this task would never have ended, with the policy insisting on the same action forever.
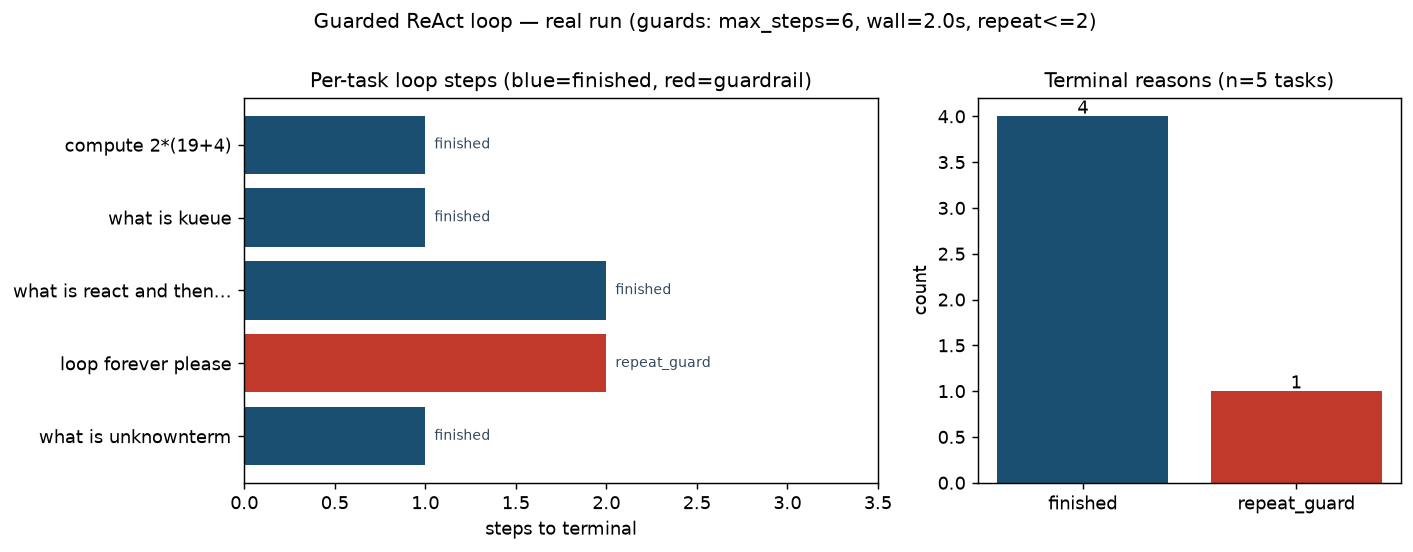
The left bar shows steps taken to termination per task. Normal tasks finished in 1 or 2 steps, and only the task requiring both calculation and lookup needed 2 steps. The right side shows the termination reason distribution, confirming that one of five tasks was stopped by a guardrail. Total processing time was 0.115 milliseconds - since there are no LLM calls, the cost of loop control itself is essentially zero. This reveals something important: the cost of adding guardrails is negligible, and the cost of omitting them is the entire runaway loop.
These numbers do not measure model performance. Since the policy is fixed as rules, what is being measured is the control plane. But with a real LLM plugged in, the guardrail behavior is exactly the same. No matter what the model outputs, step limits, time budgets, and repeat detection are enforced by code outside the model. The essence of this architecture is that stopping is owned by code, not delegated to the model’s goodwill.
Application to ThakiCloud’s K8s AI/ML SaaS Platform
This minimal loop may look like a toy, but the principles it embodies are the same as the core of production agent operations. The principle is that stopping is the infrastructure’s responsibility, not the model’s. In ThakiCloud’s operations stack, this principle appears at two levels.
At the application level, the in-loop guardrails just seen are at work. Step limits and repeat detection prevent runaway behavior from a single request inside the agent code. At the infrastructure level above that, Kueue performs the same role at the resource dimension. When an agent task requests a GPU, Kueue queues it and schedules it when resources are free, and tasks exceeding per-tenant quotas are queued or preempted. So no matter how many tasks one tenant’s agent throws at the system, code blocks the time budget and Kueue blocks the resource limit. Two guardrails at different layers doubly block the same runaway behavior.
Auditability follows naturally. In this experiment, every task left an explicit termination reason on record. Whether it finished normally, was blocked by repeat detection, or timed out is recorded structurally. Extending this pattern to production means every action and termination reason from an agent is logged, and who stopped what, when, and why is traceable. In environments that assume on-premises and sovereign deployments, this traceability is a prerequisite for adoption by public sector or regulated industry customers. A system that cannot explain what its agents did is by definition not deployable.
To summarize: the most important thing to learn when building a first agent is not how to connect tools, but how to stop the loop. Guardrails are not a safety feature added later - they need to be part of the loop from the start. And placing those guardrails at both the application and infrastructure layers is how you safely operate agents on a multitenant GPU platform.
Limitations and Counterarguments
This experiment has clear limitations. First, because the policy is fixed as rules, the unpredictability that real LLMs introduce is not measured. A real model may call the wrong tool, produce malformed inputs, or extend reasoning endlessly through hallucination. The results here only show that guardrails guarantee a stop in those cases too - they do not guarantee the model gets smarter.
Second, guardrails prevent runaway behavior but do not produce quality. A task stopped by a step limit ended safely but failed to produce an answer. Setting guardrails too tight cuts normal long-running tasks as well; setting them too loose means runaway behavior is not blocked quickly enough. The right thresholds must be tuned to task characteristics, and this is an ongoing operational challenge rather than a one-time setting.
Third, real systems need more types of guardrails. Token budgets, cost ceilings, per-tool call limits, and external call timeouts are all needed. This minimal implementation covered three, but the principle extends identically. Stopping conditions are owned by code outside the model, and they are checked on every iteration, immediately before each action. Adding this fifth piece - guardrails - to the four pieces beginner guides show is the difference that lifts a first agent from a toy to an operable system.
Sources
- Original introductory thread: How to build your first AI agent by @eng_khairallah1
- Agent execution loop concept: The Agent Execution Loop (Victor Dibia)
- ReAct and LLM agents overview: Prompt Engineering Guide - LLM Agents
- Experiment code:
scripts/experiments/minimal-guarded-agent-loop/agent_loop.py(this repository)