DiffusionGemma 26B-A4B: تجربة Google في توليد 15 إلى 20 رمزاً دفعةً واحدة عبر الانتشار النصي المتقطع
⏱️ وقت القراءة المقدر: 9 دقائق
ما الجديد
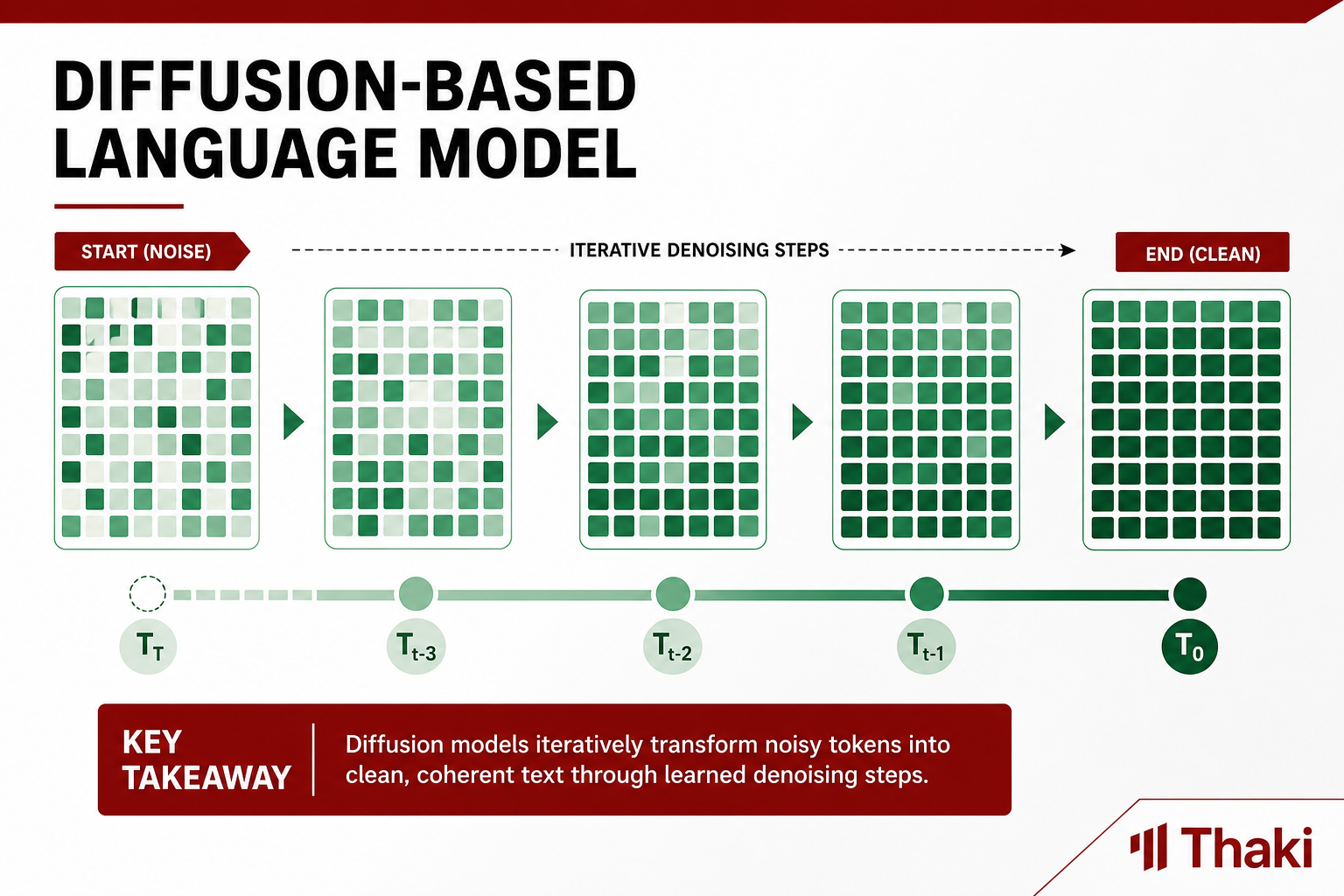
أطلق Google DeepMind نموذج google/diffusiongemma-26B-A4B-it. يشير الاسم إلى أن البنية مستندة إلى Gemma، بيد أن آلية توليد النصوص مختلفة جذرياً. تعتمد نماذج اللغة التقليدية على التوليد التلقائي التسلسلي، إذ تتنبأ برمز واحد في كل مرة من اليسار إلى اليمين. أما DiffusionGemma فيستخدم الانتشار النصي المتقطع (discrete text diffusion): يصفّي تسلسلاً مشوشاً تكراراً حتى يصل إلى النص النهائي.
من حيث سرعة التوليد الفعلية، يُنتج النموذج 15 إلى 20 رمزاً في وقت واحد خلال تمرير أمامي واحد. تشير بطاقة النموذج إلى تجاوز 1,100 رمز في الثانية على H100 FP8 مع دُفعات صغيرة، وهذه الأرقام صادرة عن Google وتتفاوت بحسب تكوين الأجهزة وحجم الدُّفعة.
الرخصة Apache-2.0، مما يتيح الاستخدام التجاري وتوزيع النماذج المشتقة.
البنية
تفاصيل المعاملات:
- إجمالي المعاملات: 25.2 مليار
- المعاملات النشطة: 3.8 مليار
- عدد الطبقات: 30
- الخبراء: 128 إجمالاً، 8 نشطة و1 مشتركة
- حجم المفردات: 262,144
- مشفّر الرؤية: نحو 550 مليون معامل
- نافذة الانزلاق: 1,024 رمز
- طول اللوحة: 256
- السياق: يصل إلى 256K رمز
البنية من نوع مشفّر-فكّ تشفير مع انتباه ثنائي الاتجاه. يختلف هذا عن الانتباه أحادي الاتجاه في نماذج اللغة السببية القياسية، إذ يمكن للنموذج رؤية التسلسل كاملاً في آنٍ واحد. هذا، مقروناً بالانتشار المتقطع، يشكّل الأساس الذي يُتيح توليد رموز متعددة في تمرير واحد.
يقبل النموذج الصور والفيديو إضافةً إلى النصوص، ويدعم الصور بدقة وأبعاد متغيرة.
دُرّب النموذج على أكثر من 140 لغة، ويدعم صراحةً أكثر من 35 لغة، وتاريخ انتهاء بيانات التدريب يناير 2025.
المعيارية
الأرقام الواردة في بطاقة النموذج مأخوذة من النسخة المضبوطة بالتعليمات (instruction-tuned) باستخدام Entropy Bound sampler.
| المعيار | النتيجة |
|---|---|
| MMLU Pro | 77.6% |
| AIME 2026 (بدون أدوات) | 69.1% |
| LiveCodeBench v6 | 69.1% |
| GPQA Diamond | 73.2% |
| BigBench Extra Hard | 47.6% |
| MMMU Pro (رؤية) | 54.3% |
| MATH-Vision | 70.5% |
تُعدّ نتيجة 69.1% على AIME 2026 و73.2% على GPQA Diamond أداءً قوياً في الاستدلال الرياضي وحل المسائل العلمية. وهي أرقام لافتة بالنظر إلى أن المعاملات النشطة 3.8 مليار فقط، مع ضرورة التذكير بأن المعيارية تمثّل دائماً لقطةً في ظروف محددة.
خصوصيات النشر على Kubernetes
تؤثر آلية التوليد المغايرة للنماذج التلقائية التسلسلية في البنية التحتية للتقديم.
نمط ذاكرة التخزين المؤقت KV يختلف. تخزّن النماذج التلقائية التسلسلية مفاتيح وقيم الرموز المولّدة بشكل تسلسلي لاستخدامها في التنبؤ بالرموز التالية. أما الانتشار المتقطع فيصفّي التسلسل كاملاً بصورة متكررة، لذا لا ينطبق عليه آلية KV القياسية كما هي. يستلزم ذلك التحقق الميداني من آلية عمل تحسينات PagedAttention في vLLM وSGLang.
خصائص المعالجة الدُّفعية مختلفة. في النماذج التلقائية التسلسلية، تُعالَج الأطوال المتباينة ضمن الدُّفعة بالحشو أو التجميع المستمر. في نماذج الانتشار، يتفاوت وقت المعالجة بحسب خطوات الانتشار وطول اللوحة. قد تختلف توزيعات زمن المعالجة عن تلك الخاصة بالنماذج التلقائية التسلسلية.
ذاكرة الاستدلال. يحتاج النموذج نحو 50.4 جيجابايت من ذاكرة VRAM بتنسيق BF16 الكامل البالغ 25.2 مليار معامل. يندرج ذلك ضمن A100 80GB أو H100 80GB واحدة حتى مع إضافة مشفّر الرؤية البالغ 550 مليون معامل. يمنح تصميم المعاملات النشطة البالغة 3.8 مليار ميزةً على النماذج الكثيفة ذات 25 مليار من حيث الإنتاجية.
تشمل أطر العمل الرسمية المدعومة: Transformers وvLLM وSGLang وDocker Model Runner، فضلاً عن 26 متغيراً من التكميم المتاحة.
# مثال على التقديم عبر vLLM
vllm serve google/diffusiongemma-26B-A4B-it \
--dtype bfloat16 \
--max-model-len 32768
نظراً لطبيعة نموذج الانتشار المتقطع، ينبغي التحقق من التوافق مع إصدار vLLM أولاً؛ إذ لا تعمل بعض الميزات المحسّنة للنماذج التلقائية التسلسلية القياسية بالضرورة مع هذا النوع.
يدعم النموذج وضع التفكير (thinking mode) ويدعم موجّه النظام واستدعاء الدوال بشكل أصلي.
منظور ThakiCloud
بيئة تجريبية لنموذج استدلال الانتشار. يلائم DiffusionGemma البحث التجريبي في نماذج الاستدلال أكثر مما يلائم أعباء الإنتاج الحالية. يمكن على منصة ThakiCloud إنشاء WorkloadClass معزولة في Kueue للتجارب، وقياس الإنتاجية الفعلية والجودة مقارنةً بالنماذج التلقائية التسلسلية جنباً إلى جنب. الأولوية هي جمع البيانات حول الفوارق التي يُحدثها الانتشار المتقطع في أنواع مهام بعينها.
السياق 256K ومتعدد الأوضاع. يتيح سياق 256K ودعم إدخال الصور والفيديو معالجة المستندات الطويلة وتحليل قواعد الشفرات الضخمة. كما أن رخصة Apache-2.0 لا تفرض قيوداً على الاستخدام التجاري وتطوير النماذج المشتقة، وهو ما يصبّ في مصلحة التكامل داخل البنية التحتية الخاصة.
لا يزال نظام بيئة الانتشار للنماذج اللغوية أقل نضجاً مقارنةً بالنماذج التلقائية التسلسلية. تبقى مرحلة التحقق المباشر من وضع دعم أطر التقديم لنماذج الانتشار، وفعالية التكميم، واستقرار النشر الفعلي ضرورةً لا غنى عنها.