FastContext-1.0-4B-SFT: نموذج وكيل فرعي بحجم 4 مليار معامل مخصص لاستكشاف مستودعات الشفرات في وكلاء البرمجة
⏱️ وقت القراءة المقدر: 7 دقائق
ما الجديد
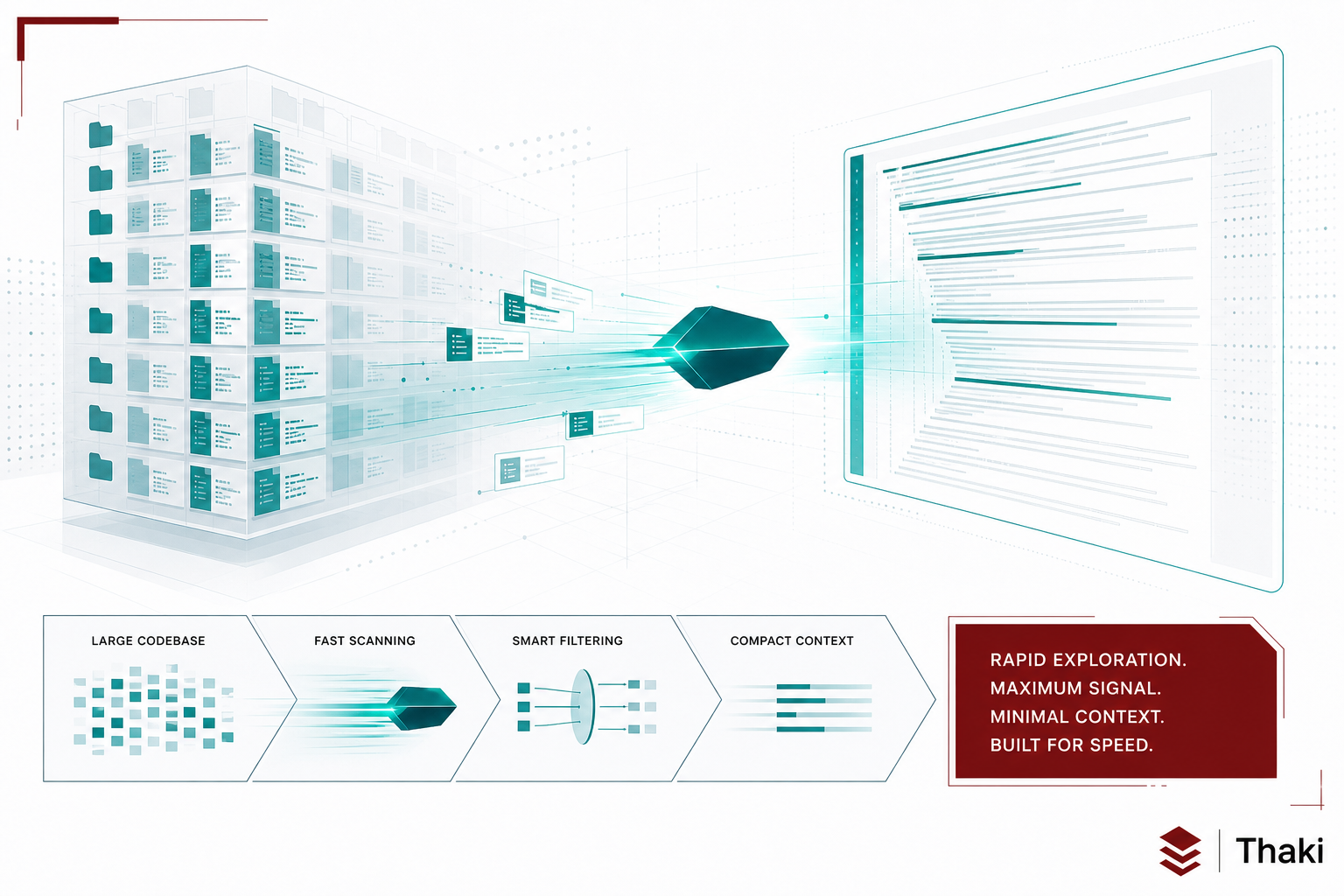
أطلقت Microsoft نموذج microsoft/FastContext-1.0-4B-SFT. الورقة البحثية المرتبطة به هي arXiv:2606.14066 بعنوان “FastContext: Training Efficient Repository Explorer for Coding Agents”. دور هذا النموذج واحد فقط: حين يتلقى وكيل برمجة مهمةً ما، يتولى الوكيل الفرعي FastContext مسح المستودع بأكمله لاستخراج الملفات وأجزاء الشفرات ذات الصلة.
البساطة ميزة هنا. يعتمد النموذج ثلاثة أدوات فقط: READ وGLOB وGREP، أي قراءة الملفات والبحث عن المسارات والبحث في النصوص. لا عمليات كتابة. حين يكتب الوكيل الرئيسي الشفرة ويتخذ القرارات، يقتصر دور FastContext على توفير السياق اللازم له.
لماذا نحتاج نموذجاً مخصصاً؟ في معيارية وكلاء البرمجة كـ SWE-bench، تستهلك مرحلة استكشاف المستودع نصيباً كبيراً من إجمالي الرموز. إذا أجرى النموذج الرئيسي (مثل GPT-5.4 أو GLM-5.1) الاستكشاف بنفسه، ارتفعت التكلفة وانخفضت السرعة. تفويض الاستكشاف إلى نموذج صغير بحجم 4 مليار معامل يخفّض التكلفة ويرفع دقة خط الأنابيب الكلية.
البنية
النموذج الأساسي هو Qwen/Qwen3-4B-Instruct-2507، بحجم 4 مليار معامل وطول سياق 262K رمز، بتنسيق BF16.
اعتمد التدريب على ضبط دقيق موجّه (SFT) مع تعلم تعزيزي (GRPO). تتضمن بيانات التدريب ثلاثة مصادر وفقاً للورقة البحثية وبطاقة النموذج:
parallel_toolcalls: أنماط الاستكشاف الواسع لملفات متعددة في الدور الأولmultiturn_traj: أنماط جمع الأدلة عبر أدوار متعددةlinerange: أنماط الاستشهاد بنطاقات سطور دقيقة
تعكس هذه المصادر السلوك الفعلي للوكيل أثناء التشغيل، مما يُجسّد مبدأ تكييف أسلوب الاستكشاف بحسب السياق في تصميم بيانات التدريب.
تشمل عائلة النماذج: FC-4B-SFT (هذا النموذج) وFC-4B-RL وFC-30B-SFT المستند إلى Qwen3-Coder-30B-A3B.
المعيارية
تعكس الأرقام الواردة في بطاقة النموذج والورقة البحثية التغيير الحاصل عند إضافة FastContext وكيلاً فرعياً للوكيل الرئيسي، مقارنةً بالعمل دون استكشاف (w/o Explore).
| الوكيل الرئيسي | المعيار | تغيير الدقة | تغيير الرموز |
|---|---|---|---|
| GPT-5.4 | SWE-bench Multilingual | +3.3% | -26.0% |
| GLM-5.1 | SWE-bench Pro | +5.0% | غير متاح |
| Kimi-K2.6 | SWE-bench Multilingual | +2.0% | غير متاح |
الخلاصة: ارتفاع الدقة مع انخفاض الرموز. توفير 26% من الرموز بالنسبة لـ GPT-5.4 له دلالة واضحة من منظور التكلفة. حين يتولى النموذج ذو 4 مليار معامل الاستكشاف الشامل بكفاءة، يتفرغ الوكيل الرئيسي لكتابة الشفرات واتخاذ القرارات.
كود المستودع متاح على https://github.com/microsoft/fastcontext.
التقديم والنشر
الرخصة MIT، مما يتيح الاستخدام التجاري والتعديل والتوزيع بحرية.
متطلبات الموارد منخفضة بحجم 4 مليار معامل: نحو 8 جيجابايت VRAM بتنسيق BF16، مما يجعله متوافقاً مع A100 40GB وA10G 24GB وRTX 4090 24GB. يدعم vLLM وSGLang رسمياً، وتتوفر متغيرات مُكمَّمة لـ llama.cpp وOllama وLM Studio وJan.
غرافيكا GPU واحدة كافية لتقديم vLLM:
vllm serve microsoft/FastContext-1.0-4B-SFT \
--dtype bfloat16 \
--max-model-len 131072
لاستخدام السياق الكامل البالغ 262K، يلزم حساب ذاكرة VRAM وذاكرة تخزين مؤقت KV. في الغالب تكون أطوال السياق المطلوبة في مهام استكشاف المستودعات الفعلية أقصر من ذلك، لذا يُستحسن قياس طول p95 في أنماط الاستخدام الفعلية أولاً قبل تحديد max-model-len.
منظور ThakiCloud وربطه بـ subagent-model-routing
فصل أدوار الوكيل الفرعي في خط الأنابيب. تنص قاعدة subagent-model-routing في منصة ThakiCloud على استخدام نماذج صغيرة كـ Haiku لمهام الاستكشاف وقراءة الملفات. FastContext هو النموذج المخصص لهذا الدور تحديداً. يمكن استخدام claude-sonnet أو نموذج كبير آخر وكيلاً برمجياً رئيسياً، بينما يُوصل FastContext-4B كنقطة نهاية vLLM محلية وكيلاً فرعياً للاستكشاف.
# مثال على WorkloadPriorityClass في Kueue
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
name: fastcontext-inference
namespace: ai-agents
spec:
clusterQueue: small-gpu-queue
بمتطلباته المنخفضة، يناسب النموذج ذو 4 مليار معامل طابور GPU الصغير في Kueue من حيث الكفاءة التكلفية. يعمل FastContext بطابور صغير مستقل في حين يستخدم الوكيل الرئيسي طابور GPU الكبير.
مسار خفض التكلفة. إذا كان النصيب الأكبر من رموز مهام وكيل البرمجة في منصة ThakiCloud يُنفَق حالياً على استكشاف المستودعات، يمكن لـ FastContext تقليص رموز الوكيل الرئيسي. مدى تحقق توفير 26% المستند إلى SWE-bench في أعباء العمل الفعلية يتوقف على خصائص قاعدة الشفرات الداخلية، لذا يجب إجراء قياس تجريبي أولاً.
رخصة MIT تتيح النشر المحلي والضبط الدقيق معاً. ضبط النموذج إضافياً بما يتناسب مع لغات قاعدة الشفرات الداخلية أو بنيتها قد يرفع دقة الاستكشاف. تنسيقات بيانات التدريب (parallel_toolcalls وmultiturn_traj وlinerange) متاحة للعموم، مما يُتيح بناء مجموعة بيانات مماثلة من آثار استكشاف المستودع الداخلي.