قياس الأثر الاقتصادي للذكاء الاصطناعي بما يتجاوز تحليل السجلّات: قراءة في تقرير Anthropic Economic Index «Cadences»

نظرة عامة
ما إن تُدخِل منصّة ذكاء اصطناعي إلى مؤسسة حتى تجد نفسك أمام سؤال واحد: «إذًا، كم ساعدت فعلًا؟». حتى الآن، كان الجواب في الغالب مقاييس النظام: كم عدد استدعاءات الـ API، وكم مهمة عولِجت، وكم ملّي ثانية استغرقت الاستجابة. الأرقام نظيفة، لكنها لا تبلغ ما تريد الإدارة معرفته حقًّا: «ما الذي أنتجته منظمتنا فعليًّا بقدر أكبر؟».
لهذا فإن تقرير Economic Index «Cadences» الذي نشرته Anthropic في 26 يونيو 2026 جدير بالاهتمام. فهو ليس تحديثًا روتينيًّا لإحصاءات الاستخدام، بل يُعلن صراحةً أن طريقة قياس الأثر الاقتصادي للذكاء الاصطناعي نفسها قد تغيّرت. انطلاقًا من إدراك أن سجلّات المحادثة وحدها لا تكفي لتفسير أثر الذكاء الاصطناعي في العمل، يوسّع التقرير أساس القياس عبر ثلاثة مسارات.
بالنسبة لشركة مثل ThakiCloud التي تُشغّل فعليًّا منصّة ذكاء اصطناعي/تعلّم آلي متعددة المستأجرين على Kubernetes، ليس هذا التحوّل قصة الآخرين. فالتقرير يُظهر بالبيانات الانتقال في طريقة شرح العائد للعملاء من «مقاييس النظام» نحو «مخرجات العمل وإدراك الموظفين». ينظّم هذا المقال التحوّلات المنهجية الثلاثة استنادًا إلى المادة الرسمية للتقرير، ويتأمّل ما يمكننا أخذه منها كمنصّة.
ما هذا التقرير؟
حلّلت Anthropic استخدام Claude عبر Economic Index منذ 2023. واتّكأت كل التقارير السابقة على بيانات عيّنة من سبعة أيام: اقتطاع أسبوع وفحص أنماط الاستخدام داخله. قبل عام، كان معظم استخدام Claude محادثةً بين مستخدم ومساعد، فكانت هذه الطريقة تلتقط صورة معقولة.
لكن مع النمو السريع لـ Claude Code وCowork، تحوّلت حصّة كبيرة من الجلسات إلى مهام وكيلة طويلة الأمد. ولم تعد سجلّات المحادثة تلتقط بالكامل كيف يستخدم الناس الذكاء الاصطناعي. تقول Anthropic إنها أعادت تصميم خط بياناتها في ثلاثة اتجاهات لمواكبة ذلك: رفع معدّل أخذ العيّنات لرؤية الأنماط حتى مستوى الساعة، وإدخال مصنِّف جديد يُعنوِن مخرَج كل محادثة، وتفصيل نتائج المحادثات/Cowork وواجهة 1P API شهريًّا لمزيد من الدقّة.
ويُضاف مسار آخر. تُقرّ Anthropic بأنها افتقرت إلى رؤية الأثر خارج جلسات المستخدم، أي كيف يُدرك الناس الذكاء الاصطناعي. لذا تعرض النتائج الأولية لـ استبيان المؤشر الاقتصادي الذي أُطلق في أبريل 2026. باختصار، يقوم التقرير على ثلاثة محاور: الإيقاعات بالساعة، وتصنيف المخرجات، واستبيان الإدراك.
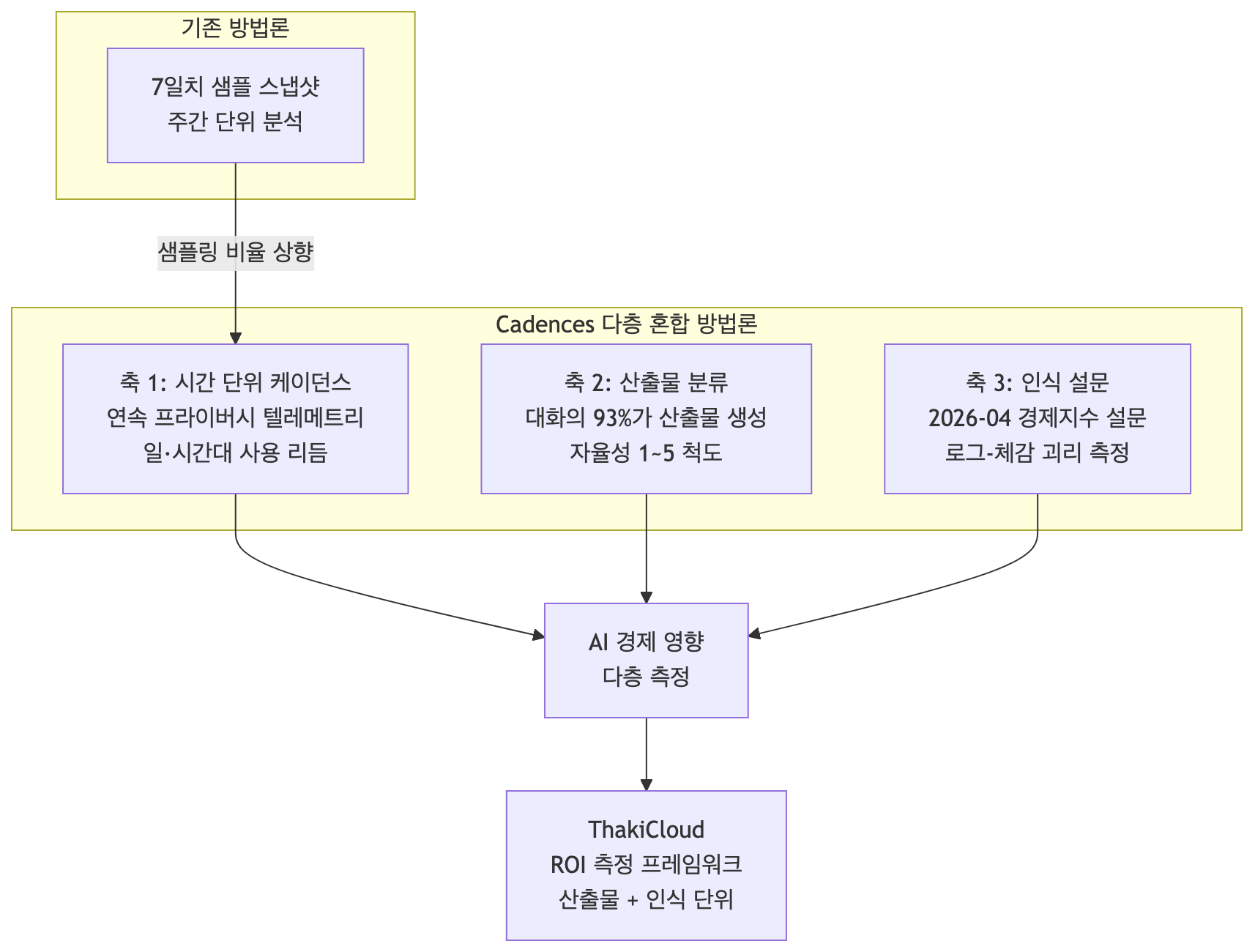
المحور الأول: الإيقاعات بالساعة
أبرز تغيير هو إدخال قياس عن بُعد يحفظ الخصوصية. فبأخذ عيّنة من شريحة من المحادثات يوميًّا وباستمرار، يلتقط التدفّقات اليومية والساعِيّة، خلافًا للقطات السبعة أيام السابقة. تتيح هذه البيانات، للمرة الأولى، رؤية كيف تنعكس إيقاعات الحياة اليومية في استخدام Claude.
النتائج بديهية وجديدة في آنٍ معًا. يتتبّع استخدام Claude نمط أيام العمل، بينما ترتفع الطلبات الشخصية في عطلة نهاية الأسبوع. وعند النزول ساعةً بساعة يزداد الوضوح: يطلب الناس نصائح النوم غالبًا قرابة الخامسة فجرًا، ويسألون عن الوصفات قرابة السادسة مساءً، وتتجمّع طلبات الأخبار في الصباح. كما تتفاعل الأنماط مع تواريخ بعينها: ارتفعت الطلبات المتعلقة بالضرائب قبيل الموعد النهائي الأمريكي للإقرار الضريبي في 15 أبريل.
وتظهر فروق بحسب طبيعة العمل أيضًا. حين يلجأ الناس إلى Claude للعمل ليلًا وفي العطلات، تميل تلك المهام نحو المهن الأعلى أجرًا، مثل مديري التسويق أو المبرمجين، الأكثر احتمالًا للعمل خارج الساعات التقليدية. في المقابل، تتراجع حصّة مهام الرُّبعين الأدنى أجرًا، كالتسويق الهاتفي والأعمال الكتابية، ليلًا وفي العطلات. وتضيف Anthropic أن النمط يصمد حتى في اختبار متانة يستبعد المهن الحاسوبية والرياضية. إنها إشارة إلى أن الذكاء الاصطناعي يعمل لا كأتمتة بسيطة بل كأداة مساعِدة لعمل عالي المهارة.
المحور الثاني: مصنِّف المخرجات (Artifact)
التحوّل الثاني هو تصنيف مخرجات المحادثات. صنّفت Anthropic ما يُنتجه كل من محادثات الدردشة وCowork من مخرَج (artifact) ضمن أكثر من 30 فئة: مستند، شرح، مقطع شيفرة، ورقة أكاديمية، وهكذا، أي المخرَج الأساسي الذي أنتجه Claude في تلك المحادثة.
حكم المصنِّف بأن 93% من محادثات Claude تُنتج مخرَجًا. وأكثر الأنواع شيوعًا هي الشروحات (17%)، والمستندات والتقارير (15%)، والإرشادات (11%). وتمثّل المخرجات الحوارية كالشروحات أو الإرشادات والمخرجات المكتوبة كالمستندات أو العروض نحو الثلث لكلٍّ منها، بينما تمثّل مخرجات الشيفرة والتقنية كالتطبيقات أو السكربتات نحو السدس.
وتتبع ذلك نتيجة ثانية، هي درجة الاستقلالية (autonomy). تقيس Anthropic مقدار ما يُفوَّض إلى Claude من حُكم على مقياس من 1 إلى 5. فالمهام ذات الإجابات المحدّدة سلفًا، كالترجمة أو الحساب، استقلاليتها منخفضة، أما المهام التي تتطلّب الاختيار من بدائل كثيرة، كبناء التطبيقات أو الألعاب أو العروض، فاستقلاليتها مرتفعة.
ويُقاس المخرَج نفسه باستقلالية أعلى حين يُصنع عبر Claude Code. ففي 26 من أصل 31 مخرَجًا معروضًا كانت الاستقلالية أعلى على Claude Code منها على الدردشة أو Cowork، بفارق متوسّط قدره 0.37 نقطة. وفي السكربتات ومقاطع الشيفرة يتّسع الفارق إلى 0.53 نقطة. ونحو ثلثي هذا الفارق يأتي من تنفيذ المهام نفسها بتفويض أكبر. وتمثّل التدوينات مثالًا جيّدًا: المحادثة الوسيطة على الدردشة/Cowork لإنتاج تدوينة تمرّ بـ 13 جولة من الأخذ والردّ، بينما على Claude Code يفوّض الناس قدرًا أكبر من الحُكم. بعبارة أخرى، يمنح المستخدمون الذكاء الاصطناعي استقلالية أكبر.
المحور الثالث: استبيان الإدراك
المحور الثالث بيانات مستمدّة لا من السجلّات بل بسؤال الناس مباشرةً. أطلقت Anthropic استبيان المؤشر الاقتصادي في أبريل 2026، فسألت مستخدمي Claude الفعليين كم من عملهم يستطيع الذكاء الاصطناعي إنجازه. وتُربَط إجابات الاستبيان ببيانات الاستخدام عبر طرق تحفظ الخصوصية.
سُئل المشاركون عن حصّة مهام عملهم التي يستطيع الذكاء الاصطناعي إنجازها بمفرده اليوم (الانكشاف المُبلَّغ)، والحصّة التي يتوقّعون أن يتولّاها خلال 12 شهرًا (الانكشاف المتوقَّع). اختار ما يقارب 6 من كل 10 مشاركين نطاقًا أعلى للعام المقبل، ويتوقّع أكثر من الثلث أن يستطيع الذكاء الاصطناعي إنجاز معظم مهام عملهم أو كلّها تقريبًا العام المقبل.
والفروق بين الفئات واضحة. مال المشاركون في الدول الأقل دخلًا إلى الشعور بأن الذكاء الاصطناعي قادر على استبدال قدرٍ أكبر من عملهم. وتستشهد Anthropic بأبحاث سابقة تُظهر أن هذه الدول تميل إلى استخدام Claude بطرق أكثر أتمتة. كما تظهر فروق بحسب الخبرة: وضع أصحاب الخبرة 15 عامًا فأكثر حصّة المهام التي يستطيع الذكاء الاصطناعي إنجازها أدنى بنحو 10 نقاط مئوية من حديثي العهد في عامهم الأول، مع تفسير أن ذوي الخبرة راكموا خبرة ضمنية مرتبطة بالسياق يصعب على الذكاء الاصطناعي محاكاتها. وذكر المشاركون أن الحُكم والوعي بالسياق والاستدلال الموقفي والأبعاد العلائقية لبناء الثقة وإدارة الناس أمور لا يستطيع الذكاء الاصطناعي القيام بها. وتركّز القلق من الإحلال لدى العاملين في بداية مسارهم المهني وذوي الأجور المنخفضة.
دلالات لمنصّة ThakiCloud للذكاء الاصطناعي/التعلّم الآلي كخدمة على K8s
ما يقدّمه هذا التقرير لـ ThakiCloud لا يكمن في ميزة بل في إطار قياس. ينطلق نهج Anthropic من فرضية أن «السجلّات وحدها لا تكفي لتفسير قيمة الذكاء الاصطناعي»، وهو منظور يمكننا تطبيقه مباشرةً كمشغّل منصّة ذكاء اصطناعي للمؤسسات.
حتى الآن، ركّزنا نحن أيضًا في شرح العائد على مقاييس النظام: عدد الاستدعاءات، والإنتاجية، وسرعة الاستجابة. لكن هذا التقرير يطرح أسئلة على طبقة مختلفة. ما الذي أُنتج في تلك المحادثة؟ هل صُنع المخرَج في ساعات العمل أم أثناء عمل إضافي ليلي؟ كم من الاستقلالية فوّضها المستخدم للذكاء الاصطناعي؟ وكم يشعر المستخدمون أنفسهم أن الذكاء الاصطناعي يحلّ محلّ عملهم؟
هذه الأسئلة قابلة للقياس على بنيتنا. تتولّى ThakiCloud في مكان واحد جدولة وحدات معالجة الرسوميات القائمة على Kubernetes وKueue، وخدمة vLLM، وتشغيل الوكلاء متعدد المستأجرين. وبإضافة طبقة من مصنِّف المخرجات إلى القياس عن بُعد المنبثق من هذه البنية، يمكننا التقاط متى وبأيّ صورة يُنتج موظفو العميل مخرجات بمشاركة الذكاء الاصطناعي. عندها نشرح أثر الذكاء الاصطناعي لا بعبارة «تحسين الكفاءة» المجرّدة بل بوحدات مخرجات ملموسة. ويمكن أن تصبح ملاحظة ارتفاع مهام الأجور العالية في النوبات الليلية مؤشرًا لما إذا كان الذكاء الاصطناعي يستقرّ كأداة مساعِدة لعمل عالي المهارة في مؤسسات عملائنا أيضًا.
كذلك تستحقّ طريقة ربط الاستبيان بالسجلّات الاقتباس. فقياس الفجوة بين بيانات الاستخدام الفعلية والقدرة المُدرَكة يكشف أيّ الفئات تستفيد أكثر بعد تبنّي الذكاء الاصطناعي وأيّها تشعر بالقلق. وهي رؤية تُغذّي مباشرةً استراتيجية إدارة التغيير الداخلية لدى العميل. وبالنسبة للعملاء المحلّيين الذين يجب أن يقيسوا داخل البنية المحلّية دون إرسال البيانات إلى الخارج، فإن تصميم القياس الحافظ للخصوصية متطلّب لا خيار، وبنية العزل متعدد المستأجرين والاستضافة الذاتية لدينا تنطبق على هذا المتطلّب تمامًا.
في النهاية، اتجاه Anthropic هو التزام بمواصلة صقل كيفية قياس الأثر الاقتصادي للذكاء الاصطناعي. وأحد أقوى ما يميّز ThakiCloud هو دور الشريك الذي يتجاوز توفير منصّة إلى المشاركة في تصميم إطار القياس هذا وتفسير البيانات. والقدرة على قياس عائد الذكاء الاصطناعي لا على مستوى السجلّات بل على مستوى مخرجات العمل وإدراك الموظفين ستكون ميزة تنافسية جوهرية في سوق منصّات الذكاء الاصطناعي للمؤسسات.
الحدود والاعتراضات
توخّيًا للتوازن، تستحقّ حدود التقرير الذكر. أولًا، بما أن البيانات تأتي من مستخدمي Claude، فثمّة تحيّز في العيّنة. فهذه أنماط استخدام وإدراك لفئة تستخدم الذكاء الاصطناعي بفاعلية أصلًا، ويصعب تعميمها على كامل القوى العاملة. وتُقرّ Anthropic نفسها مرارًا بأنها لا تستطيع تحديد المهن على نحو قاطع، كما أن التقديرات بحسب المهنة عبر الزمن مستنبطة عكسيًّا من خصائص المهام، فلا يمكن الجزم بالسببية.
ويجب قراءة بيانات الاستبيان بحذر أكبر. فتوقّع «أن يتولّى الذكاء الاصطناعي معظم عملي العام المقبل» إدراكٌ لا قدرة موثَّقة. ويؤكّد التقرير نفسه أن القدرة المُدرَكة تأتي أعلى من الانكشاف المهني المُلاحَظ. والفجوة بين التوقّع والواقع هي ذاتها موضوع القياس، لا مسوّغًا لمعاملة التوقّع بوصفه المستقبل.
أخيرًا، صقل طريقة القياس لا يُكبِّر الأثر بذاته. فالرؤية بدقّة أكبر شيء، وحدوث الشيء بقدر أكبر شيء آخر. قيمة هذا التقرير ليست في خلاصة «أن الذكاء الاصطناعي حلّ محلّ هذا القدر من العمل»، بل في إعادة بناء سؤال «كيف نقيس ذلك الأثر بأمانة أكبر» عبر منهجية مختلطة متعددة الطبقات. وما ينبغي لـ ThakiCloud أخذه ليس الخلاصة بل موقف القياس.
المصادر
- Anthropic، “Anthropic Economic Index report: Cadences” (2026-06-26)
- Anthropic، “Anthropic Economic Index Survey” (2026-04)