AI 경제 영향 측정이 로그 분석을 넘어섭니다: Anthropic Economic Index ‘Cadences’ 보고서를 뜯어봤습니다

개요
엔터프라이즈에 AI 플랫폼을 들여놓고 나면, 결국 한 가지 질문 앞에 서게 됩니다. “그래서 이게 얼마나 도움이 됐는가.” 지금까지 이 질문에 대한 답은 대체로 시스템 지표였습니다. API 호출이 몇 번 일어났고, 태스크를 몇 건 처리했고, 응답이 몇 밀리초 만에 돌아왔는지. 숫자는 깔끔하지만, 정작 경영진이 알고 싶은 “우리 조직이 실제로 무엇을 더 만들어냈는가”에는 닿지 못합니다.
Anthropic이 2026년 6월 26일 공개한 Economic Index 보고서 ‘Cadences’가 흥미로운 이유가 여기 있습니다. 이 보고서는 단순한 사용 통계 업데이트가 아니라, AI의 경제적 영향을 측정하는 방식 자체를 바꿨다고 공개적으로 선언합니다. 채팅 로그만으로는 AI가 일에 미치는 영향을 설명할 수 없다는 인식에서 출발해, 측정의 기반을 세 갈래로 넓혔습니다.
ThakiCloud처럼 쿠버네티스 위에서 멀티테넌트 AI/ML 플랫폼을 실제로 운영하는 입장에서 이 전환은 남의 이야기가 아닙니다. 고객사에 ROI를 설명하는 언어가 “시스템 지표”에서 “업무 산출물과 구성원 인식”으로 옮겨가는 흐름을, 이 보고서가 데이터로 보여주기 때문입니다. 이 글은 보고서의 공식 자료를 근거로 세 가지 방법론 전환을 정리하고, 우리 플랫폼 관점에서 무엇을 가져갈 수 있는지를 짚습니다.
이 보고서는 무엇인가
Anthropic은 2023년부터 Economic Index를 통해 Claude 사용 양상을 분석해 왔습니다. 그동안의 보고서는 모두 7일치 샘플 데이터에 기댔습니다. 일주일을 잘라내 그 안에서 사용 패턴을 들여다보는 방식입니다. 1년 전만 해도 Claude 사용의 대부분이 사용자와 어시스턴트 사이의 대화였기 때문에, 이 방식으로도 그림이 어느 정도 잡혔습니다.
그런데 Claude Code와 Cowork가 빠르게 성장하면서, 세션의 상당수가 길게 이어지는 에이전트 작업으로 바뀌었습니다. 채팅 기록만으로는 사람들이 AI를 어떻게 쓰는지 더 이상 온전히 담기지 않게 된 것입니다. Anthropic은 이 변화를 따라잡기 위해 데이터 파이프라인을 세 가지 방향으로 손봤다고 밝힙니다. 샘플링 비율을 높여 시간 단위까지 패턴을 보고, 대화의 산출물을 분류하는 분류기를 새로 도입하고, 채팅/Cowork와 1P API 결과를 월 단위로 나눠 더 세분화해 공개합니다.
여기에 한 축이 더 붙습니다. 그동안 Anthropic은 사용자 세션 바깥의 영향, 즉 사람들이 AI를 어떻게 체감하는지에 대한 가시성이 부족했다고 인정합니다. 그래서 2026년 4월에 시작한 경제지수 설문(Economic Index Survey)의 초기 결과를 함께 내놓습니다. 정리하면 이 보고서는 세 개의 축, 즉 시간 단위 케이던스, 산출물 분류, 인식 설문으로 짜여 있습니다.
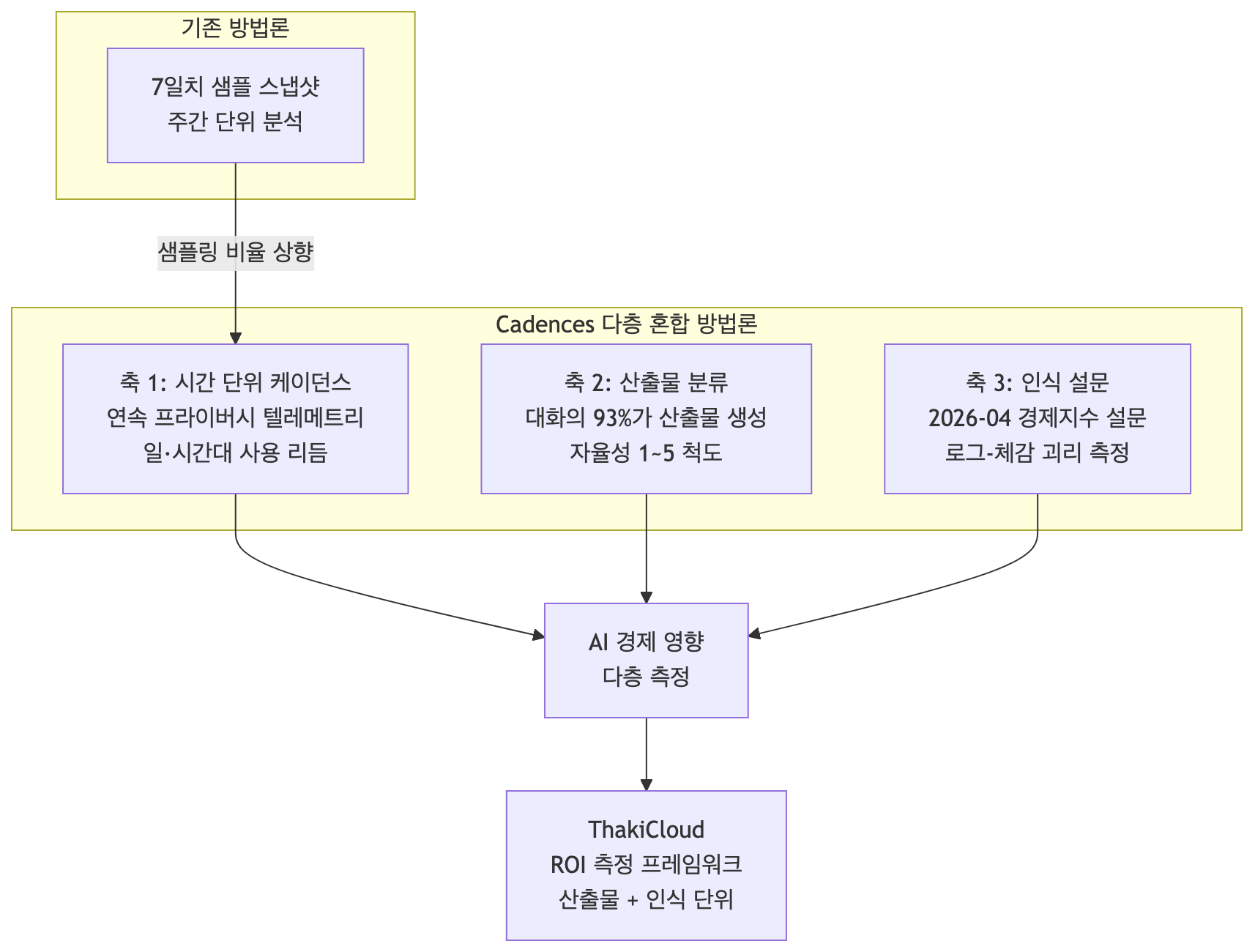
첫 번째 축: 시간 단위 케이던스
가장 눈에 띄는 변화는 프라이버시 보존형 텔레메트리의 도입입니다. 매일 일정 비율의 대화를 연속적으로 샘플링하는 방식으로, 기존의 7일 스냅샷과 달리 일·시간 단위의 흐름을 잡아냅니다. 이 데이터로 처음으로 일상의 리듬이 Claude 사용에 어떻게 반영되는지를 볼 수 있게 됐습니다.
결과는 직관에 부합하면서도 새롭습니다. Claude 사용은 주중 근무 패턴을 그대로 따라가고, 개인적인 질문은 주말에 늘어납니다. 시간대별로 들어가면 더 선명합니다. 사람들은 새벽 5시 무렵에 수면 관련 조언을 가장 많이 구하고, 저녁 6시 무렵에는 레시피를 묻습니다. 아침에는 뉴스 요청이 몰립니다. 특정 날짜에 반응하는 패턴도 보입니다. 미국 세금 신고 마감일인 4월 15일 직전에는 세금 관련 요청이 급증했습니다.
업무 성격에 따른 차이도 드러납니다. 야간과 주말처럼 정규 시간이 아닐 때 사람들이 일 때문에 Claude를 찾으면, 그 태스크는 고임금 직군 쪽으로 쏠립니다. 마케팅 매니저나 프로그래머처럼 전통적 근무 시간 밖에서 일하는 비중이 높은 직군이 여기 해당합니다. 반대로 텔레마케팅이나 사무 보조처럼 하위 임금 분위의 태스크는 야간·주말에 비중이 줄어듭니다. Anthropic은 컴퓨터·수학 직군을 분석에서 빼는 강건성 검증을 해도 이 경향이 유지된다고 덧붙입니다. 단순 자동화가 아니라 고숙련 업무의 보조 도구로 AI가 기능하고 있다는 신호로 읽을 수 있는 대목입니다.
두 번째 축: 산출물(Artifact) 분류기
두 번째 전환은 대화의 결과물을 분류하는 일입니다. Anthropic은 채팅과 Cowork 대화 각각이 어떤 산출물(artifact)을 만들어내는지를 30개가 넘는 범주로 분류했습니다. 문서, 설명, 코드 한 조각, 학술 논문처럼 그 대화에서 Claude가 만들어낸 주된 결과물을 뜻합니다.
분류기는 Claude 대화의 93%가 어떤 산출물을 생성한다고 판정했습니다. 가장 흔한 유형은 설명(17%), 문서 및 보고서(15%), 가이던스(11%) 순입니다. 설명이나 가이던스 같은 대화형 결과물과 문서나 프레젠테이션 같은 작성형 결과물이 각각 전체의 약 3분의 1을 차지하고, 앱이나 스크립트 같은 코드·기술 결과물이 약 6분의 1을 차지합니다.
여기서 흥미로운 두 번째 발견이 나옵니다. 자율성(autonomy) 점수입니다. Anthropic은 Claude에게 얼마나 많은 판단을 위임하는지를 1에서 5까지의 척도로 측정합니다. 번역이나 계산처럼 답이 거의 정해진 작업은 자율성이 낮고, 앱이나 게임, 프레젠테이션을 만드는 일처럼 여러 선택지 중에서 골라야 하는 작업은 자율성이 높습니다.
같은 산출물이라도 Claude Code에서 만들 때 자율성이 더 높게 측정됩니다. 보여준 31개 산출물 중 26개에서 Claude Code 쪽 자율성이 챗·Cowork보다 높았고, 전체 평균으로는 0.37점 차이가 났습니다. 스크립트나 코드 조각의 경우 그 격차가 0.53점까지 벌어집니다. 이 차이의 약 3분의 2는 같은 작업을 더 많이 위임해서 처리하기 때문이라고 설명합니다. 블로그 글이 좋은 예입니다. 챗·Cowork에서 블로그 글을 만드는 대화는 중앙값 기준 13번의 주고받기를 거치지만, Claude Code에서는 사용자가 더 많은 판단을 맡깁니다. 사용자가 AI에게 더 많은 자율성을 넘기고 있다는 뜻입니다.
세 번째 축: 인식 설문
세 번째 축은 로그가 아니라 사람에게 직접 묻는 데이터입니다. Anthropic은 2026년 4월 경제지수 설문을 시작해, 실제 Claude 이용자에게 AI가 자신의 업무를 어느 정도 수행할 수 있는지를 직접 물었습니다. 설문 응답은 프라이버시 보존 방법으로 사용 데이터와 연결됩니다.
응답자에게 오늘 기준으로 AI가 스스로 처리할 수 있는 업무 비중(reported exposure)과 12개월 뒤에 처리할 것으로 기대하는 비중(anticipated exposure)을 물었습니다. 10명 중 6명에 가까운 응답자가 내년에 더 높은 구간을 선택했고, 3분의 1 이상이 내년에는 AI가 자기 업무의 대부분 또는 거의 전부를 처리할 수 있을 것으로 기대한다고 답했습니다.
층위별 차이도 또렷합니다. 소득 수준이 낮은 국가의 응답자일수록 AI가 더 많은 업무를 대체할 수 있다고 느끼는 경향이 강했습니다. Anthropic은 이런 국가일수록 AI를 보강이 아니라 자동화에 쓰는 경향이 있다는 이전 연구를 함께 인용합니다. 경력에 따른 차이도 나타났습니다. 15년 이상 경력자는 AI가 할 수 있는 업무 비중을 첫해 근무자보다 약 10퍼센트포인트 낮게 봤습니다. 오래 일한 사람일수록 AI가 흉내내기 어려운 암묵적·맥락적 전문성을 쌓았기 때문이라는 해석입니다. 응답자들은 AI가 끝내 할 수 없는 일로 판단, 맥락 인식, 상황 추론, 그리고 신뢰 구축과 사람 관리 같은 관계적 차원을 꼽았습니다. 대체에 대한 우려는 경력 초년생과 저임금 직군에 집중됐습니다.
ThakiCloud K8s AI/ML SaaS 플랫폼 적용 및 시사점
이 보고서가 ThakiCloud에 주는 함의는 기능이 아니라 측정 프레임워크에 있습니다. Anthropic이 택한 접근은 “로그만으로는 AI 가치를 설명할 수 없다”는 전제에서 출발하는데, 이는 엔터프라이즈 AI 플랫폼을 운영하는 우리에게 그대로 적용 가능한 관점입니다.
지금까지 고객사에 ROI를 설명할 때 우리도 시스템 지표를 중심에 뒀습니다. 호출 횟수, 처리량, 응답 속도. 그런데 이 보고서는 다른 층위의 질문을 던집니다. 그 대화에서 무엇이 생성됐는가. 그 산출물은 업무 시간 안에 만들어졌는가, 야간 초과근무 중에 만들어졌는가. 사용자는 AI에게 얼마나 많은 자율성을 위임했는가. 사용자 스스로는 AI가 자기 업무를 얼마나 대체한다고 느끼는가.
이 질문들은 우리 스택 위에서 충분히 측정 가능합니다. ThakiCloud는 쿠버네티스와 Kueue 기반 GPU 스케줄링, vLLM 서빙, 멀티테넌트 에이전트 운용을 한곳에서 다룹니다. 여기서 나오는 텔레메트리에 산출물 분류기를 한 겹 얹으면, 고객사 직원들이 언제 어떤 유형의 결과물을 AI와 함께 만드는지를 잡아낼 수 있습니다. 그러면 AI 도입 효과를 “업무 효율 향상”이라는 추상적 표현이 아니라 구체적 산출물 단위로 설명하게 됩니다. 야근 시간대에 고임금 직군 태스크 비중이 높아진다는 발견은, 우리 고객사에서도 AI가 단순 자동화가 아니라 고숙련 업무의 보조 도구로 자리잡고 있는지를 가늠하는 지표가 될 수 있습니다.
설문과 로그를 연계하는 방식도 참고할 만합니다. 실제 사용 데이터와 체감 인식 사이의 괴리를 측정하면, AI 도입 후 어떤 계층이 가장 효과를 보고 어떤 계층이 불안을 느끼는지를 파악할 수 있습니다. 이는 고객사의 내부 변화 관리(Change Management) 전략 수립에 곧바로 쓰이는 인사이트입니다. 특히 온프렘 환경에서 데이터를 외부로 내보내지 않고 측정해야 하는 국내 고객사라면, 프라이버시 보존형 측정 설계는 선택이 아니라 요구 사항입니다. 우리의 멀티테넌트 격리와 self-hosting 구조는 이 요구에 정확히 맞물립니다.
결국 Anthropic이 보여주는 방향은 AI가 경제에 미치는 영향을 측정하는 기준을 계속 고도화하겠다는 의지입니다. ThakiCloud가 고객사에 줄 수 있는 강력한 차별점 하나는, 단순한 플랫폼 제공을 넘어 이런 측정 프레임워크를 함께 설계하고 데이터를 해석해주는 파트너 역할입니다. AI 도입 ROI를 로그 수준이 아니라 업무 산출물과 구성원 인식 수준에서 측정하는 능력이, 앞으로 엔터프라이즈 AI 플랫폼 시장의 핵심 경쟁력이 될 것이라고 봅니다.
한계 및 반론
균형을 위해 이 보고서의 한계도 짚어야 합니다. 먼저 데이터의 출처가 Claude 사용자라는 점에서 표본 편향이 있습니다. AI를 이미 적극적으로 쓰는 집단의 사용 패턴과 인식이므로, 전체 노동 인구로 일반화하기는 어렵습니다. Anthropic 자신도 직업을 확정적으로 식별할 수 없다고 여러 차례 밝힙니다. 시간대별 직군 추정 역시 태스크 성격에서 역으로 추론한 것이라 인과를 단정하기 어렵습니다.
설문 데이터는 더 조심스럽게 읽어야 합니다. “내년에 AI가 내 업무 대부분을 처리할 것”이라는 기대는 체감이지 검증된 역량이 아닙니다. 보고서 안에서도 실제 직업별 노출 지표보다 체감 역량이 더 높게 나타난다는 점이 확인됩니다. 기대와 현실 사이의 이 간극 자체가 측정 대상이지, 기대치를 곧 미래로 받아들일 근거는 아닙니다.
마지막으로, 측정 방법론의 고도화가 곧 영향의 크기를 키우는 것은 아닙니다. 더 정교하게 본다는 것과 더 크게 일어난다는 것은 다른 이야기입니다. 이 보고서의 가치는 “AI가 일을 얼마나 대체했다”는 결론이 아니라, “그 영향을 어떻게 더 정직하게 측정할 것인가”라는 질문을 다층 혼합 방법론으로 다시 세운 데 있습니다. ThakiCloud가 가져갈 것도 결론이 아니라 그 측정의 태도입니다.
출처
- Anthropic, “Anthropic Economic Index report: Cadences” (2026-06-26)
- Anthropic, “Anthropic Economic Index Survey” (2026-04)