SkillRet: ThakiCloud تضع معيار البحث في عصر الوكلاء الذين يديرون آلاف المهارات
⏱️ وقت القراءة المقدر: 6 دقائق
كلما ازدادت المهارات، ضاع الوكيل في الطريق
من يدير وكلاء LLM لفترة كافية يصطدم بالجدار نفسه. في البداية يكون عدد المهارات قليلاً فيختار الوكيل المناسب منها بسهولة. لكن حين تتراكم المهارات لتصل إلى المئات والآلاف، ينقلب الوضع رأساً على عقب: الوكيل لا يجد المهارة الصحيحة في اللحظة المطلوبة، أو يختار مهارة متشابهة الاسم لكنها خاطئة. قد تكون تقسيم المهمة بدقة، لكن إن لم يرتفع الأداة المناسبة، فالمسألة تنهار هناك.
هذه هي مشكلة البحث عن المهارات (skill retrieval). إنها تحويل طلب المستخدم، وهو نص طبيعي طويل ومليء بالضوضاء، إلى المهارة الواحدة الأنسب من بين آلاف المرشحين. قد يبدو الأمر مشابهاً للبحث عن وثيقة في RAG، لكنه مختلف جوهرياً. الوثيقة موجودة لتُقرأ، والمهارة موجودة لتُنفَّذ. وثيقة خاطئة تُضعف الإجابة قليلاً؛ مهارة خاطئة تجعل الوكيل يتصرف بطريقة معيبة.
المشكلة واضحة، لكن لم يكن ثمة مقياس ضخم وواقعي يقيسها بدقة. لذا أنشأت ThakiCloud هذا المقياس بنفسها. الورقة البحثية عنوانها “SkillRet: A Large-Scale Benchmark for Skill Retrieval in LLM Agents” (arXiv:2605.05726). المؤلفون: Hongcheol Cho وRyangkyung Kang وYoungeun Kim.
مم يتكون مقياس SkillRet؟
نقطة الانطلاق في SkillRet هي الحجم والواقعية. لا بيانات مختبرية اصطناعية، بل مهارات وكلاء حقيقية مجمعة من المصادر المفتوحة لإعادة صياغة مشكلة البحث.
- 17,810 مهارة وكيل مفتوحة المصدر.
- نظام تصنيف ثنائي المستوى: 6 فئات كبرى و18 فئة فرعية مع وسوم دلالية.
- 63,259 عينة تدريب.
- 4,997 استعلام تقييم، مع فصل تام (disjoint) بين مجموعة المهارات في التدريب ومجموعة التقييم.
البند الأخير بالغ الأهمية. إن أعدت للوكيل مهارات رآها في التدريب، ستبدو الدرجات جيدة لكن القدرة على التعميم ستبقى مجهولة. الفصل بين المجموعتين يعني قياساً صادقاً لسؤال واحد: “هل ينجح البحث في مجموعة مهارات لم يرها من قبل؟”
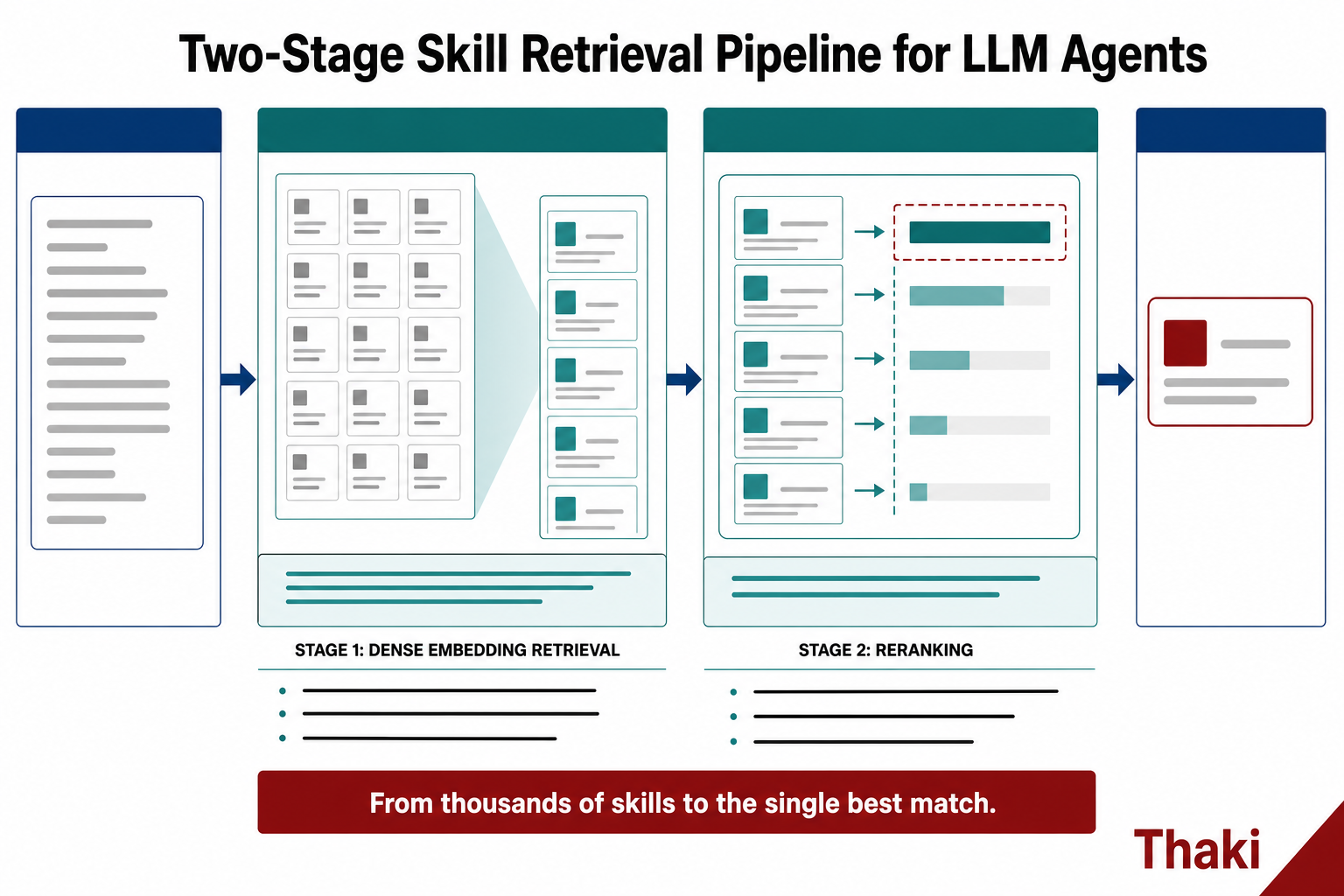
خط الأنابيب ذو المرحلتين: التضمين للتضييق، وإعادة الترتيب للانتقاء
أسلوب البحث الذي يقترحه SkillRet هو بنية ثنائية المرحلة مأخوذة من أنظمة البحث المثبتة ومكيّفة لمجال المهارات.
- المرحلة الأولى: البحث بالتضمين الكثيف (dense embedding retrieval). ترفع كلاً من الاستعلام وجميع المهارات إلى الفضاء المتجهي ذاته، وتستخلص بسرعة المرشحين الأقرب دلالياً. بدلاً من فحص الآلاف بعمق، تلقي الشبكة أولاً على نطاق واسع.
- المرحلة الثانية: إعادة الترتيب (reranking). تُعيد ترتيب المرشحين الذين استُخلصوا في المرحلة الأولى فحسب بدقة أعلى. النطاق الضيق يجعل التكلفة مقبولة مقابل كسب الدقة.
هذا التقسيم بين الشمولية والدقة هو جوهر الفكرة. لا تحشو نموذجاً واحداً بمسؤولية الاستدعاء (الاستيعاب) والدقة معاً، بل تفصل المرحلتين لتتقن كل منهما مهمتها.
النتائج: النموذج المُضبَّط يتمسك بالإشارة وسط الضوضاء
الأرقام هي أوضح ما في هذا البحث. نماذج البحث المُضبَّطة حققت في NDCG@10 العام:
| المقارنة | الفارق في NDCG@10 |
|---|---|
| مقابل أقوى نظام بحث موجود | +13.1 |
| مقابل نماذج بحث جاهزة (off-the-shelf) | +16.9 |
ما يستخلصه هذا البحث يتجاوز مجرد الدرجات. النموذج المُضبَّط يركز بشكل أفضل على الإشارات المتعلقة بالمهارة داخل استعلامات طويلة ومشوشة. طلبات المستخدمين الحقيقية ليست نظيفة: شروح خلفية، وتشعبات جانبية، وصياغات ضبابية. القدرة على استخلاص إشارة “أي مهارة يحتاجها هذا الطلب” من بين تلك الضوضاء هي ما يفرق بين نظام بحث عام ونظام بحث مُدرَّب للمهارات.
قياسات النماذج المنشورة توضح الصورة كاملة:
| النموذج | الأساس | المقاييس الرئيسية |
|---|---|---|
| SKILLRET-Embedding-0.6B | Qwen3-Embedding-0.6B | NDCG@15 0.7887 / Recall@15 0.8809 |
| SKILLRET-Embedding-8B | Qwen3-Embedding-8B | NDCG@10 0.8345 / Recall@10 0.9123 |
نموذج 0.6B تدرّب نحو 6 ساعات على 4x B200 وسجّل 1,188 تنزيلاً الشهر الماضي. نموذج 8B يرفع الدقة بقاعدة أضخم. ابدأ بـ 0.6B لمتطلبات خفيفة وارجع للـ 8B حين تكون الدقة أولوية.
كل شيء مفتوح المصدر
قيمة البحث تكتمل حين يكون قابلاً للتكرار. SkillRet أتاح كل شيء بترخيص Apache-2.0: الورقة والبيانات والنماذج والكود.
- الورقة: arXiv:2605.05726
- الكود: github.com/ThakiCloud/SKILLRET (Python، خط أنابيب ثنائي المرحلة، تنزيل تلقائي من HF، دعم Multi-GPU)
- مجموعة البيانات: huggingface.co/datasets/ThakiCloud/SKILLRET (220,576 سجل، 725MB)
- نموذج التضمين 0.6B: huggingface.co/ThakiCloud/SKILLRET-Embedding-0.6B
- نموذج التضمين 8B: huggingface.co/ThakiCloud/SKILLRET-Embedding-8B
استنسخ المستودع وتنزّل النماذج والبيانات تلقائياً من HF، ثم شغّل التدريب والتقييم مباشرة على بيئة Multi-GPU.
لماذا تتصدى ThakiCloud لهذه المشكلة بنفسها؟
مصطلح “اقتصاد المهارات” (skill economy) ليس مبالغة. عصر الوكلاء الذين يجمعون آلاف المهارات القابلة لإعادة الاستخدام وفق السياق بدأ فعلاً. وفي قاع هذا الاقتصاد تقبع “طبقة البحث” التي تجد المهارة الصحيحة في اللحظة الصحيحة. إن تزعزعت هذه الطبقة، تزعزع كل التنسيق فوقها.
ThakiCloud لم تتعامل مع هذه الطبقة كمهمة مستقبلية مجردة. منصتنا تُوجّه أكثر من 1000 مهارة فعلاً في الإنتاج. حين يصل طلب، تُجري بحثاً عن المهارات المرشحة، وتحكم على الملاءمة، وإن لم توجد مهارة مناسبة لا تستدعي واحدة عشوائية بل تسلّم الأمر للمعالجة الافتراضية. الإحساس الذي يولده SkillRet بضرورة استخلاص الإشارة من استعلامات مشوشة هو خبرتنا اليومية.
لهذا صغنا المشكلة بحثياً، وجعلناها قابلة للقياس عبر المقياس، وضبطنا Qwen3-Embedding ذاتياً لنحصل على تحسن NDCG +16.9 مقارنة بالنماذج الجاهزة. ثم أطلقنا النتائج كاملة: مجموعة البيانات وأوزان النماذج وكود التدريب بلا استثناء تحت Apache-2.0. هذا ليس مجرد ورقة بحثية؛ بل دليل على أن خط أنابيباً يمتد من البحث إلى المنتج يعمل فعلاً. دوامة ترد من العمل التشغيلي إلى البحث وتعود منه إلى التشغيل قائمة داخلنا.
من يضع المعيار أولاً يتحكم فيما يقف فوقه
من يُعرّف معيار البحث أولاً يُؤثر فيما يُبنى عليه. SkillRet ليس مجرد نموذج يحقق درجات جيدة، بل نقطة مرجعية مفتوحة تجيب: “كيف نقيس بحث مهارات الوكلاء وما الذي يجب إتقانه؟” نظام التصنيف واستعلامات التقييم وفصل مجموعات التدريب والتقييم وخط الأنابيب ذو المرحلتين، كلها مجمّعة في مرجع واحد يمكن لأي فريق قياس نظامه به.
كل من يبني منصة وكلاء بجدية سيواجه في النهاية هذه الطبقة من البحث. ThakiCloud أتاحت المرجع الذي سيحتاجه من يصل إليها. مشكلة “ضياع الوكيل كلما كثرت مهاراته” تحولت على أيدينا إلى مشكلة قابلة للقياس، وأجابتنا عليها متاحة للجميع.