SkillRet: 에이전트가 수천 개 스킬을 다루는 시대의 검색 표준을 ThakiCloud가 만들다
스킬이 많아질수록 에이전트는 길을 잃는다
LLM 에이전트를 한동안 운용해 보면 누구나 같은 벽을 만납니다. 처음엔 스킬이 몇 개뿐이라 에이전트가 알아서 골라 씁니다. 그런데 스킬이 수백, 수천 개로 늘어나면 상황이 뒤집힙니다. 정작 필요한 순간에 맞는 스킬을 못 찾거나, 비슷한 이름의 엉뚱한 스킬을 집어 듭니다. 작업을 잘 쪼개도 적합한 도구를 못 띄우면 거기서 무너집니다.
이게 바로 스킬 검색(skill retrieval) 문제입니다. 사용자의 요청, 그것도 길고 노이즈가 많은 자연어 요청을 받아서, 수천 개의 후보 중 지금 이 작업에 진짜로 맞는 스킬을 정확히 위로 끌어올리는 일입니다. RAG에서 문서를 찾는 일과 비슷해 보이지만 결이 다릅니다. 문서는 내용을 읽혀지려고 존재하고, 스킬은 실행되려고 존재합니다. 잘못 검색된 문서는 답이 살짝 흐려지는 정도지만, 잘못 검색된 스킬은 에이전트가 잘못된 행동을 하게 만듭니다.
문제는 분명한데, 이걸 제대로 측정할 현실적인 대규모 벤치마크가 없었습니다. 그래서 ThakiCloud가 직접 만들었습니다. 논문 “SkillRet: A Large-Scale Benchmark for Skill Retrieval in LLM Agents”(arXiv:2605.05726)입니다. 저자는 Hongcheol Cho, Ryangkyung Kang, Youngeun Kim입니다.
SkillRet 벤치마크는 무엇으로 이루어졌나
SkillRet의 출발점은 규모와 현실성입니다. 실험실용 장난감 데이터가 아니라, 공개된 실제 에이전트 스킬을 그러모아 검색 문제를 재구성했습니다.
- 공개 에이전트 스킬 17,810개를 수집했습니다.
- 2단계 분류 체계를 붙였습니다. 대분류 6개, 소분류 18개로 나누고 거기에 시맨틱 태그를 더했습니다.
- 학습용 샘플 63,259개를 구성했습니다.
- 평가용 쿼리 4,997개를 만들되, 학습과 평가의 스킬 풀이 겹치지 않도록(disjoint) 분리했습니다.
마지막 항목이 특히 중요합니다. 학습에서 본 스킬을 평가에서 다시 보여 주면 점수는 잘 나오지만 일반화 능력은 알 수 없습니다. 풀을 분리했다는 건 “처음 보는 스킬 집합에서도 검색이 되는가”를 정직하게 측정하겠다는 설계입니다.
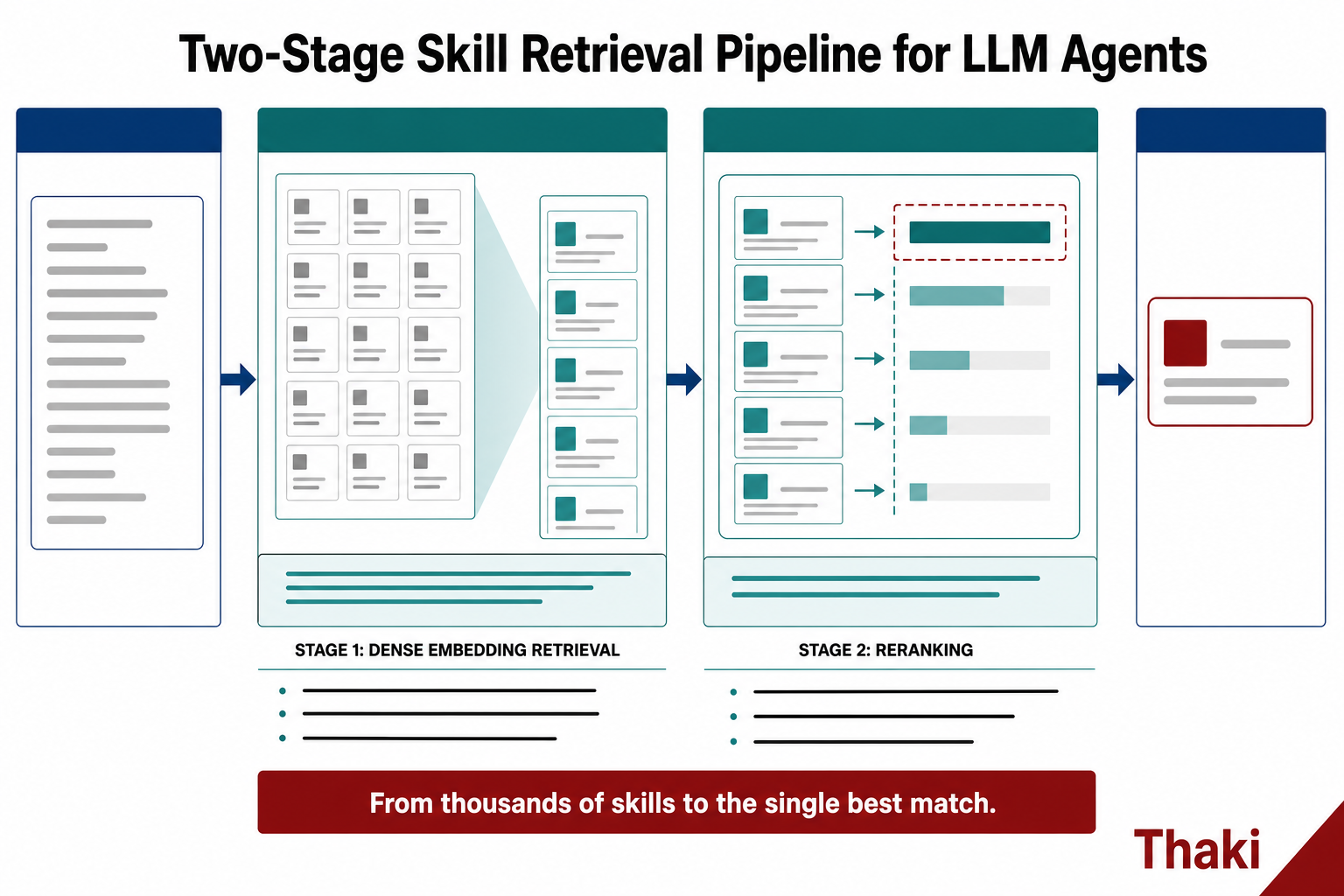
2단계 파이프라인: 임베딩으로 좁히고 리랭킹으로 고른다
SkillRet이 제안하는 검색 방식은 검색 시스템에서 검증된 형태를 스킬 영역에 맞게 다듬은 2단계 구조입니다.
- 1단계, 밀집 임베딩 검색(dense embedding retrieval). 쿼리와 모든 스킬을 같은 벡터 공간에 올려 두고, 의미적으로 가까운 후보군을 빠르게 추려 냅니다. 수천 개 전체를 정밀하게 따지기엔 비싸니, 먼저 넓게 그물을 던지는 단계입니다.
- 2단계, 리랭킹(reranking). 1단계가 추린 후보만 대상으로 더 정교하게 순위를 다시 매깁니다. 좁은 후보군이라 비용을 더 써도 감당이 되고, 그만큼 정확도를 끌어올립니다.
넓게 거른 뒤 좁게 고르는 이 분업이 핵심입니다. 검색의 재현율(놓치지 않기)과 정밀도(정확히 위로 올리기)를 한 모델에 몰아넣지 않고 단계로 나눠 각자 잘하게 둡니다.
결과: 파인튜닝이 노이즈 속 신호를 더 잘 본다
수치가 이 연구의 결론을 가장 또렷하게 말해 줍니다. 파인튜닝한 검색 모델은 일반 NDCG@10 기준으로 다음을 달성했습니다.
| 비교 대상 | NDCG@10 향상폭 |
|---|---|
| 가장 강한 기존 검색기 대비 | +13.1 |
| 그대로 가져다 쓴(off-the-shelf) 검색기 대비 | +16.9 |
여기서 얻은 통찰이 단순한 점수 이상으로 의미가 있습니다. 파인튜닝한 모델은 길고 노이즈가 많은 쿼리 안에서도 스킬과 관련된 신호에 더 잘 집중했습니다. 실제 사용자 요청은 깔끔하지 않습니다. 배경 설명, 곁가지, 모호한 표현이 섞입니다. 그 잡음을 뚫고 “지금 이건 어떤 스킬이 필요한 작업이다”라는 신호를 골라내는 능력이 일반 검색기와 전용 파인튜닝 검색기를 가릅니다.
공개한 모델의 실측치도 함께 보면 그림이 분명해집니다.
| 모델 | 베이스 | 핵심 지표 |
|---|---|---|
| SKILLRET-Embedding-0.6B | Qwen3-Embedding-0.6B | NDCG@15 0.7887 / Recall@15 0.8809 |
| SKILLRET-Embedding-8B | Qwen3-Embedding-8B | NDCG@10 0.8345 / Recall@10 0.9123 |
0.6B 모델은 4xB200에서 약 6시간 학습했고, 지난달 다운로드 1,188회를 기록했습니다. 8B 모델은 더 큰 베이스로 정밀도를 더 끌어올린 버전입니다. 작게 시작하고 싶으면 0.6B, 정확도가 우선이면 8B를 고르면 됩니다.
전부 열어 두었습니다
연구의 가치는 재현 가능할 때 완성됩니다. SkillRet은 논문부터 데이터, 모델, 코드까지 모두 Apache-2.0로 공개했습니다.
- 논문: arXiv:2605.05726
- 코드: github.com/ThakiCloud/SKILLRET (Python, 2단계 파이프라인, HF 자동 다운로드, 멀티 GPU 지원)
- 데이터셋: huggingface.co/datasets/ThakiCloud/SKILLRET (220,576 레코드, 725MB)
- 임베딩 모델 0.6B: huggingface.co/ThakiCloud/SKILLRET-Embedding-0.6B
- 임베딩 모델 8B: huggingface.co/ThakiCloud/SKILLRET-Embedding-8B
저장소를 받아 HF에서 모델과 데이터를 자동으로 내려받고, 멀티 GPU 환경에서 바로 학습과 평가를 돌릴 수 있게 구성했습니다.
ThakiCloud가 이 문제를 직접 푼 이유
스킬 경제(skill economy)라는 말이 과장이 아닙니다. 에이전트가 수천 개의 재사용 가능한 스킬을 상황에 맞게 조합해 일하는 시대가 이미 시작됐습니다. 그리고 그 경제의 밑바닥에는 “지금 필요한 스킬을 정확히 찾는 검색 계층”이 깔려 있습니다. 이 계층이 흔들리면 그 위의 모든 오케스트레이션이 흔들립니다.
ThakiCloud는 이 검색 계층을 추상적인 미래 과제로 두지 않았습니다. 우리 플랫폼은 이미 1000개가 넘는 스킬을 실제로 라우팅하며 운용합니다. 작업이 들어오면 후보 스킬을 검색하고, 적합도를 판정하고, 맞는 게 없으면 억지로 끌어다 쓰지 않고 기본 처리로 내려보내는 흐름이 일상적으로 돌아갑니다. 노이즈 많은 쿼리에서 진짜 신호를 골라내야 한다는 SkillRet의 문제의식은 우리가 매일 부딪히는 실무 그 자체입니다.
그래서 우리는 이 문제를 연구로 정식화하고, 벤치마크로 측정 가능하게 만들고, 베이스 모델 Qwen3-Embedding을 자체 파인튜닝해 off-the-shelf 대비 NDCG +16.9라는 향상을 만들어 냈습니다. 그리고 그 결과물을 데이터셋부터 모델 가중치, 학습 코드까지 하나도 빼지 않고 Apache-2.0로 풀었습니다. 이건 연구실의 논문 한 편이 아니라, 연구에서 제품으로 이어지는 파이프라인이 실제로 작동한다는 증거입니다. 운용에서 발견한 병목을 연구로 끌어올리고, 그 연구를 다시 운용에 되먹이는 고리가 우리 안에 있습니다.
표준을 먼저 세운다는 것
검색 표준을 먼저 정의한 쪽은 그 위에 무엇이 올라오는지를 좌우합니다. SkillRet은 단순히 점수 잘 나오는 모델 하나가 아니라, “에이전트 스킬 검색을 어떻게 측정하고 무엇을 잘해야 하는가”에 대한 공개된 기준점입니다. 분류 체계, 평가 쿼리, 학습-평가 풀 분리, 2단계 파이프라인까지 하나의 레퍼런스로 묶여 누구나 같은 잣대로 자기 시스템을 잴 수 있습니다.
에이전트 플랫폼을 진지하게 짓는 곳이라면 결국 이 검색 계층을 마주합니다. 그때 펼쳐 볼 레퍼런스를 ThakiCloud가 먼저 열어 두었습니다. 스킬이 많아질수록 길을 잃는 문제를, 우리는 측정 가능한 문제로 바꿔 놓았고, 그 답을 모두에게 공개했습니다.