حفنة من بيانات البشر تكفي: تثبيت سياسات القيادة المُدرَّبة بالـ self-play على البشر عبر التنظيم
نظرة عامة
مع جعل المحاكاة توليد الخبرة شبه مجاني، يزداد سؤال واحد حدّة: كم من بيانات البشر، وبأي شكل، يستحق الاستخدام فعلًا؟ في تعلّم سياسات القيادة يرتبط هذا السؤال مباشرة بالتكلفة. فجمع عروض القيادة البشرية على نطاق واسع مكلف وبطيء، بينما الـ self-play داخل محاكٍ رخيص وغير محدود تقريبًا.
ورقة من جامعة نيويورك وبرينستون ومتعاونين بعنوان “Human-like autonomy emerges from self-play and a pinch of human data” (arXiv:2606.19370، يونيو 2026) تقدّم إجابة واضحة. كما يقول العنوان، حفنة تكفي. وعمليًا، فإن 30 دقيقة فقط من بيانات القيادة البشرية، أي أقل بـ 2500 مرة من التعلّم بالتقليد، تُنتج سياسة أكثر توافقًا مع البشر. ويكتمل التدريب بأكمله في 15 ساعة على GPU استهلاكي واحد.
لا يكتفي هذا المقال بعرض نتيجة في مجال القيادة. فمن منظور منصّة مثل ThakiCloud، التي يجب أن تدرّب وتُحاذي وكلاء كثيرين في بيئة متعددة المستأجرين، نتفحّص لماذا يتوافق هذا التصميم، أي “إبقاء الخبرة التركيبية الرخيصة محرّكًا رئيسيًا وتطبيق الإشارة البشرية المكلفة فقط كمرساة تنظيم صغيرة”، توافقًا جيدًا مع نموذج التكلفة لدينا.
📄 المراجعة المتعمقة الكاملة (DOCX): نزّل المراجعة التفصيلية من Google Drive.
ما هذا البحث
يستطيع التعلّم المعزّز بالـ self-play النقي تدريب سياسات قيادة دون أي بيانات بشرية. وتظهر المشكلة حين تكون المكافأة فقط “صِل إلى الوجهة بأمان”. فتحت مكافأة متفرّقة كهذه، تتقارب السياسة نحو أعراف فعّالة لكنها غريبة عن البشر. فإن كان الوصول إلى الهدف بالرجوع للخلف أو جانبيًا أو حتى بعكس السير لا يخالف المكافأة، فسيفعل النموذج ذلك بسرور، لأن ملء المكافأة هو كل ما يهم.
كانت المعالجات السابقة تعني هندسة المكافآت بعناية أو نشر التعشية النطاقية. وكلاهما كثيف العمل وهشّ. تقلب هذه الورقة الفكرة. فبدل استخدام بيانات البشر كإشارة تعلّم رئيسية، تحوّل سياسة مرساة بالاستنساخ السلوكي (BC) إلى حدّ تنظيم. تبقى المكافأة بسيطة ومتفرّقة (+1 لبلوغ الهدف، -1 للاصطدام أو الخروج عن الطريق، و0 فيما عدا ذلك)، ويُضاف حدّ KL نحو سياسة المرساة إلى خسارة PPO. وتتحكّم λ في القوة؛ وحين تكون λ صفرًا يُختزل الأمر إلى self-play صرف دون تنظيم.
البنية الكاملة موضّحة أدناه. محرّك self-play رخيص هو القوة الدافعة الرئيسية، ومرساة بشرية مدتها 30 دقيقة تسحب السياسة بلطف نحو البشر عبر خيط رفيع من تنظيم KL.
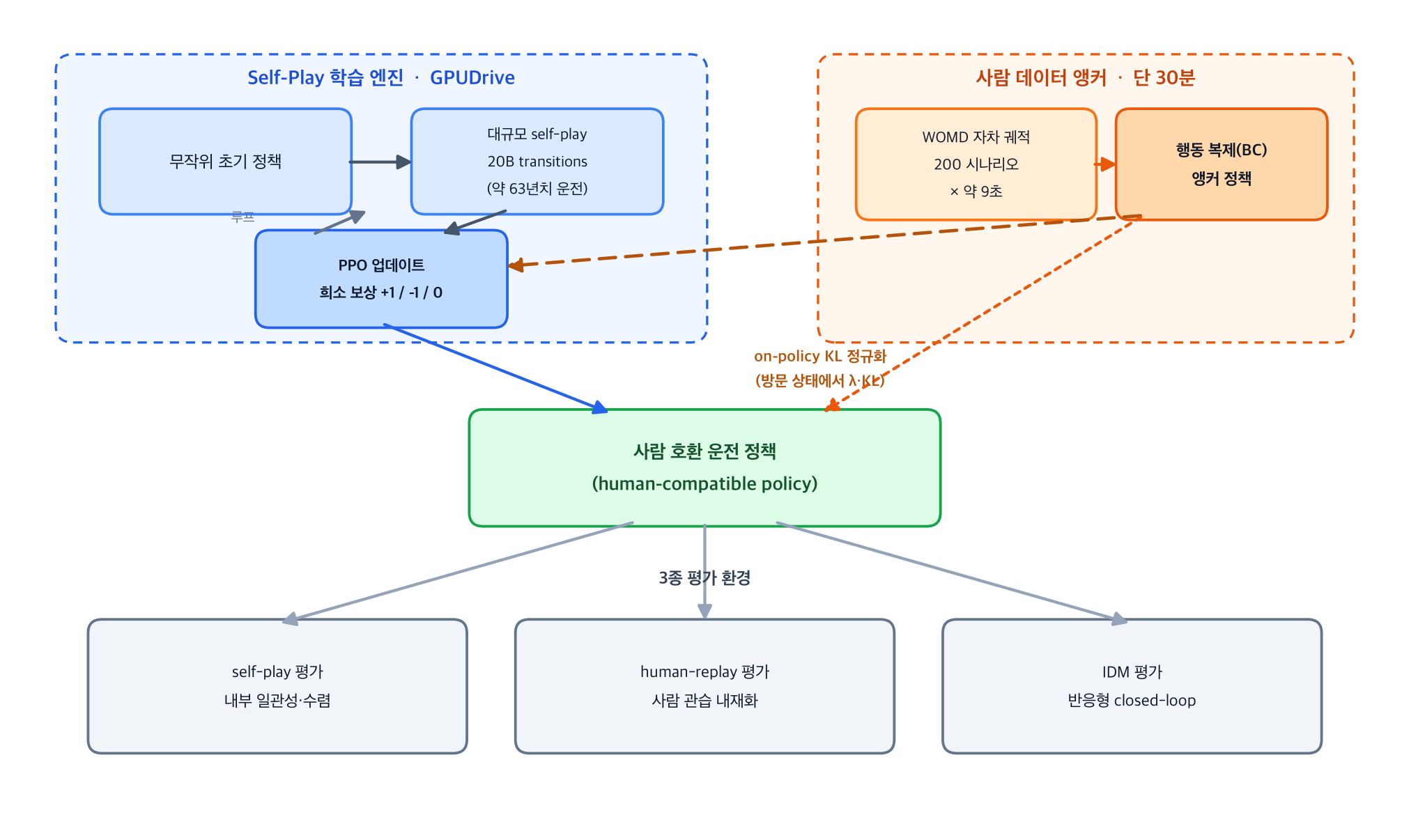
يستحق قرار تصميمي واحد التأكيد. فحدّ KL هذا يسحب السياسة نحو المرساة لا على توزيع البيانات المسجّلة دون اتصال (offline) بل على الحالات التي تزورها السياسة فعلًا، وهو تنظيم على المسار (on-policy). فإن نظّمت فقط على توزيع BC غير المتصل، لا تستطيع منع السياسة من الانحراف عن توزيع الحالة في الحلقة المغلقة الذي تراه عمليًا. أما KL على المسار فيستدعي المرساة عند نقطة انزياح التوزيع تلك بالضبط. يبدو الأمر طفيفًا لكنه يحكم استقرار الحلقة المغلقة.
تُدرَّب سياسة المرساة نفسها بالـ BC على مسارات سيارة القيادة الذاتية فقط. فمسارات المركبات المحيطة مُعاد بناؤها بواسطة طبقة إدراك، لذا فهي مشوّشة وجودة قيادتها غير مضمونة؛ ولذا تُستخدم أنظف إشارة فقط، أي مسار المركبة الذاتية. يُنتج كل سيناريو نحو 9 ثوانٍ من البيانات، فتبلغ 200 سيناريو نحو 30 دقيقة. ولادعاء “أقل بـ 2500 مرة” اشتقاق صريح: 200 سيناريو في 9 ثوانٍ تساوي 30 دقيقة، بينما مجموعة Waymo الكاملة بنحو 500,000 سيناريو في 9 ثوانٍ تساوي نحو 75,000 دقيقة، أي نسبة حوالي 0.0004.
المنهجية الأساسية: من إشارة رئيسية إلى مرساة
هيكل المنهجية نظيف. الخسارة هي حدّ تدرّج السياسة المقصوص (clipped surrogate) في PPO مضافًا إليه خسارة القيمة ومكافأة الإنتروبيا، مع حدّ تنظيم KL فوقها. وهو أقرب إلى تركيب دقيق لمكوّنات معروفة جيدًا منه إلى خوارزمية جديدة.
تكمن المساهمة الحقيقية لا في الجدّة الخوارزمية بل في نظافة القياس التي أتاحتها البنية التحتية. وسّع الباحثون خبرة الـ self-play إلى 20 مليار انتقال على المحاكي عالي الإنتاجية GPUDrive، وهو ما يعادل نحو 63 عامًا من القيادة البشرية. كانت الأعمال السابقة مقيّدة بسرعة المحاكي (نحو 2000 خطوة في الثانية) عند 140 مليون انتقال ونحو 5 أيام تدريب، فلم يتبقَّ مجال لدراسة توسيع كمية بيانات البشر كمحور مستقل. وبإزالة عنق زجاجة الإنتاجية عبر GPUDrive، أصبحت تجربة التوسيع المنفصل لـ”كمية الـ self-play” و”كمية بيانات البشر” ممكنة لأول مرة.
يكشف هذا الفصل عدم تماثل مثير للاهتمام. فانتقالات الـ self-play تُوسَّع حتى 20 مليارًا، بينما بيانات البشر قريبة من التشبّع عند 30 دقيقة. واستخدام مرساة مدتها 30 ساعة لا يغيّر إلا قليلًا. تتسطّح المنفعة الحدّية للبيانات البشرية الإضافية بسرعة، وهذا هو الأساس التجريبي لرسالة أن حفنة تكفي.
النتائج التجريبية الفعلية
مجموعة البيانات هي Waymo Open Motion Dataset (WOMD). ولأجل تقييم human-replay الذي يقيس التوافق البشري، تُرشَّح السيناريوهات لرفع إشارة التفاعل. فمن بين 10,000 سيناريو تحقّق محجوزة، يُسجَّل مسار المركبة الذاتية بحسب مقدار تقاطعه مع مسارات الوكلاء الآخرين، مع الإبقاء على أعلى 200 مشهد تفاعلي فقط مثل الاندماج والإفساح والتقاطعات المزدحمة التي تتطلب تنسيقًا حقيقيًا.
تُلخَّص النتائج الأساسية في المخطط أدناه. كل رقم مُبلَّغ عنه في الورقة؛ ولا شيء مُختلَق.
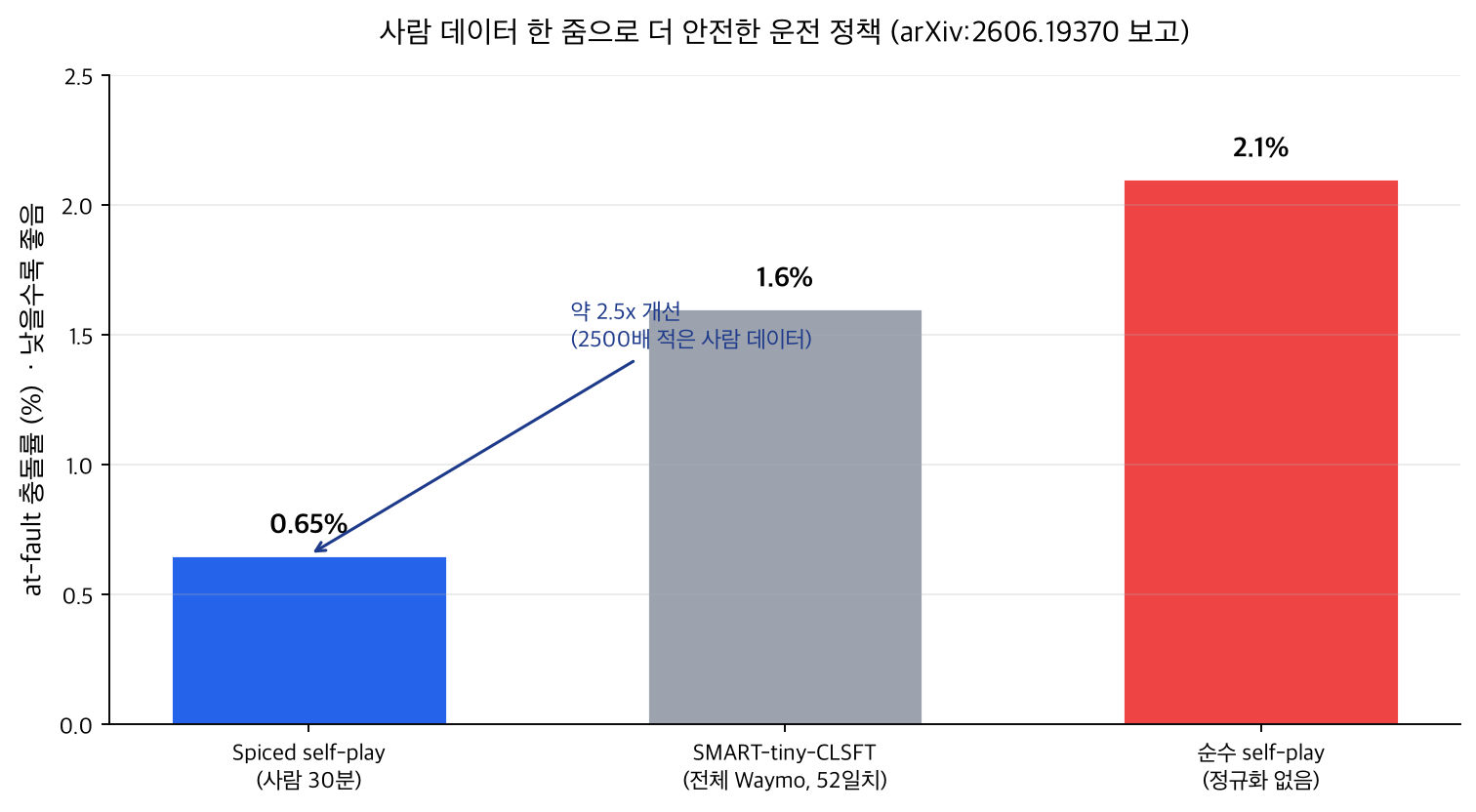
النقاط الأساسية كما يلي.
- يحقّق spiced self-play معدل اصطدام بخطأ ذاتي بين 0.6% و0.7% ببيانات بين 30 دقيقة و3 ساعات. ومقارنة بخط الأساس للتعلّم بالتقليد SMART-tiny-CLSFT (1.6%، مُدرَّب على مجموعة Waymo الكاملة، نحو 52 يومًا من البيانات)، يمثّل ذلك تحسّنًا بنحو 2.5 مرة.
- بلغ معدل الاصطدام بخطأ ذاتي لـ self-play النقي دون تنظيم 2.1%. وإضافة حفنة من المرساة فقط جعلته أكثر أمانًا بنحو 3.5 مرة.
- يتجنّب التقييم التباهي بمقياس واحد. فهو ينظر إلى النتيجة ومعدل الإكمال ومعدل الاصطدام ومعدل الاصطدام بخطأ ذاتي وشدّة الاصطدام Δv عبر ثلاث بيئات: self-play (يتشارك جميع الوكلاء السياسة)، وhuman-replay (المركبة الذاتية فقط هي السياسة، والبقية تعيد تشغيل السجلات)، وIDM (الآخرون قائمون على قواعد وتفاعليون).
يختلف الاتساق الداخلي أيضًا. فيُبقي spiced self-play معدل الاصطدام دون 1.5% في بيئة الـ self-play وفي cross-play مع سجلات البشر، بينما يرتفع خط أساس التعلّم بالتقليد إلى نحو 6% في بيئة الـ self-play، مُظهرًا اتساقًا أضعف. ويوضّح الباحثون أن عدم استقرارية بيئة الـ self-play، أي توزيع شريك متغيّر يتحوّل فيه خصم شبه عشوائي ابتداءً إلى كفء تدريجيًا، تساعد فعلًا على التقارب نحو أعراف متبادلة متّسقة.
لكن ليست كل الصورة وردية. فمقياس Waymo Open Sim Agent Challenge (WOSAC) الميتا للواقعية التوزيعية يرتفع من 0.68 لـ self-play النقي إلى 0.725 للنسخة المُنظَّمة، لكن المكسب صغير نسبةً إلى التحسّن الدرامي في الأمان وغير حسّاس تقريبًا للبيانات المضافة. فقد تكون السياسة آمنة وأقل شبهًا بالبشر توزيعيًا في الوقت ذاته، وهي نقطة نعود إليها أدناه.
التطبيق على منصّة ThakiCloud للـ AI/ML SaaS على K8s
القيادة بحد ذاتها ليست مجال ThakiCloud المباشر. ومع ذلك تنتقل الدروس المنهجية لهذه الورقة بشكل شبه مباشر إلى بنيتنا متعددة الوكلاء والتعلّم المعزّز والمحاذاة.
أولًا، مبدأ “بيانات البشر كمرساة خفيفة لا كإشارة رئيسية” يتوافق مع نموذج تكلفة حلقات الـ self-harness وتطوّر الوكلاء لدينا. فـ ThakiCloud تُشغّل أصلًا نمط “ابدأ رخيصًا، وارتقِ إلى المكلف فقط عبر المراجعة والتحقّق”: تشغيل عمّال منخفضي التكلفة أولًا والترقية إلى نموذج أعلى طبقة فقط عند رصد فشل متكرر. وتدعم هذه الورقة كميًّا النسخة المعزّزة من ذلك النمط، حيث الخبرة التركيبية الرخيصة هي المحرّك الرئيسي والعروض البشرية المكلفة مجرّد مرساة تنظيم صغيرة. ويمكننا استعارتها كمعيار لـ”كم نستطيع تقليل وسم البشر مع الحفاظ على المحاذاة” في تدريب وضبط أسطول وكلائنا.
ثانيًا، فكرة تنظيم KL على المسار لها إمكان قوي للدمج مع بوّابة التحقّق fan-out لدينا. فيمكننا إطلاق عمّال كثيرين بحرية كالـ self-play، ثم تثبيتهم بمجموعة صغيرة من المسارات الذهبية المعتمدة بشريًا تحت تنظيم KL لكبح الانحراف نحو أعراف غريبة مثل الهلوسة أو انحراف التنسيق. والمفتاح هو تطبيق التنظيم لا على مجموعة ذهبية ثابتة غير متصلة بل على الحالات التي يزورها العمّال فعلًا، وهي بنية تستحق إثبات مفهوم على منصّتنا.
ثالثًا، عدم التماثل بين مقاييس الأمان والواقعية التوزيعية تحذير لتصميم تقييمنا. فالتباهي بالجودة بنتيجة إجمالية واحدة يُخفي الركود على محاور أخرى كالواقعية التوزيعية. ينبغي أن تملك الشيفرة البوّابات، لكن المعيار يجب أن يكون منظومة تقييم متعددة الطبقات تقيس الأمان والواقعية والاتساق على حدة بدل رقم واحد.
أخيرًا، ثمة نقطة فخر واضحة. فبنية تكلفة قوامها 15 ساعة على GPU استهلاكي واحد تشير إلى الاتجاه ذاته الذي أكّدته ThakiCloud: التشغيل في الموقع وكفاءة التكلفة والاستضافة الذاتية. وهذا يعني أن تجارب المحاذاة كهذه يمكن إعادة إنتاجها وتشغيلها بتكلفة معقولة على مكدّس K8s لدينا، بجدولة وحدات GPU عبر Kueue والخدمة عبر vLLM، دون خط أنابيب ضخم لبيانات البشر.
الحدود والاعتراضات
إنه عمل علمي تجريبي رصين، لكن بقراءة نقدية تبقى ثلاثة توتّرات.
أكبر نقطة ضعف أن ادعاء التعميم يستند إلى مجال واحد، القيادة. فالخاتمة تلمّح مرارًا إلى أن “الدروس قد تتعمّم خارج القيادة”، لكن كل التجارب على بيانات قيادة Waymo. ولا يوجد تحقّق في مجالات أخرى يتحقّق فيها الافتراض “المحاكاة رخيصة ومقياس السلوك المرغوب واضح”، مثل التفاوض أو الألعاب التعاونية أو الروبوتات. وهو يقصر عن العمومية التي توحي بها كلمة “emerges” في العنوان.
ثانيًا، عدم التماثل بين مكاسب الواقعية التوزيعية ومكاسب الأمان غير مُفسَّر بالكامل. فانتقال مقياس WOSAC الميتا من 0.68 إلى 0.725 متواضع بجانب التحسّن الكبير في معدل الاصطدام، وهو غير حسّاس لمزيد من البيانات. فقد تكون السياسة آمنة وأقل شبهًا بالبشر توزيعيًا، وهو ما يتوتّر مع العنوان القوي “human-like autonomy emerges”. وعدم مواجهة المتن لهذه الفجوة مباشرة يترك مجالًا للمبالغة في الادعاء.
ثالثًا، الحدّ في أصعب سيناريوهات التنسيق محجوز في قسم الحدود. فيعترف الباحثون أنفسهم بانخفاض الأداء على أصعب 200 سيناريو تفاعلي. فإن كانت أعلى كثافة من الاندماجات والتقاطعات، حيث يكون الأمان أهم، هي الأضعف، فإن هذا الضعف يستحق أن يجلس بجانب النتيجة الرئيسية بدل تأجيله. وعلاوة على ذلك، فإن تحليل حساسية قوة التنظيم λ ضعيف، وثمة فحص غير كافٍ لما إذا كانت سياسة مرساة واحدة تلتقط تنوّع القيادة البشرية.
باختصار، الجوهر ليس خوارزمية جديدة بل توسيع فكرة قائمة بنظافة على محاكٍ عالي الإنتاجية لتثبيت “حفنة من بيانات البشر تكفي”. وقابلية إعادة الإنتاج والتقييم متعدد الطبقات والمقارنة الأمينة مع الأعمال السابقة نقاط قوة؛ وادعاء التعميم أحادي المجال وركود الواقعية التوزيعية نقاط ضعف. وبالنسبة لمنصّة مثل منصّتنا، يُقرأ كحجة مقنعة لنموذج تكلفة يحافظ على المحاذاة مع تقليل الإشارة البشرية المكلفة.
المصادر
- الورقة: Human-like autonomy emerges from self-play and a pinch of human data (arXiv:2606.19370)، https://arxiv.org/abs/2606.19370
- Hugging Face Papers: https://hf.co/papers/2606.19370
- صفحة المشروع (مقاطع فيديو والمصدر الكامل): https://spiced-self-play.com/
📄 المراجعة المتعمقة الكاملة (DOCX): نزّل المراجعة التفصيلية من Google Drive.