사람 데이터 한 줌이면 충분합니다: self-play 운전 정책에 사람을 정규화 앵커로 거는 법
개요
시뮬레이션으로 경험을 무한정 찍어낼 수 있는 시대가 되면서, 한 가지 질문이 점점 더 날카로워지고 있습니다. 사람의 데이터는 도대체 얼마나, 어떤 방식으로 섞어야 쓸모가 있을까요. 운전 정책 학습에서 이 질문은 비용과 직결됩니다. 사람의 운전 시연을 대규모로 수집하는 일은 비싸고 느린 반면, 시뮬레이터 안의 자가 대국(self-play)은 값싸고 거의 무한합니다.
NYU와 프린스턴 등이 함께 낸 논문 “Human-like autonomy emerges from self-play and a pinch of human data”(arXiv:2606.19370, 2026년 6월)는 이 질문에 명쾌한 답을 제시합니다. 제목 그대로 “한 줌(a pinch)”이면 충분하다는 것입니다. 구체적으로는 단 30분 분량의 사람 운전 데이터로, 모방학습(imitation learning) 대비 2500배 적은 양을 쓰면서도 더 사람 호환적인 정책을 얻습니다. 학습 전체는 소비자용 GPU 한 장에서 15시간 만에 끝납니다.
이 글은 운전 도메인의 결과를 소개하는 데 그치지 않습니다. ThakiCloud처럼 멀티테넌트 환경에서 여러 에이전트를 학습하고 정렬해야 하는 플랫폼 관점에서, “값싼 합성 경험을 주 엔진으로 두고 비싼 사람 신호는 소량의 정규화 앵커로만 거는” 이 설계가 왜 비용 모델과 정합하는지를 함께 따져 봅니다.
📄 심층 리뷰 전문(DOCX): 이 논문의 상세 피어리뷰를 Google Drive에서 다운로드할 수 있습니다.
이 연구는 무엇인가
순수 self-play 강화학습은 사람 데이터 없이도 운전 정책을 학습시킬 수 있습니다. 문제는 보상이 “목적지에 안전하게 도달하라” 수준으로만 주어질 때 발생합니다. 이런 희소한 보상 아래에서 정책은 효과적이되 사람과 호환되지 않는(alien) 관습으로 수렴해 버립니다. 후진으로, 옆으로, 때로는 역주행으로 목표에 도달해도 보상에 위배되지 않으면 모델은 기꺼이 그렇게 합니다. 보상만 채우면 그만이기 때문입니다.
기존 해법은 보상 설계를 정교하게 다듬거나 도메인 무작위화를 동원하는 것이었습니다. 둘 다 손이 많이 가고 깨지기 쉽습니다. 이 논문의 처방은 발상을 뒤집습니다. 사람 데이터를 주 학습 신호로 쓰는 대신, 행동 복제(behavioral cloning, BC)로 만든 앵커 정책을 정규화 항으로 얹습니다. 보상은 여전히 희소하게 최소한만 유지하고(목표 도달 +1, 충돌이나 도로 이탈 -1, 그 외 0), PPO 손실에 앵커 정책으로 향하는 KL 항을 더합니다. 정규화 강도는 λ가 조절하며, λ가 0이면 정규화 없는 순수 self-play로 되돌아갑니다.
전체 구조는 아래 도표와 같습니다. 값싼 self-play 엔진이 주 동력이고, 30분짜리 사람 앵커는 KL 정규화라는 가는 끈으로 정책을 사람 쪽으로 살짝 당겨 줍니다.
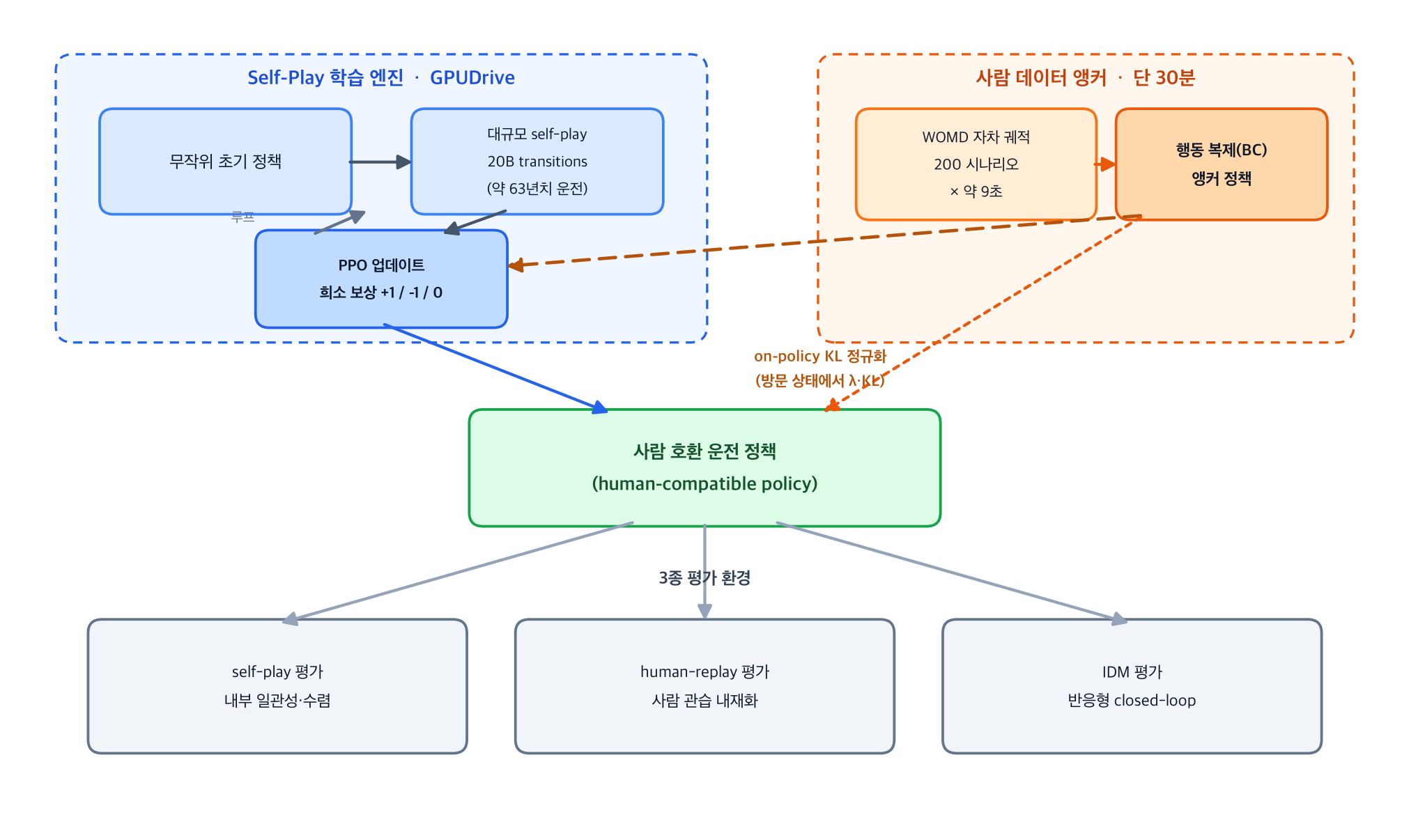
여기서 가장 중요한 설계 결정 하나를 짚어야 합니다. 이 KL 항은 로그로 저장된 오프라인 데이터 분포가 아니라, 정책이 실제로 방문하는 상태(visited states)에서 정책을 앵커 쪽으로 당깁니다. 이른바 on-policy 정규화입니다. 오프라인 BC 분포에서만 정규화를 걸면, 정책이 실제로 굴러갈 때의 closed-loop 상태 분포에서 벗어나는 것을 막지 못합니다. 반면 방문 상태에서 거는 KL은 바로 그 분포 시프트 지점에서 앵커를 끌어옵니다. 사소해 보이지만 closed-loop 안정성을 좌우하는 선택입니다.
앵커 정책 자체는 자차(self-driving car) 궤적만 골라 BC로 학습합니다. 주변 차량의 궤적은 지각 스택으로 복원된 것이라 노이즈가 많고 운전 품질도 보장되지 않으니, 가장 깨끗한 신호인 자차 궤적만 씁니다. 한 시나리오당 약 9초의 데이터가 나오므로 200개 시나리오가 곧 약 30분이 됩니다. “2500배 적다”는 주장의 산식도 명시돼 있습니다. 200 시나리오 곱하기 9초는 30분, 전체 Waymo 약 50만 시나리오 곱하기 9초는 약 7만 5천 분이므로 비율이 0.0004 수준이라는 것입니다.
핵심 방법: 사람을 주 신호에서 앵커로
방법의 골격은 깔끔합니다. 손실은 PPO의 clipped surrogate 정책 경사 항에 value 손실과 entropy 보너스를 더하고, 거기에 KL 정규화 항을 추가한 형태입니다. 새 알고리즘이라기보다, 잘 알려진 구성 요소들의 신중한 조합에 가깝습니다.
이 논문의 진짜 기여는 알고리즘의 새로움이 아니라 인프라가 풀어낸 측정의 깨끗함에 있습니다. 저자들은 처리량(throughput)이 높은 시뮬레이터 GPUDrive 위에서 self-play 경험을 200억(20B) transition까지 키웠습니다. 이는 사람 운전 약 63년치에 해당하는 규모입니다. 선행 연구들은 시뮬레이터 속도(초당 약 2000 step)에 묶여 1억 4천만 transition, 학습 5일 정도에 머물렀고, 그래서 “사람 데이터 양”을 독립 축으로 두고 스케일링을 분석할 여지 자체가 없었습니다. GPUDrive로 throughput 병목을 제거함으로써, “self-play 양”과 “사람 데이터 양”을 분리해 따로 키워 보는 실험이 처음으로 가능해졌습니다.
이 분리 덕분에 흥미로운 비대칭이 드러납니다. self-play transition은 200억까지 키우는 반면, 사람 데이터는 30분에서 이미 포화에 가깝습니다. 30시간짜리 앵커를 써도 결과가 크게 달라지지 않습니다. 추가되는 사람 데이터의 한계 효용이 빠르게 평탄해진다는 뜻이며, 이것이 “한 줌이면 충분하다”는 메시지의 실증적 근거입니다.
실제 실험 결과
데이터셋은 Waymo Open Motion Dataset(WOMD)입니다. 사람 호환성을 측정하는 human-replay 평가에서는 상호작용 신호를 높이기 위해 시나리오를 필터링합니다. 1만 개의 held-out 검증 시나리오 가운데 자차 궤적이 다른 에이전트 궤적과 교차하는 정도로 점수를 매겨, 합류와 양보, 혼잡한 교차로처럼 실제로 조율이 필요한 상위 200개 장면만 남깁니다.
핵심 결과는 아래 차트로 요약됩니다. 모든 수치는 논문이 보고한 값이며, 임의로 만든 숫자는 없습니다.
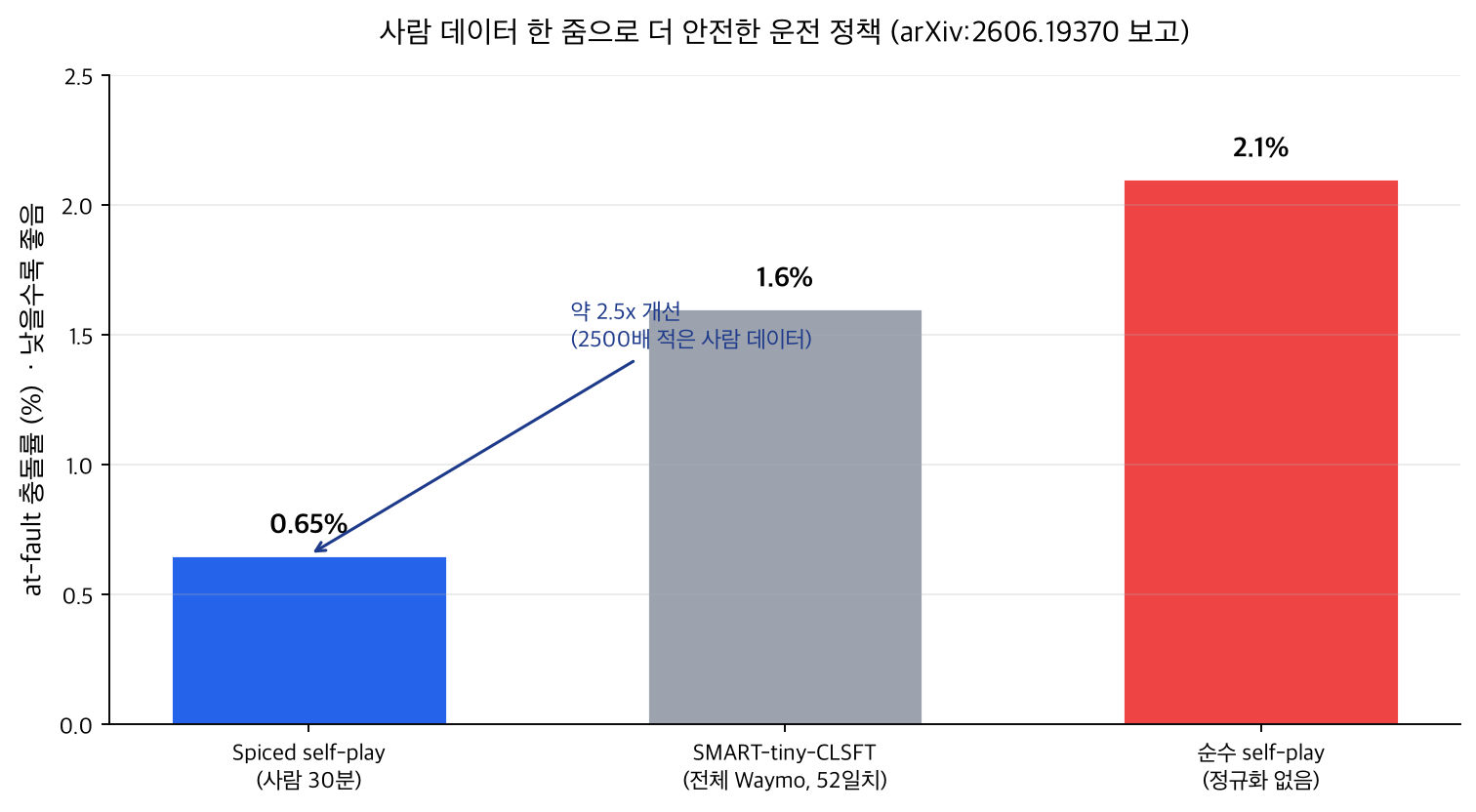
요점을 정리하면 다음과 같습니다.
- spiced self-play는 30분에서 3시간 사이의 데이터로 at-fault 충돌률 0.6~0.7%를 달성합니다. 전체 Waymo(약 52일치)로 학습한 모방학습 기준선 SMART-tiny-CLSFT의 1.6%와 비교하면 약 2.5배 개선입니다.
- 정규화가 전혀 없는 순수 self-play의 at-fault 충돌률은 2.1%였습니다. 한 줌의 앵커를 더한 것만으로 약 3.5배 안전해진 셈입니다.
- 평가는 단일 지표 자랑을 피합니다. self-play(전 에이전트가 같은 정책), human-replay(자차만 정책, 나머지는 로그 재생), IDM(나머지는 규칙 기반 반응형)이라는 3종 환경에 score, completion rate, collision rate, at-fault collision rate, 그리고 충돌 심각도 Δv까지 여러 지표를 함께 봅니다.
내부 일관성에서도 차이가 납니다. spiced self-play는 self-play 환경과 사람 로그 cross-play 양쪽에서 충돌률이 1.5% 미만으로 안정적인 반면, 모방학습 기준선은 self-play 환경에서 약 6%까지 충돌률이 올라가 일관성이 떨어집니다. 저자들은 self-play 환경의 비정상성(non-stationarity), 즉 초기에는 거의 무작위였던 상대가 점점 유능해지는 변화하는 파트너 분포가 오히려 상호 일관된 관습으로의 수렴을 돕는다고 설명합니다.
다만 모든 그림이 장밋빛은 아닙니다. 분포적 사실성(distributional realism)을 보는 Waymo Open Sim Agent Challenge(WOSAC) 메타 점수는 순수 self-play 0.68에서 정규화 self-play 0.725로 오르지만, 안전 지표에서의 극적 개선에 비하면 폭이 작고 추가 데이터에도 거의 둔감합니다. 안전하지만 분포적으로는 여전히 덜 사람다울 수 있다는 뜻이며, 뒤에서 다시 다룹니다.
ThakiCloud K8s AI/ML SaaS 플랫폼 적용 및 시사점
운전 도메인 자체는 ThakiCloud의 직접 영역이 아닙니다. 그러나 이 논문이 던지는 방법론적 교훈은 우리의 멀티에이전트, 강화학습, 정렬 인프라 설계에 거의 그대로 이전됩니다.
첫째, “사람 데이터를 주 신호가 아니라 경량 앵커로”라는 원칙은 우리 self-harness와 에이전트 진화 루프의 비용 모델과 정합합니다. ThakiCloud는 이미 “싸게 시작해서 회고와 검증으로만 비싸게 승격하는” 패턴을 운용합니다. 저비용 워커로 먼저 돌리고, 반복 실패가 감지될 때만 상위 모델로 올리는 방식입니다. 이 논문은 그 패턴의 강화학습 버전을 정량적으로 뒷받침합니다. 값싼 합성 경험이 주 엔진이고, 비싼 사람 시연은 소량의 정규화 앵커일 뿐입니다. 우리 에이전트 fleet 학습과 튜닝에서 “사람 라벨을 얼마나 적게 써도 정렬이 유지되는가”를 가늠하는 벤치마크로 차용할 수 있습니다.
둘째, on-policy KL 정규화라는 발상은 우리의 fan-out 검증 게이트와 결합할 여지가 큽니다. 다수의 워커를 self-play처럼 자유롭게 풀어놓되, 사람이 승인한 소량의 골든 트레이스를 앵커로 삼아 KL 정규화를 걸면, 워커가 환각이나 포맷 일탈 같은 alien convention으로 발산하는 것을 억제할 수 있습니다. 핵심은 정규화를 정적인 오프라인 골든셋이 아니라 워커가 실제로 방문한 상태에서 건다는 점입니다. 우리 플랫폼에서 PoC로 검증해 볼 만한 구조입니다.
셋째, 안전 지표와 분포 사실성의 비대칭은 우리 평가 설계에 보내는 경고입니다. 하나의 aggregate 점수로 품질을 자랑하면 분포 사실성 같은 다른 축의 정체를 가립니다. 게이트는 코드가 소유하되, 단일 지표가 아니라 안전, 사실성, 일관성을 분리 측정하는 다층 평가 하니스를 표준으로 두어야 합니다.
마지막으로 자랑 포인트가 하나 있습니다. 소비자용 GPU 한 장에서 15시간이면 끝나는 비용 구조는, ThakiCloud가 강조해 온 온프렘과 비용 효율, self-hosting 메시지와 정확히 같은 방향을 가리킵니다. 대규모 사람 데이터 파이프라인 없이도, Kueue로 GPU를 스케줄링하고 vLLM로 서빙하는 우리 K8s 스택 위에서 이런 정렬 실험을 합리적 비용으로 재현하고 운용할 수 있다는 의미입니다.
한계 및 반론
견고한 실험과학 논문이지만, 비판적으로 읽으면 세 가지 긴장이 남습니다.
가장 큰 약점은 일반화 주장의 근거가 운전이라는 단일 도메인에 머문다는 점입니다. 결론부에서 “교훈이 운전을 넘어 일반화될 수 있다”고 반복해 암시하지만, 실험은 전부 Waymo 운전 데이터입니다. “시뮬레이션이 싸고 바람직한 행동의 지표가 명확할 때”라는 전제가 충족되는 다른 도메인, 가령 협상이나 협력 게임, 로보틱스에서의 검증은 없습니다. 제목의 “emerges”가 시사하는 보편성에는 아직 미치지 못합니다.
둘째, 분포 사실성 개선과 안전 지표 개선의 비대칭이 충분히 설명되지 않습니다. WOSAC 메타 점수 0.68에서 0.725로의 변화는 충돌률의 큰 개선에 비하면 미미하고 데이터 추가에도 둔감합니다. 안전하지만 분포적으로는 여전히 덜 사람다운 정책일 수 있다는 뜻이며, 이는 “human-like autonomy emerges”라는 강한 제목과 긴장 관계에 있습니다. 본문이 이 간극을 정면으로 다루지 않는 것은 다소 과한 주장(over-claim)의 소지가 있습니다.
셋째, 가장 빡빡한 조율 시나리오에서의 한계가 한계 절로 격리돼 있습니다. 저자들 스스로 상위 200개 최난도 상호작용 시나리오에서 성능이 떨어진다고 인정합니다. 안전이 가장 중요한 고밀도 합류나 교차로가 가장 약하다면, 그 약점은 한계로 미뤄 둘 것이 아니라 주요 결과 옆에 나란히 놓이는 편이 공정합니다. 이 밖에도 정규화 강도 λ의 민감도 분석이 얇고, 앵커를 단일 정책으로 두어 사람 운전의 다양성을 충분히 담는지에 대한 검토가 부족하다는 점이 보완 과제로 남습니다.
종합하면, 새 알고리즘이라기보다 기존 발상을 고처리량 시뮬레이터 위에서 깨끗하게 스케일링해 “사람 데이터 한 줌이면 충분하다”를 정량적으로 못 박은 점이 이 논문의 본질입니다. 재현성과 평가 다층화, 선행 연구와의 정직한 대비가 강점이고, 일반화 주장의 도메인 단일성과 분포 사실성의 정체가 약점입니다. 우리 같은 플랫폼 입장에서는 “비싼 사람 신호를 최소화하면서 정렬을 유지하는” 비용 모델의 설득력 있는 사례로 읽을 가치가 충분합니다.
출처
- 논문: Human-like autonomy emerges from self-play and a pinch of human data (arXiv:2606.19370), https://arxiv.org/abs/2606.19370
- Hugging Face Papers: https://hf.co/papers/2606.19370
- 프로젝트 페이지(영상·전체 소스): https://spiced-self-play.com/
📄 심층 리뷰 전문(DOCX): 이 논문의 상세 피어리뷰를 Google Drive에서 다운로드할 수 있습니다.