AI Agents That Write Papers - Moving Your Writing Workflow to an Open-Source Skill Package
As a paper deadline approaches, researchers repeat the same tasks: polish the introduction, verify that the abstract’s claims and evidence align, and preemptively fix any sentence a reviewer might target. That expertise typically lives inside an advisor’s head or scattered across notes. Research-Paper-Writing-Skills, a recently trending open-source project on X, packages exactly that expertise into a Skill package that AI coding agents can call directly. The key distinction is that this is not yet another collection of prompts – it is a portable format that plugs the same capability into Codex, Claude Code, and Gemini alike.
Overview
This project is built on top of learning_research, a research primer published by Professor Pengsi Da (pengsida) of Zhejiang University in China. It reframes that paper-writing knowledge as an Agent Skill package. According to the repository description, the package focuses on ML, CV, and NLP paper writing, and was curated and structured specifically for Codex, Claude Code, and Gemini. The contribution is not a copy of the original text – it takes scattered advice, breaks it into work units, and turns each unit into a reusable capability that an agent can invoke.
Why is this format attracting attention now? As AI coding agents have become mainstream, people have started treating not the model itself but “what to ask the model and how” as a durable asset. Well-organized task knowledge, once created, replicates across tools and teams. Tasks with clear procedures and explicit quality criteria – paper writing being a prime example – are a natural fit for this format. ThakiCloud already organizes much of its internal operations around hundreds of Skills, so we read this trend as a structural shift in how agents are run, not a passing fad.
What is an Agent Skill
An Agent Skill is a package that tells an agent how to perform a specific task. It centers on a SKILL.md instruction file and optionally includes reference documents, scripts, and templates. It has three defining properties. First, it is version-controlled: stored in a repository and tracked over time, it accumulates as an asset rather than a one-off prompt. Second, it is loaded on demand: instead of stuffing all knowledge into the context every time, only the Skills relevant to the current task are loaded. Third, it is harness-independent: the same Skill can be used in Claude Code, Codex, and Gemini – that is the design goal.
The third property best explains the value of this project. Models keep changing, and CLI tools keep changing. But “how to write a strong introduction” as task knowledge outlasts both by a wide margin. Accumulating capability in the Skill rather than in the tool means that expertise does not have to be rebuilt every time the tool changes. Internally, we call this the “thin harness, fat Skills” principle: keep the model loop, permissions, and file I/O thin; pack domain knowledge, judgment, and failure cases thickly into the Skill.
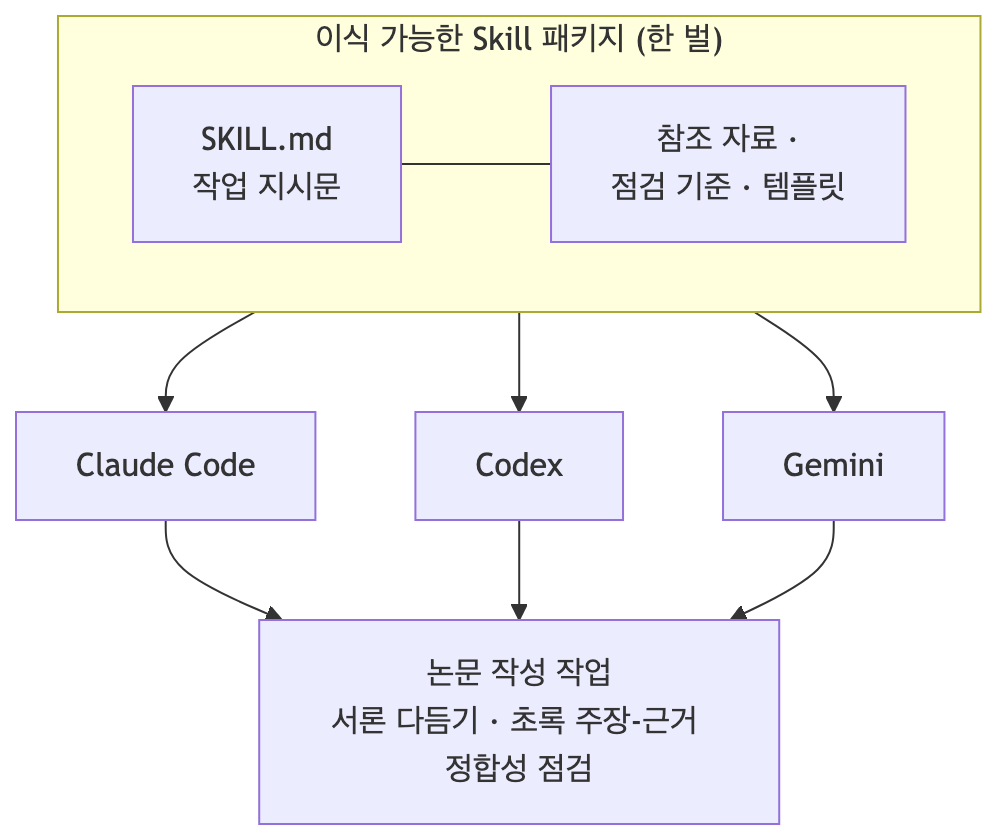
The central point of the diagram is that there is exactly one Skill package in the middle. The three tools are not each carrying separate prompts – they share the same task knowledge. That is the fundamental difference from pasting a one-liner prompt into a chat window.
Research-Paper-Writing-Skills in Detail
The tasks this package covers map directly to the actual stages of writing a paper. Published usage examples show calling $research-paper-writing to refine an introduction, or invoking the Skill to rewrite an abstract and verify that claims and evidence are properly paired. Rather than a vague “write this better” request, the design separates the recurring sub-tasks of paper writing into distinct, callable capabilities. This matches the principle that one verb should produce one deliverable.
The multi-harness orientation is also notable. A user can activate the same capability by simply copying the package to the Skill directory recognized by whichever tool they use. This direction is not unique to this project – several recently published open-source efforts, including academic Skill collections centered on Codex and general-purpose AI research Skill libraries, share the same orientation. It is a signal that a simultaneous push is underway to move the entire research workflow into a Skill ecosystem.
One point worth being explicit about: this post is based on the public description and usage examples from the repository. Specific counts such as star ratings, or internal file structures, can change over time and are not stated as fixed facts here. If you are evaluating adoption, check the repository directly along with the license and attribution requirements for the original author’s notes.
Installation and Use
The installation model for Agent Skills is generally straightforward. Clone the package and place it in the Skill path recognized by the tool you use; the agent then loads the relevant Skill for each task. The general flow is:
# Clone the repository
git clone https://github.com/Master-cai/Research-Paper-Writing-Skills.git
# Copy to the Skill directory of your tool (check each tool's docs for the exact path)
# Example: place under .claude/skills/ in a Claude Code project
cp -r Research-Paper-Writing-Skills/<skill-dir> .claude/skills/
Once placed, invoke the Skill from an agent session to request work – ask in natural language to refine an introduction draft or check whether the abstract’s claims and evidence are consistent, and the procedures and criteria embedded in the Skill are applied. Because the Skill path and invocation convention differ slightly by tool, follow each tool’s documentation for the actual placement path. The key point is that a Skill placed once is reused across all sessions in that tool. The overhead of copying the same prompt repeatedly disappears.
Applying It on the ThakiCloud K8s AI/ML SaaS Platform
ThakiCloud’s AI platform runs agents and batch workloads for diverse customers on top of Kubernetes. Our internal operations are already organized around Skills, so the format this project demonstrates is familiar. What matters more is that the same pattern is spreading rapidly in the broader community.
First, there is direct value for data scientists and researchers. Teams working on the platform write papers and technical reports regularly. Attaching proven paper-writing Skills to the standard internal toolchain lets teams apply consistent standards to error-prone areas such as introduction structure and abstract claim-evidence alignment – raising average quality without upgrading the model tier.
Second, harness independence pairs well with multi-tenant operations. Different customers may prefer different agent environments, but encapsulating capability in a Skill allows the same task knowledge to be reused regardless of environment. Capability is not locked to any one vendor’s tool, which makes it straightforward to port the same asset into on-premises deployments where customers have strong self-hosting requirements. That aligns with our strategy around self-hosting and cost efficiency.
Third, this project reinforces the lesson that Skills need to be managed as operational assets with discipline. A Skill carries a per-session context cost from the moment it is indexed. We therefore apply a question to every new Skill: “would the agent make a mistake without this?” We also document failure cases explicitly. Applying the same gate to externally sourced Skills prevents a growing Skill library from degrading retrieval accuracy – a real risk when the corpus exceeds what a retriever can distinguish cleanly.
Limitations and Counterpoints
This approach has clear weaknesses. First, there are no published objective metrics for the quality of text the package produces. Paper writing is inherently a judgment-intensive task, and whether the Skill-generated draft meets a human reader’s standard ultimately requires human review. That is why this post includes no performance figures – fabricating numbers without empirical measurement is exactly what should be avoided.
Second, there is the question of provenance and derivative works. This package is a repackaging of someone else’s public notes. Even though the original author is credited, organizations adopting it bear the responsibility to verify the license terms and the scope of required attribution themselves – more so when embedding it in internal standards.
Third, writing assistance does not replace thinking. A strong introduction comes from strong research. A Skill helps with expression and checking; it cannot transform thin results into a substantive paper. Distinguishing clearly between what the tool can supply and what the researcher must own is the prerequisite for using this format in a healthy way.
Sources
- Research-Paper-Writing-Skills: https://github.com/Master-cai/Research-Paper-Writing-Skills
- Original research primer learning_research (pengsida): https://github.com/pengsida/learning_research