NVIDIA GLM-5.2-NVFP4: Serving a 753B Frontier MoE at 4-Bit Precision
 A conceptual visualization of 16-bit weights being compressed down to 4-bit.
A conceptual visualization of 16-bit weights being compressed down to 4-bit.
For teams trying to serve a frontier-class reasoning model on their own infrastructure, the first obstacle is almost always GPU memory. Loading 753B parameters at 16-bit requires close to 1.5 TB of memory, which translates directly to multiple GPU nodes. nvidia/GLM-5.2-NVFP4, released on Hugging Face on June 25, 2026, is NVIDIA’s attempt to lower that barrier by quantizing ZAI’s (zai-org) GLM-5.2 to 4-bit precision.
This post is not an introduction to GLM-5.2 as a model. How the model’s long reasoning token lengths change the economics of self-hosting is covered in the reasoning token economics post, and the 1-bit GGUF quantization for consumer hardware is covered in the Unsloth GGUF post. The focus here is the datacenter track: what architectural choices NVIDIA’s NVFP4 quantization makes, what hardware it targets, how serving is set up, and what it means for teams running multi-tenant inference.
All accuracy figures in this post are official measurements published by NVIDIA in the model card. Because the 753B model requires NVIDIA Blackwell with 8-way tensor parallelism, we were not able to reproduce results in ThakiCloud’s development environment. This post is therefore an analysis based on public information; no numbers have been fabricated. Values that could not be independently verified are marked [estimated].
Overview
nvidia/GLM-5.2-NVFP4 is a quantized version of ZAI’s zai-org/GLM-5.2, produced with NVIDIA Model Optimizer (ModelOpt). The base model is a Mixture-of-Experts (MoE) architecture designed for reasoning and coding. Of its 753B total parameters, only 40B are activated per token. The network architecture is GlmMoeDsaForCausalLM, and it supports contexts up to 1M tokens through sparse attention using an IndexShare indexer. The license is MIT, identical to the base model, allowing both commercial and non-commercial use.
The key idea in one sentence: MoE reduces compute, and selective NVFP4 quantization reduces memory, while deliberately excluding accuracy-sensitive components from quantization. The MoE structure ensures that despite 753B total parameters, inference cost per token is bounded by the 40B active experts. NVFP4 then reduces the memory footprint of the routing experts, which hold the vast majority of parameters, from 16-bit to 4-bit. The shared experts, however, remain in BF16, minimizing accuracy loss.
The timing also carries a signal. The trend of strong open-weight models being released under MIT, combined with NVIDIA immediately repackaging them into deployable form optimized for its own hardware, is becoming a pattern. For organizations thinking about model sovereignty, this is not an abstract policy question; it is a concrete architecture decision: which GPUs, which model, and how.
What this model is
GLM-5.2 is a MoE reasoning and coding model released by ZAI. Unlike conventional dense models, it places multiple expert networks inside each transformer block and activates only a subset per input token. GLM-5.2 has 753B total parameters, but when generating a single token, only 40B active parameters participate in the computation. In other words, the model’s knowledge capacity is at the 753B scale, but inference compute cost is closer to a 40B dense model.
In addition, GLM-5.2 uses sparse attention through an IndexShare indexer. The design supports a 1M-token context window while avoiding the quadratic cost of full attention over all token pairs. The model card labels this architecture glm_moe_dsa and requires transformers>=5.3.0. These two forms of sparsity, MoE sparsity and attention sparsity, combine to deliver frontier-level reasoning capability at comparatively contained compute.
NVFP4 is a 4-bit floating-point data type defined by NVIDIA. The key distinction from integer 4-bit is that it is floating-point. Specifically, it groups 16 small floating-point (E2M1) values into a block and attaches a per-block FP8 (E4M3) scale, a two-level block-scaling scheme. Because the dynamic range is tracked per block, tail values in the distribution are better preserved than with simple integer quantization. NVIDIA is explicit in the model card that this is a quantized third-party model rather than one NVIDIA trained from scratch, and that the open-source NVIDIA Model Optimizer was used for quantization.
The core design decision: selective quantization
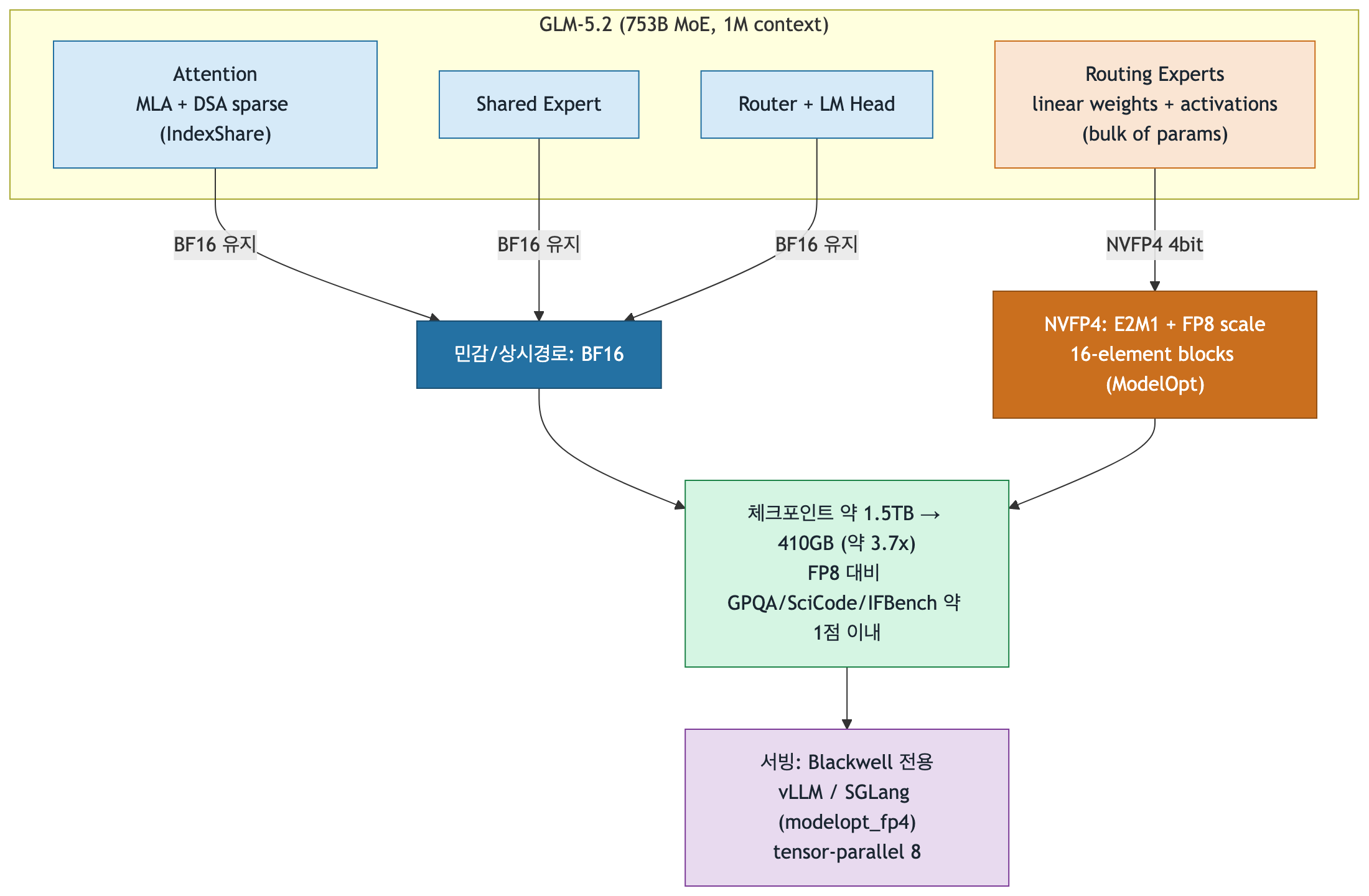 Only the linear operators inside MoE routing experts are quantized to NVFP4; shared experts and attention remain in BF16.
Only the linear operators inside MoE routing experts are quantized to NVFP4; shared experts and attention remain in BF16.
The most important design decision in this model is what was left unquantized. Quoting the model card directly: “only the weights and activations of linear operators inside transformer blocks within MoE experts are quantized; shared experts are not quantized.” Concretely:
- Quantized to NVFP4 (4-bit): weights and activations of linear operators in MoE routing experts. This section accounts for the vast majority of the 753B parameters, so nearly all of the memory savings come from here.
- Preserved in BF16 (16-bit): shared experts and the IndexShare sparse attention path. Every token passes through these on every forward pass, so their accuracy impact is disproportionately large.
This strategy makes sense given how parameters are distributed in MoE models. Routing experts are numerous and collectively hold the overwhelming share of parameters, but each token only activates a fraction of them. Shared experts and attention, by contrast, hold a smaller share of parameters but are used by every token without exception. Quantizing aggressively where there are many parameters used sparsely, and conservatively where there are few parameters used always, is a reasonable tradeoff that buys memory savings without paying much in accuracy. The near-flat accuracy numbers in the benchmark table are a direct consequence of this selective approach.
Quantization calibration used NVIDIA’s Nemotron-family datasets. The model card lists Nemotron-SFT-Instruction-Following-Chat-v2, Nemotron-Science-v1, Nemotron-Competitive-Programming-v1, Nemotron-SFT-Agentic-v2, Nemotron-Math-v2, Nemotron-SFT-SWE-v2, and Nemotron-SFT-Multilingual-v1. The mix covers reasoning, science, coding, agentic tasks, math, and multilingual data, aligned in character with the evaluation benchmarks.
Public benchmarks: accuracy vs. FP8
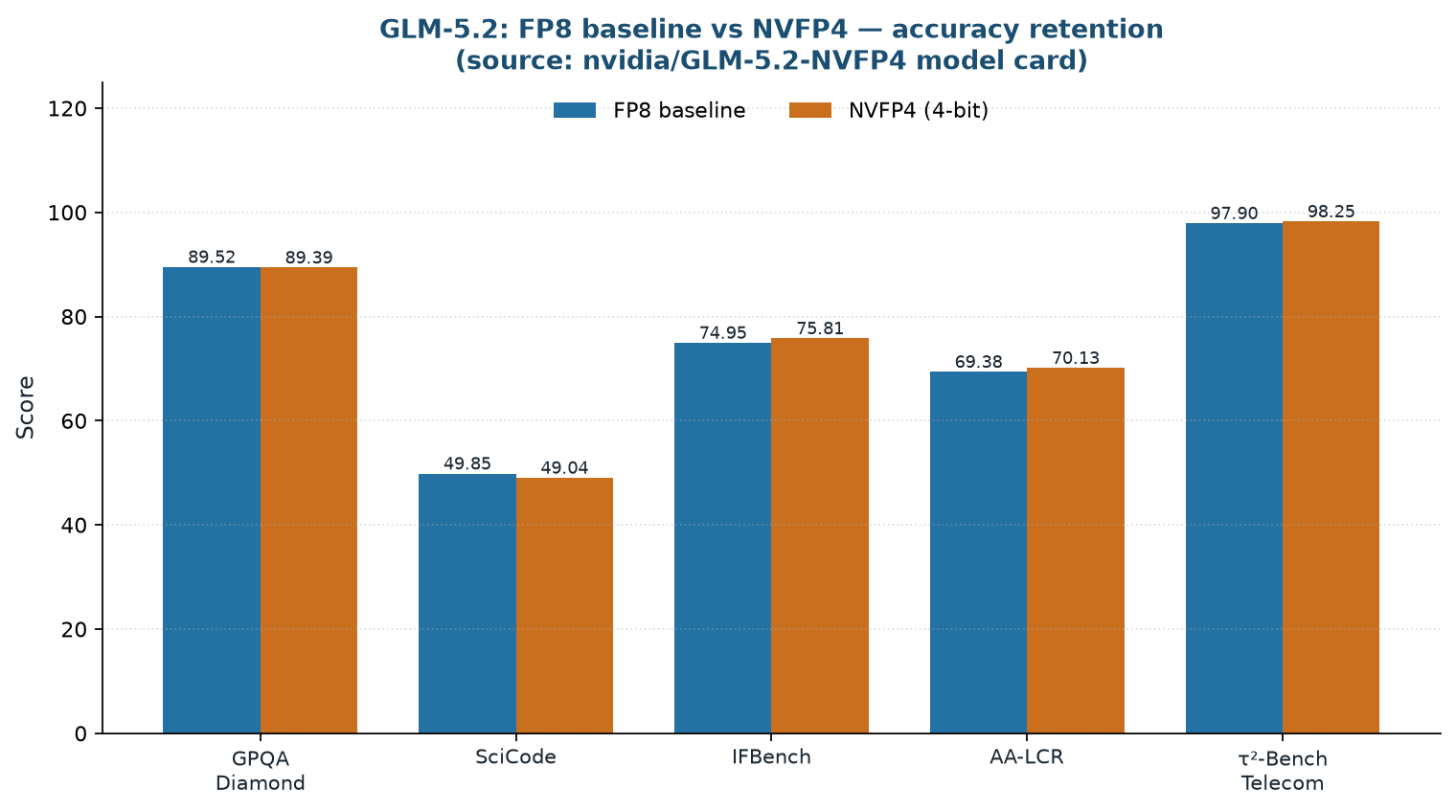 Official measurements from the nvidia/GLM-5.2-NVFP4 model card. The baseline is GLM-5.2-FP8.
Official measurements from the nvidia/GLM-5.2-NVFP4 model card. The baseline is GLM-5.2-FP8.
The accuracy comparison published in the model card is shown below. The baseline is not BF16 but the already-compressed GLM-5.2-FP8, making this a more demanding comparison: not “how much does 4-bit lose vs. the original” but “how much does 4-bit lose vs. 8-bit.”
| Benchmark | baseline (FP8) | NVFP4 |
|---|---|---|
| GPQA Diamond | 89.52 | 89.39 |
| SciCode | 49.85 | 49.04 |
| IFBench | 74.95 | 75.81 |
| AA-LCR | 69.38 | 70.13 |
| tau2-Bench Telecom | 97.9 | 98.25 |
Measurement conditions: temperature 1.0, top_p 0.95, max_new_tokens 100000 for GPQA Diamond, 64000 for the rest. AA-LCR was measured with SGLang; the remaining four with vLLM. The five benchmarks evaluate graduate-level scientific reasoning (GPQA Diamond, 448 questions), scientific coding (SciCode), instruction following (IFBench), long-context recall (AA-LCR), and agentic tool use (tau2-Bench Telecom).
GPQA drops by 0.13 and SciCode by 0.81, while IFBench (+0.86), AA-LCR (+0.75), and tau2-Bench Telecom (+0.35) actually come in higher for NVFP4. That a 4-bit model outperforms an 8-bit one on some tasks may seem counterintuitive, but differences at this scale are better interpreted as sampling variance noise than as quantization artifacts. The headline finding is: compressing FP8 a further step down to 4-bit leaves accuracy essentially flat, which is the direct payoff of the selective quantization strategy described above.
Deployment: vLLM and SGLang
This checkpoint officially supports SGLang and vLLM, and requires NVIDIA Blackwell hardware running Linux. NVFP4 tensor cores exist only in the Blackwell generation, so the 4-bit path cannot be used as-is on prior-generation GPUs. The SGLang serving command from the model card is:
pip install -U "transformers>=5.3.0" && \
python3 -m sglang.launch_server \
--model nvidia/GLM-5.2-NVFP4 \
--tensor-parallel-size 8 \
--quantization modelopt_fp4 \
--tool-call-parser glm47 \
--reasoning-parser glm45 \
--trust-remote-code \
--chunked-prefill-size 131072 \
--mem-fraction-static 0.80
Several signals are worth noting. --tensor-parallel-size 8 means the model assumes an 8-GPU node, not a single GPU. --quantization modelopt_fp4 tells the runtime to recognize the NVFP4 format produced by ModelOpt. --chunked-prefill-size 131072 splits the prefill phase when handling 1M-token contexts to prevent memory spikes, and is a stability-critical setting for long-context serving. --tool-call-parser glm47 and --reasoning-parser glm45 handle the GLM-family’s tool-call and reasoning-token formats, wiring directly into agentic workloads.
For a rough memory estimate: loading 753B at BF16 would require roughly 1.5 TB [estimated]. Because the routing experts hold most of the parameters and are quantized to 4-bit, actual weight memory drops to around one-third of that, putting it within range of a single 8-way tensor-parallel node (community NVFP4 mirror reports suggest roughly 1.37 TB to 459 GB, approximately a 3x reduction [estimated]). The model card does not publish exact GB figures before and after quantization, so these memory values carry the [estimated] label. What is unambiguous is that --tensor-parallel-size 8 signals: a single Blackwell 8-GPU node can serve this 753B reasoning model with a 1M-token context.
Implications for ThakiCloud’s Kubernetes AI/ML SaaS platform
ThakiCloud operates a multi-tenant platform that schedules GPUs with Kueue and serves models with vLLM on Kubernetes. In that environment, a pre-quantized frontier checkpoint like nvidia/GLM-5.2-NVFP4 is meaningful on three fronts.
First, the pool of self-hostable candidates grows. A 753B-scale reasoning model is normally ruled out of self-hosting consideration early, but if a 4-bit quantization brings weights and KV headroom within a single 8-GPU Blackwell node, on-premises serving becomes a realistic option. Using Kueue’s ResourceFlavor and ClusterQueue to carve out a dedicated Blackwell node pool for NVFP4 inference means the memory headroom gained through quantization translates directly into more concurrent tenants served. For customers who cannot send data to external APIs, particularly regulated sectors like government or finance where self-hosting and data sovereignty are requirements, providing frontier reasoning capability on-premises is itself a competitive differentiator.
Second, the quantization pipeline does not need to be run internally. Calibrating and quantizing a 753B model with ModelOpt is a substantial GPU-hours and engineering undertaking on its own. If a NVIDIA-validated checkpoint can be pulled and loaded directly into vLLM or SGLang, internal effort can shift from quantization validation to multi-tenant routing, autoscaling, and cost observability. That said, ThakiCloud’s skill system already has an internal workflow for quantizing Qwen3-MoE-family models to NVFP4, so the recipe NVIDIA used for GLM-5.2, “routing experts at 4-bit, shared experts and attention at BF16,” is now a general pattern we can apply when quantizing customer-domain models.
Third, selective quantization is worth encoding into our model intake criteria. The principle this model demonstrates, quantize aggressively where parameters are numerous and sparsely used, conservatively where they are few and always active, transfers directly to how we evaluate other MoE models. Rather than blanket 4-bit across the board, checking whether shared experts and attention are preserved can become a specific gate in the model intake review. That said, the Blackwell requirement is a hard constraint tied directly to our GPU pool composition. Any plan to use the NVFP4 path must explicitly list Blackwell node availability as a prerequisite in the adoption roadmap.
Limitations and counterpoints
The biggest limitation is hardware lock-in. The NVFP4 4-bit path requires Blackwell tensor cores, so environments with only prior-generation GPUs such as Hopper (H100/H200) cannot directly leverage this checkpoint’s advantages. The narrative of “cheap because it’s 4-bit” only holds if Blackwell nodes are already available or planned, and in many cases implies new capital expenditure.
Second, benchmark scope is narrow. The model card’s accuracy table covers five benchmarks, all oriented toward English-language reasoning, coding, and agentic tasks. Multilingual quality in real-world use (including Korean), and recall stability when the full 1M-token context is actually filled, cannot be assessed from the published table alone. Internal evaluation against domain-specific data, measuring regression relative to BF16 and FP8 baselines, is required before adoption.
Third, memory figures are uncertain. As noted above, the model card does not publish exact memory usage before and after quantization. The memory estimates in this post are back-calculated from parameter count and quantization scope. In production, adding KV cache and the 1M prefill buffer on top of weight memory means peak memory per node exceeds the weight-only estimate. Capacity planning must be based on peak memory, not weight memory alone.
Fourth, selective quantization is a tradeoff in both directions. Keeping shared experts and attention in BF16 preserves accuracy, but it also means memory savings are smaller than a full 4-bit approach. This model is “compress as far as accuracy allows,” not “compress as much as physically possible.” For extreme cost-constrained environments where loading onto a single workstation GPU is the goal, more aggressive options like 1-bit GGUF may be a better fit, at the cost of additional quality loss.
In summary, nvidia/GLM-5.2-NVFP4 is a concrete example of bringing a frontier 753B MoE reasoning model down to 4-bit without meaningful accuracy loss, making self-serving on a Blackwell 8-GPU node a viable choice. For ThakiCloud, it adds one more card to the hand for delivering frontier reasoning to customers with on-premises or data-sovereignty requirements, and it provides a general-purpose principle, selective quantization, that can be embedded directly into our model intake process. The door opens with a Blackwell key.