The Model That Thinks 220K Tokens: How GLM-5.2 Flips the Self-Hosting Math
When a model needs 220,000 tokens just to think through a Rubik’s cube, who pays for that? That is the question Matt Pocock (@mattpocockuk) surfaced while using his /teach skill and pi to have GLM-5.2 work through a cube solution. Even at the lowest effort setting (High), three turns produced roughly 220,000 tokens of thinking traces. A more capable reasoning model means a model that thinks longer, and a model that thinks longer means someone receives a larger invoice.
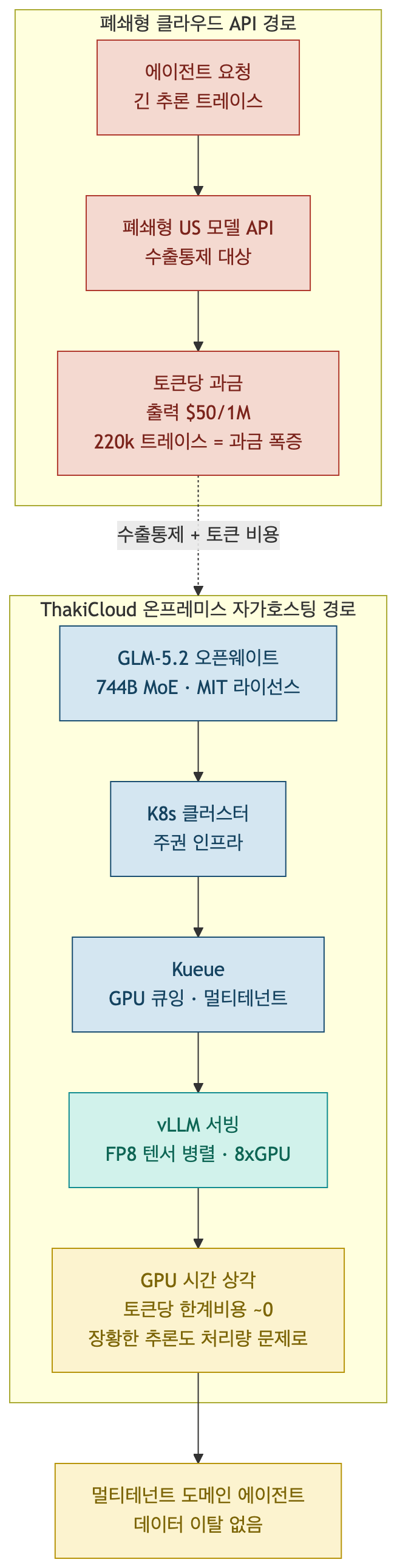
This is not an introduction to GLM-5.2 as a model. The story of compressing its weights to 1-bit for smaller hardware is covered in a separate post. What this post examines is one level up: when a verbose open-weight reasoning model arrives, how do the cost structures of per-token cloud APIs and GPU-time-amortizing on-premises hosting diverge? The short answer is that there is a clear crossover point where longer reasoning favors self-hosting, and that crossover is exactly what ThakiCloud’s K8s-based multi-tenant platform is designed to exploit.
All figures in this post come from measurements published by Z.ai and various outlets, or from arithmetic derived from publicly stated parameter counts. The 744B model cannot be run directly in this analysis environment, so published benchmarks are cited rather than original measurements. Estimates derived from arithmetic are marked [est.] throughout.
Overview
GLM-5.2 is an open-weight large language model released on June 13, 2026 by Z.ai (formerly Zhipu AI, a Beijing company spun out of Tsinghua University’s Knowledge Engineering Group in 2019). It uses a Mixture-of-Experts (MoE) architecture with roughly 744B total parameters, activating approximately 40B per token. The model supports up to one million tokens of context and up to 128,000 tokens of output. Weights are released under the MIT license, meaning anyone can download and run it commercially on their own infrastructure.
The timing is significant. Multiple outlets reported that GLM-5.2 went public two days after the United States ordered Anthropic to block overseas access to the Fable 5 and Mythos 5 models. A closed frontier model being cut off by export controls and a strong open model arriving under an MIT license happened in the same week. For organizations thinking about data sovereignty and model sovereignty together, that contrast is not an abstract policy question but an immediate architectural choice.
The performance reviews are also favorable. Independent benchmarks cited by The Decoder and others, along with Z.ai’s technical card, show GLM-5.2 closing to within a single point of the closed frontier leaders on long-horizon coding tasks.
| Benchmark | GLM-5.2 | Claude Opus 4.8 | GPT-5.5 | GLM-5.1 |
|---|---|---|---|---|
| SWE-bench Pro (coding) | 62.1 | 69.2 | 58.6 | 58.4 |
| Terminal-Bench 2.1 (agent) | 81.0 | ~84 | n/a | 63.5 |
| FrontierSWE (long-horizon coding) | 74.4% | 75.4% | ~73% | n/a |
| AIME 2026 (math) | 99.2% | - | - | - |
On SWE-bench Pro, a score of 62.1 beats GPT-5.5 (58.6) and the previous generation GLM-5.1 (58.4). Terminal-Bench 2.1 jumps from GLM-5.1’s 63.5 to 81.0. Every category places it at the top of the open-model field. Note that FrontierSWE figures vary between 73% and 75% depending on the source.
How GLM-5.2 Tries to Use Fewer Tokens
One interesting aspect of the GLM-5.2 design is that it directly addresses the problem of processing long contexts and large token volumes at lower cost. Every model claiming a one-million-token context window hits the same engineering wall: as context grows, the bottleneck shifts from raw computation to KV cache capacity and kernel overhead. Z.ai tackles this with two structural choices.
The first is IndexShare. In standard DeepSeek Sparse Attention (DSA), every transformer layer runs its own indexer to select which tokens to attend to. At scale, this is expensive. IndexShare runs the indexer only on the first layer of every four-layer group, and the next three layers reuse the top-k indices from that first layer. The result is a 75% reduction in inner indexing cost for those layers, and a 2.9x reduction in per-token FLOPs at one-million-token lengths. The second mechanism combines KVShare with Multi-Token Prediction (MTP), predicting multiple tokens in a single forward pass to increase decoding throughput.
The lever that users interact with directly is the effort setting. GLM-5.2 offers two levels, High and Max, and Z.ai recommends Max for coding tasks. New sessions default to High. Published measurements show that Max effort draws up to about 85,000 output tokens per task to reach peak intelligence, while High effort sacrifices a few benchmark points in exchange for roughly half the output token volume. In other words, token consumption is not set automatically inside the model: it is a knob that operators can explicitly adjust. That knob is the central variable in the cost analysis that follows.
What /teach Revealed: Reasoning Consumes Tokens
Back to Matt Pocock’s observation. At the lowest effort setting, a single Rubik’s cube problem across three turns produced roughly 220,000 tokens. Turning the effort knob to Max would have produced more. This is not a defect; it is the nature of reasoning models. The more a model “thinks” before reaching an answer, the higher the quality, and all of that thinking is billed as output tokens.
The question is where those tokens get settled. The same 220,000-token trace carries a very different unit cost depending on the billing structure. Z.ai’s API output price is $4.40 per million tokens (input: $1.40/M, cached input: $0.26/M). Closed US frontier models run around $50 per million output tokens. Translating those rates by effort level and task length makes the gap concrete.
| Output trace per task | GLM-5.2 API ($4.40/1M) | Closed model ($50/1M) |
|---|---|---|
| ~8.5k (short task) | $0.037 | $0.425 |
| ~42k (High effort [est.]) | $0.185 | $2.10 |
| 85k (Max effort) | $0.374 | $4.25 |
| 220k (/teach observation) | $0.968 | $11.00 |
The most obvious takeaway is that the open-weight model on API is already about one-sixth the cost. But the deeper point is different. Both options still charge per token. As reasoning traces grow longer, the invoice scales linearly. A workload that calls an agent hundreds of thousands of times per day and burns 220,000 tokens per call will be dominated by token volume regardless of how low the unit price is. That is precisely where self-hosting draws a different curve.
Serving Cost Model: How Self-Hosting Flips the Math
In self-hosting, the cost structure is time-based rather than token-based. From the moment a GPU node is provisioned, costs are nearly fixed whether zero tokens or billions flow through it. Long reasoning traces therefore stop being a “token billing” problem and become a “throughput and latency” problem. The engineering question becomes how many reasoning jobs can be packed into the same GPU time.
There is a genuine barrier to entry. The 744B weights have to live somewhere. Memory footprint derived from the published parameter count is as follows (KV cache excluded, pure arithmetic [est.]):
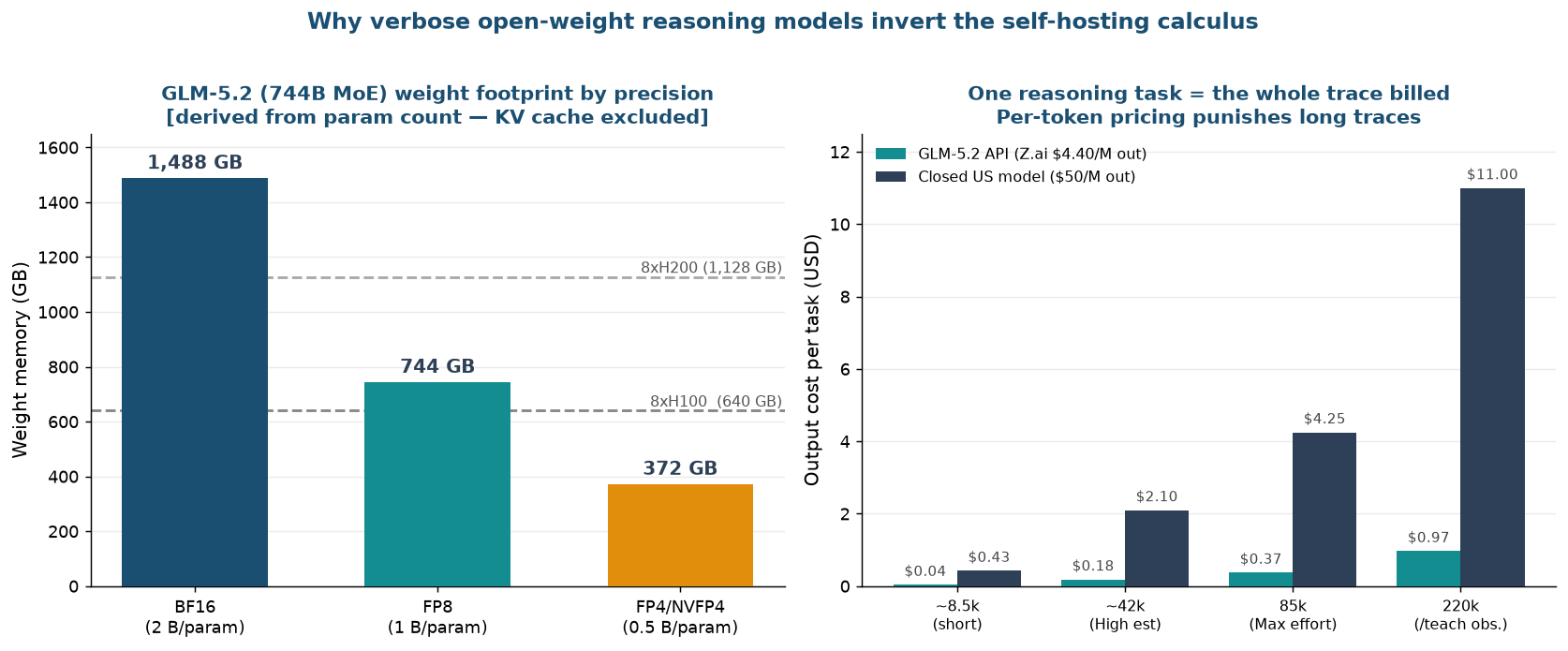
BF16 requires roughly 1,488 GB; FP8 roughly 744 GB; FP4/NVFP4 roughly 372 GB. Eight H100s at 80 GB each give 640 GB total; eight H200s at 141 GB each give 1,128 GB. FP8-quantized weights fit comfortably in a single H200 node and are tight on an H100 node once KV cache headroom is considered. Dropping to FP4 leaves room on a single H100 node. Running a frontier-class reasoning model on a single GPU node is no longer impractical.
That is where the math flips. Provision a node, serve with vLLM, and amortize GPU time. The marginal cost of a workload with 220,000-token traces is no longer per-token but “how fully is this node utilized.” The more verbose the reasoning and the higher the call frequency, the larger the denominator in the fixed-cost amortization, and the lower the effective per-token cost drops. The regime that is worst for per-token APIs (long traces at high frequency) is the same regime that favors self-hosting most. With the effort knob in the operator’s hands, lower-stakes workloads can run at High to halve token volume, while critical workloads run at Max, enabling fine-grained cost and quality control that is simply not available on a hosted API.
Implications for ThakiCloud’s K8s AI/ML SaaS Platform
ThakiCloud operates a K8s-based multi-tenant AI/ML SaaS platform with a focus on on-premises and VPC serving that keeps customer data within their boundaries. A strong open-weight reasoning model like GLM-5.2 aligns precisely with that value proposition.
First, this is a sovereignty question, not an export-control workaround. With overseas access to closed US models becoming subject to policy restrictions, serving MIT-licensed weights directly inside a customer cluster provides model sovereignty that is insulated from external policy changes. Neither the data nor the model crosses tenant boundaries.
Second, Kueue-based GPU queuing connects directly to token economics. ThakiCloud queues and prioritizes multi-tenant GPU workloads via Kueue. Because verbose reasoning traces occupy nodes longer, linking effort levels to queue priorities lets the platform optimize both cost efficiency and latency targets within the same GPU pool. High-priority tenant tasks run at Max effort in the priority queue; batch workloads run at High effort to increase throughput.
Third, the model fits naturally into the vLLM serving stack. GLM-5.2 provides an Anthropic-compatible endpoint (https://api.z.ai/api/coding/paas/v4) so Claude Code, OpenClaw, and Cline attach immediately, but the more important point is that the weights can be downloaded and served with vLLM’s FP8 tensor parallelism. This reuses exactly the pattern already applied to other open models on the platform.
For mature deployments, domain-specific agents running on an open reasoning model of GLM-5.2’s caliber can be self-hosted to deliver both low serving cost and zero data egress. Controlling inference costs through GPU amortization rather than a per-token invoice is a clear differentiator for enterprise customers who care about both cost and compliance.
Limitations and Counterarguments
There are weaknesses in this analysis worth stating plainly.
Self-hosting is not always cheaper. The crossover point exists specifically in the “long traces at high frequency” regime, not for infrequent small-scale workloads. When call volume is low, the fixed cost of a GPU node has a small denominator, and a per-token API is actually cheaper. Keeping an eight-GPU node idle is among the most expensive things an operator can do. The break-even point depends entirely on the workload profile.
The memory figures above are pure parameter arithmetic and exclude KV cache. Filling a one-million-token context in practice adds tens to hundreds of gigabytes of KV cache, which can quickly eliminate the headroom on a single node. Actual achievable concurrency cannot be determined from published numbers alone, and the 744B model was not run directly in this environment. Throughput and concurrency figures require empirical measurement.
Benchmark scores also need context. FrontierSWE figures are cited anywhere from 73% to 75% depending on the source, and benchmark rankings do not guarantee superiority on any specific domain task. The effort-level token volumes (8.5k, 85k, and so on) are highly task-dependent, so the absolute values in the cost table are less important than the directional insight: the longer the reasoning, the more disadvantageous per-token billing becomes.
The core argument holds regardless. In an era where powerful open-weight reasoning models burn large numbers of tokens, the lever for cost control is shifting from negotiating unit prices to choosing billing structures. Per-token or per-time, and whether the organization has the infrastructure to make that choice, is where the fork in the road lies.
Sources
- Original tweet (summary source): @hjguyhan, 2026-06-22
- GLM-5.2 analysis: felloai: GLM 5.2: Zhipu’s 1M-Context Open-Source Model Explained
- GLM-5.2 benchmarks and pricing: labellerr: GLM-5.2 Just Beat GPT-5.5 at a Sixth of the Cost
- Official weights: GitHub: zai-org/GLM-5
- Related post (quantization): Unsloth GLM-5.2 1-bit Dynamic GGUF On-Premises Analysis