첫 AI 에이전트를 만든다면 - 가드레일이 붙은 최소 루프부터
“첫 AI 에이전트를 만드는 법”이라는 제목의 입문 가이드가 꾸준히 화제가 됩니다. 좋은 가이드는 대체로 에이전트를 네 조각으로 나눕니다. 추론을 담당하는 LLM 두뇌, 상태를 기억하는 메모리, 외부와 상호작용하는 도구, 그리고 이 셋을 묶어 반복하는 에이전트 루프입니다. 여기에 ReAct 패턴, 즉 추론과 행동을 번갈아 수행하는 구조가 표준처럼 따라옵니다. 다 맞는 설명입니다. 그런데 실제로 에이전트를 운영해 보면 무너지는 지점은 따로 있습니다. 바로 루프를 언제 멈출지 정하는 가드레일입니다. 이 글은 외부 LLM을 전혀 호출하지 않고 순수 파이썬으로 가드레일이 붙은 최소 에이전트 루프를 직접 돌려, 그 차이를 실제 수치로 보여 줍니다.
개요
에이전트 루프는 본질적으로 while 문입니다. 관찰하고, 다음 행동을 결정하고, 도구를 실행하고, 그 결과를 다시 관찰하는 반복입니다. 입문 자료가 보여 주는 행복한 경로에서는 이 루프가 몇 번 돌다가 답을 내고 끝납니다. 문제는 행복하지 않은 경로입니다. 모델이 같은 도구를 무한히 다시 부르거나, 끝나지 않는 작업에 매달리거나, 한 요청이 GPU를 붙잡고 놓지 않는 상황이 실제 운영에서는 흔합니다. 가드레일은 이 폭주를 코드 수준에서 차단하는 장치입니다.
ThakiCloud는 멀티테넌트 환경에서 여러 고객의 에이전트와 배치 작업을 같은 GPU 풀 위에서 돌립니다. 이런 환경에서 가드레일은 선택이 아니라 전제입니다. 한 테넌트의 폭주하는 루프가 전체 풀을 마비시키면 안 되기 때문입니다. 그래서 “에이전트를 어떻게 만드는가”보다 “에이전트 루프를 어떻게 멈추는가”가 운영 관점에서 더 중요합니다. 이 글에서는 그 멈춤 장치를 가장 작은 형태로 구현해 직접 실행한 결과를 공유합니다.
이 기술은 무엇인가
ReAct 루프의 골격은 단순합니다. 정책(policy)이 현재 상태를 보고 다음에 무엇을 할지 결정합니다. 도구를 부르라고 하면 도구를 실행해 관찰값을 얻고, 끝내라고 하면 답을 반환합니다. 진짜 에이전트에서는 이 정책이 LLM이지만, 루프의 제어 구조 자체는 모델과 무관합니다. 그래서 이번 실험에서는 정책을 규칙 기반 스텁으로 대체했습니다. 모델 품질이 아니라 루프의 제어 평면을 관찰하기 위해서이고, 덕분에 결과가 완전히 재현 가능합니다.
가드레일은 이 루프에 세 가지 멈춤 조건을 추가합니다. 단계 상한(max_steps)은 루프가 정해진 횟수를 넘기면 강제로 중단합니다. 시간 예산(wall_budget)은 작업당 벽시계 시간을 제한합니다. 반복 탐지(repeat_guard)는 같은 행동이 반복되면 루프 함정으로 판단해 끊습니다. 모든 작업은 정확히 하나의 종료 사유로 끝납니다. 정상 종료(finished), 단계 초과(max_steps), 시간 초과(wall_budget), 반복 차단(repeat_guard), 행동 없음(no_action) 중 하나입니다.
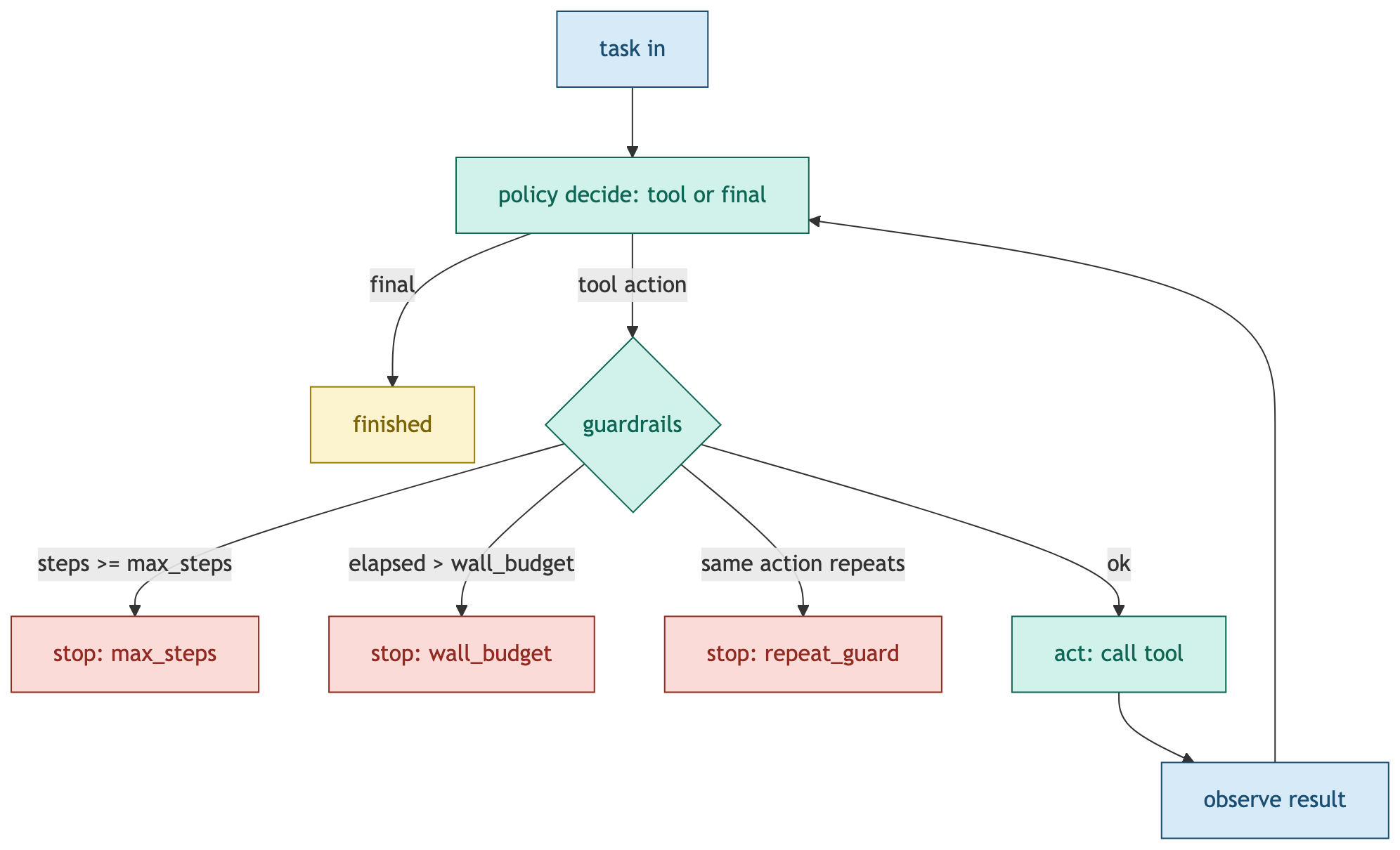
이 그림의 핵심은 도구를 실행하기 전에 반드시 가드레일 검사를 거친다는 점입니다. 가드레일을 루프 바깥에 두거나 사후에 검사하면 이미 폭주가 시작된 뒤입니다. 매 반복마다 행동 직전에 검사해야 멈춤이 보장됩니다.
설치 및 통합
이 실험은 외부 의존성이 전혀 없습니다. 파이썬 표준 라이브러리만 사용하므로 추가 설치 없이 그대로 실행됩니다. 정책은 작업 문자열을 정규식으로 보고 도구를 고르고, 도구는 안전하게 제한된 산술 계산기와 작은 지식 조회 두 가지입니다.
@dataclass
class Guards:
max_steps: int = 6
wall_budget_s: float = 2.0
repeat_limit: int = 2
def run_task(task: str, g: Guards) -> Trace:
t0 = time.perf_counter()
tr = Trace(task=task)
repeats: dict[str, int] = {}
while True:
if tr.steps >= g.max_steps:
tr.terminal = "max_steps"; break
if (time.perf_counter() - t0) > g.wall_budget_s:
tr.terminal = "wall_budget"; break
act = policy(task, tr.scratch)
if "final" in act:
tr.answer = act["final"]
tr.terminal = "finished" if act["final"] is not None else "no_action"
break
sig = f"{act['tool']}:{act['input']}"
repeats[sig] = repeats.get(sig, 0) + 1
if repeats[sig] > g.repeat_limit:
tr.terminal = "repeat_guard"; break
obs = TOOLS[act["tool"]](act["input"])
tr.scratch.append({"tool": act["tool"], "input": act["input"], "obs": obs})
tr.steps += 1
tr.latency_ms = round((time.perf_counter() - t0) * 1000, 3)
return tr
루프 구조를 보면 가드레일이 모두 행동 직전에 배치돼 있습니다. 단계 상한과 시간 예산은 루프 진입부에서, 반복 탐지는 도구 호출 직전에 검사합니다. 정책이 끝내라고 하면 그대로 종료하고, 그 외에는 가드레일을 통과한 행동만 실행합니다. 실행은 다음 한 줄입니다.
.venv/bin/python scripts/experiments/minimal-guarded-agent-loop/agent_loop.py
작업 집합에는 정상적으로 끝나는 작업 네 개와, 의도적으로 같은 조회를 반복하게 만든 루프 함정 작업 하나를 넣었습니다. 이 함정 작업이 반복 탐지에 걸리는지가 이번 실험의 핵심 확인 사항입니다.
실제 실험 결과
다섯 개 작업을 실행한 실제 결과는 다음과 같습니다. 가드레일은 단계 상한 6, 시간 예산 2.0초, 반복 한도 2로 설정했습니다.
{
"n_tasks": 5,
"by_terminal": { "finished": 4, "repeat_guard": 1 },
"total_latency_ms": 0.115,
"total_steps": 7
}
핵심은 종료 사유 분포입니다. 정상 종료가 네 건, 반복 차단이 한 건입니다. 의도적으로 심은 “loop forever please” 작업은 같은 조회를 계속 시도하다가 정확히 2단계에서 반복 탐지에 걸려 멈췄습니다. 같은 행동이 한도를 넘는 순간 루프가 끊긴 것입니다. 가드레일이 없었다면 이 작업은 정책이 영원히 같은 행동을 고집하며 끝나지 않았을 것입니다.
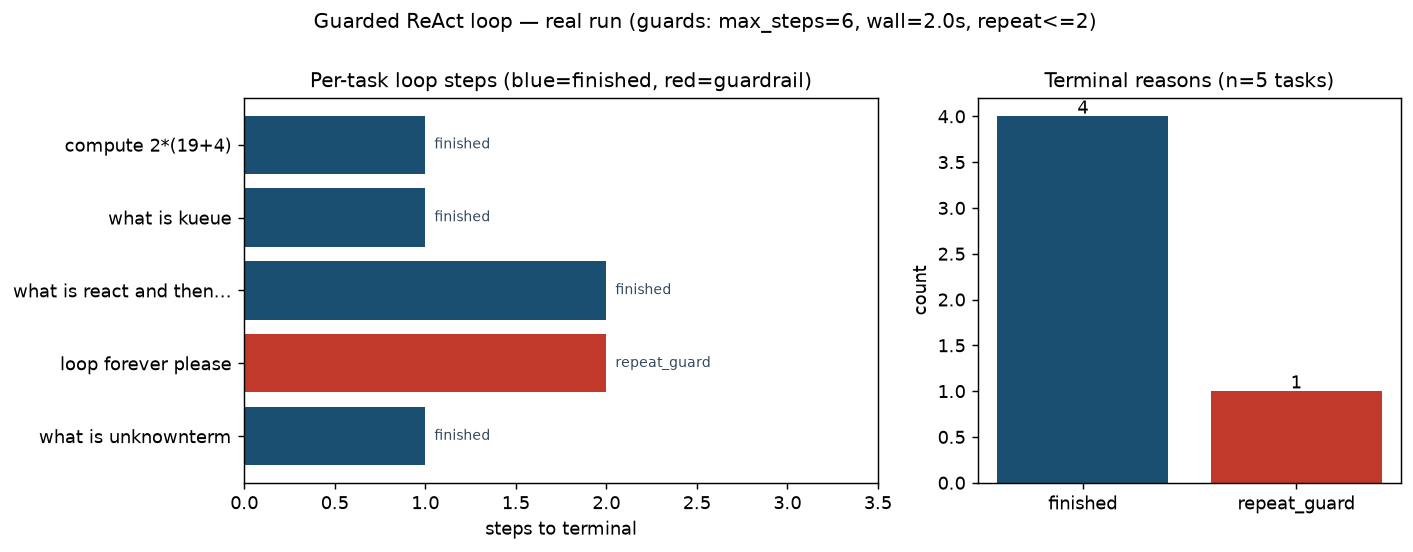
왼쪽 막대는 작업별로 종료까지 걸린 단계 수입니다. 정상 작업은 1단계 또는 2단계 만에 끝났고, 계산과 조회를 모두 요구한 작업만 2단계가 필요했습니다. 오른쪽은 종료 사유 분포로, 다섯 작업 중 하나가 가드레일에 의해 멈췄음을 보여 줍니다. 전체 처리 시간은 0.115밀리초로, LLM 호출이 없기 때문에 루프 제어 자체의 비용은 사실상 0에 가깝습니다. 이는 중요한 사실을 말해 줍니다. 가드레일을 추가하는 비용은 무시할 수 있는 수준이고, 빠지는 비용은 폭주하는 루프 전체라는 점입니다.
이 수치는 모델 성능을 측정한 것이 아닙니다. 정책을 규칙으로 고정했으므로 측정 대상은 제어 평면입니다. 그러나 실제 LLM을 끼우더라도 가드레일의 동작은 정확히 동일합니다. 모델이 무엇을 출력하든 단계 상한, 시간 예산, 반복 탐지는 모델 바깥의 코드가 강제하기 때문입니다. 멈춤을 모델의 선의에 맡기지 않고 코드가 소유한다는 것이 이 구조의 본질입니다.
ThakiCloud K8s AI/ML SaaS 플랫폼 적용 및 시사점
이 최소 루프는 장난감처럼 보이지만, 담고 있는 원칙은 프로덕션 에이전트 운영의 핵심과 같습니다. 멈춤은 모델이 아니라 인프라가 책임진다는 원칙입니다. ThakiCloud의 운영 스택에서 이 원칙은 두 층위로 나타납니다.
애플리케이션 층위에서는 방금 본 루프 내부 가드레일이 작동합니다. 단계 상한과 반복 탐지는 에이전트 코드 안에서 한 요청의 폭주를 막습니다. 그 위 인프라 층위에서는 Kueue가 같은 역할을 자원 차원에서 수행합니다. 에이전트 작업이 GPU를 요구하면 Kueue가 큐에 담아 자원이 빌 때 스케줄링하고, 테넌트별 할당량을 넘는 작업은 대기시키거나 선점합니다. 즉 한 테넌트의 에이전트가 아무리 많은 작업을 던져도, 시간 예산은 코드가 막고 자원 한도는 Kueue가 막습니다. 두 가드레일이 서로 다른 층에서 같은 폭주를 이중으로 차단하는 구조입니다.
감사 가능성도 자연스럽게 따라옵니다. 이번 실험에서 모든 작업은 종료 사유를 명시적으로 남겼습니다. 정상 종료인지, 반복 차단인지, 시간 초과인지가 구조적으로 기록됩니다. 이 패턴을 프로덕션으로 확장하면 에이전트의 모든 행동과 종료 사유가 로그로 남고, 누가 무엇을 언제 왜 멈췄는지가 추적됩니다. 온프레미스와 주권형 배포를 전제로 하는 환경에서 이 추적성은 공공 부문이나 규제 산업 고객에게 도입의 전제 조건입니다. 에이전트가 무엇을 했는지 설명할 수 없는 시스템은 그 자체로 배포 불가이기 때문입니다.
정리하면 첫 에이전트를 만들 때 배워야 할 가장 중요한 것은 도구를 어떻게 연결하느냐가 아니라 루프를 어떻게 멈추느냐입니다. 가드레일은 나중에 붙이는 안전장치가 아니라 처음부터 루프의 일부여야 합니다. 그리고 그 가드레일을 애플리케이션과 인프라 양쪽에 두는 것이, 멀티테넌트 GPU 플랫폼에서 에이전트를 안전하게 운영하는 방법입니다.
한계 및 반론
이 실험에는 분명한 한계가 있습니다. 첫째, 정책을 규칙으로 고정했으므로 실제 LLM이 만드는 예측 불가능성은 측정하지 못했습니다. 진짜 모델은 의도와 다른 도구를 부르거나, 잘못된 입력을 만들거나, 환각으로 끝없는 추론을 이어갈 수 있습니다. 이번 결과는 그런 경우에도 가드레일이 멈춤을 보장한다는 점을 보여 줄 뿐, 모델이 똑똑해진다는 보장은 아닙니다.
둘째, 가드레일은 폭주를 막지만 품질을 만들지는 않습니다. 단계 상한에 걸려 멈춘 작업은 안전하게 끝났을 뿐 답을 내지 못한 실패입니다. 가드레일을 너무 빡빡하게 잡으면 정상적인 긴 작업까지 잘려 나가고, 너무 느슨하게 잡으면 폭주를 충분히 빨리 막지 못합니다. 적절한 임계값은 작업 특성에 따라 조정해야 하고, 이는 한 번에 정해지지 않는 운영 과제입니다.
셋째, 실제 시스템에서는 가드레일 종류가 더 많아야 합니다. 토큰 예산, 비용 상한, 도구별 호출 횟수 제한, 외부 호출 타임아웃 같은 추가 장치가 필요합니다. 이번 최소 구현은 세 가지만 다뤘지만, 원칙은 동일하게 확장됩니다. 멈춤 조건을 모델 바깥의 코드가 소유하고, 매 반복마다 행동 직전에 검사한다는 원칙입니다. 입문 가이드가 보여 주는 네 조각에 이 다섯 번째 조각, 가드레일을 더하는 것이 첫 에이전트를 장난감에서 운영 가능한 시스템으로 끌어올리는 차이입니다.
출처
- 입문 가이드 원문(스레드): How to build your first AI agent by @eng_khairallah1
- 에이전트 실행 루프 개념: The Agent Execution Loop (Victor Dibia)
- ReAct와 LLM 에이전트 개요: Prompt Engineering Guide - LLM Agents
- 실험 코드:
scripts/experiments/minimal-guarded-agent-loop/agent_loop.py(본 저장소)