DiffusionGemma 26B-A4B: Google’s Experiment Generating 15-20 Tokens at Once with Discrete Text Diffusion
⏱️ Estimated reading time: 9 min
What Is New
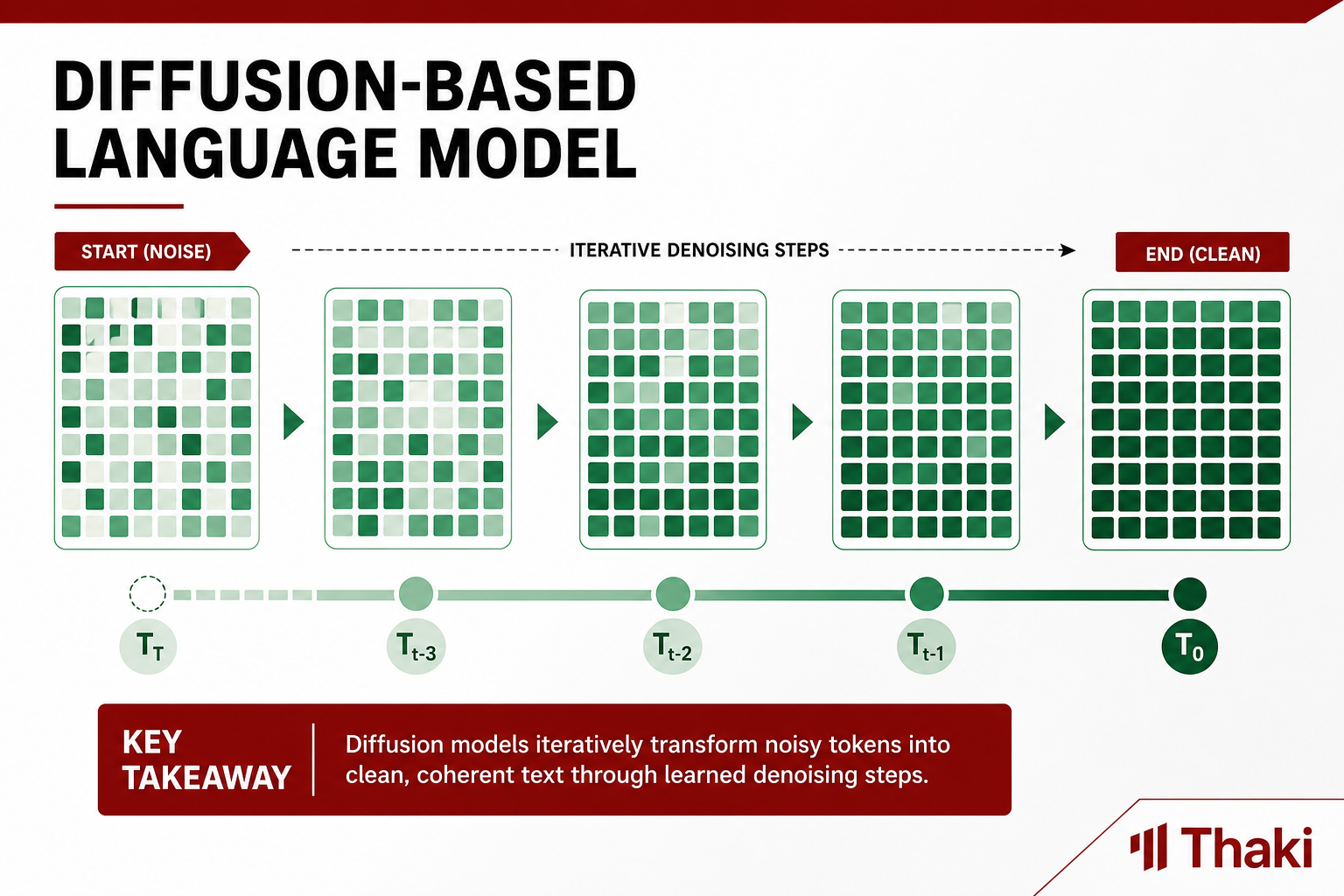
Google DeepMind released google/diffusiongemma-26B-A4B-it. The name signals a Gemma-based architecture, but the text generation mechanism is fundamentally different. Conventional language models predict tokens one at a time from left to right, the autoregressive approach. DiffusionGemma instead uses discrete text diffusion: it iteratively refines a noise-mixed sequence until it arrives at the final text.
In terms of actual generation speed, the model generates 15 to 20 tokens simultaneously in a single forward pass. The model card states that it exceeds 1,100 tokens/sec on H100 FP8 at low batch sizes. This figure is from Google’s own measurement and will vary with hardware configuration and batch size.
The license is Apache-2.0, a standard open-source license that permits commercial use and derivative model distribution.
Architecture
Parameter breakdown:
- Total parameters: 25.2B
- Active parameters: 3.8B
- Layers: 30
- Experts: 128 total, 8 active + 1 shared
- Vocabulary size: 262,144
- Vision encoder: approximately 550M parameters
- Sliding window: 1,024 tokens
- Canvas length: 256
- Context: up to 256K tokens
Structurally it is an encoder-decoder with bidirectional attention. Unlike the unidirectional attention of a standard causal language model, the full sequence is visible at once. Combined with discrete diffusion, this is what enables multiple tokens to be generated in a single pass.
The model accepts images and video as input in addition to text. Variable resolutions and aspect ratios are supported for images.
The model was trained on more than 140 languages and explicitly supports 35 or more. The training data cutoff is January 2025.
Benchmarks
Figures from the model card are for the instruction-tuned version using the Entropy Bound sampler.
| Benchmark | Score |
|---|---|
| MMLU Pro | 77.6% |
| AIME 2026 (no tools) | 69.1% |
| LiveCodeBench v6 | 69.1% |
| GPQA Diamond | 73.2% |
| BigBench Extra Hard | 47.6% |
| MMMU Pro (vision) | 54.3% |
| MATH-Vision | 70.5% |
AIME 2026 at 69.1% and GPQA Diamond at 73.2% represent a meaningful level for mathematical reasoning and scientific problem solving. Given 3.8B active parameters, these numbers are worth noting, though benchmarks are always snapshots under specific conditions.
K8s Deployment Considerations for Diffusion-Based Generation
The non-autoregressive generation mechanism has implications for serving infrastructure.
KV cache patterns differ. An autoregressive model caches KV state for generated tokens sequentially to predict the next token. Discrete diffusion iteratively refines the full sequence, so the standard KV cache mechanism may not apply directly. Whether vLLM or SGLang’s PagedAttention optimization works as intended needs verification through actual testing.
Batch processing characteristics differ. In autoregressive models, varying sequence lengths within a batch are handled through padding or continuous batching. For diffusion models, processing time depends on the combination of diffusion steps and canvas length. Per-request latency variance may show a different pattern compared to standard AR models.
Inference memory. At BF16, the full 25.2B parameters require approximately 50.4GB VRAM. Including the 550M vision encoder, it fits on a single A100 80GB or H100 80GB. Because the active-parameter design is 3.8B, throughput economics are more favorable than a dense 25B model.
Officially supported frameworks are Transformers, vLLM, SGLang, and Docker Model Runner. Twenty-six quantized variants are available.
# vLLM serving example
vllm serve google/diffusiongemma-26B-A4B-it \
--dtype bfloat16 \
--max-model-len 32768
Given the discrete diffusion architecture, verify vLLM version compatibility first. Some features optimized for standard AR models may not function correctly.
Thinking mode is configurable, and system prompts plus function calling are natively supported.
ThakiCloud Perspective
Experimental environment for diffusion LLM inference paradigm. DiffusionGemma is better suited for researching and experimenting with inference paradigms than for production workloads at this stage. On the ThakiCloud platform, a dedicated experimental Kueue WorkloadClass can be created to measure actual diffusion model throughput and quality side by side with autoregressive models. Gathering data on where discrete diffusion diverges from AR for specific task types is the right first step.
256K context and multimodal inputs. The 256K context window and image/video input support are useful for long-document comprehension and large codebase analysis tasks. The Apache-2.0 license places no restrictions on commercial use or derivative model development, which is an advantage when integrating on-premises.
The diffusion LLM ecosystem is not yet as mature as the autoregressive model ecosystem. Direct verification of serving framework support status for diffusion models, quantization effectiveness, and real-world deployment stability is still required.