FastContext-1.0-4B-SFT: A 4B Subagent Model Dedicated to Repository Exploration for Coding Agents
⏱️ Estimated reading time: 7 min
What Is New
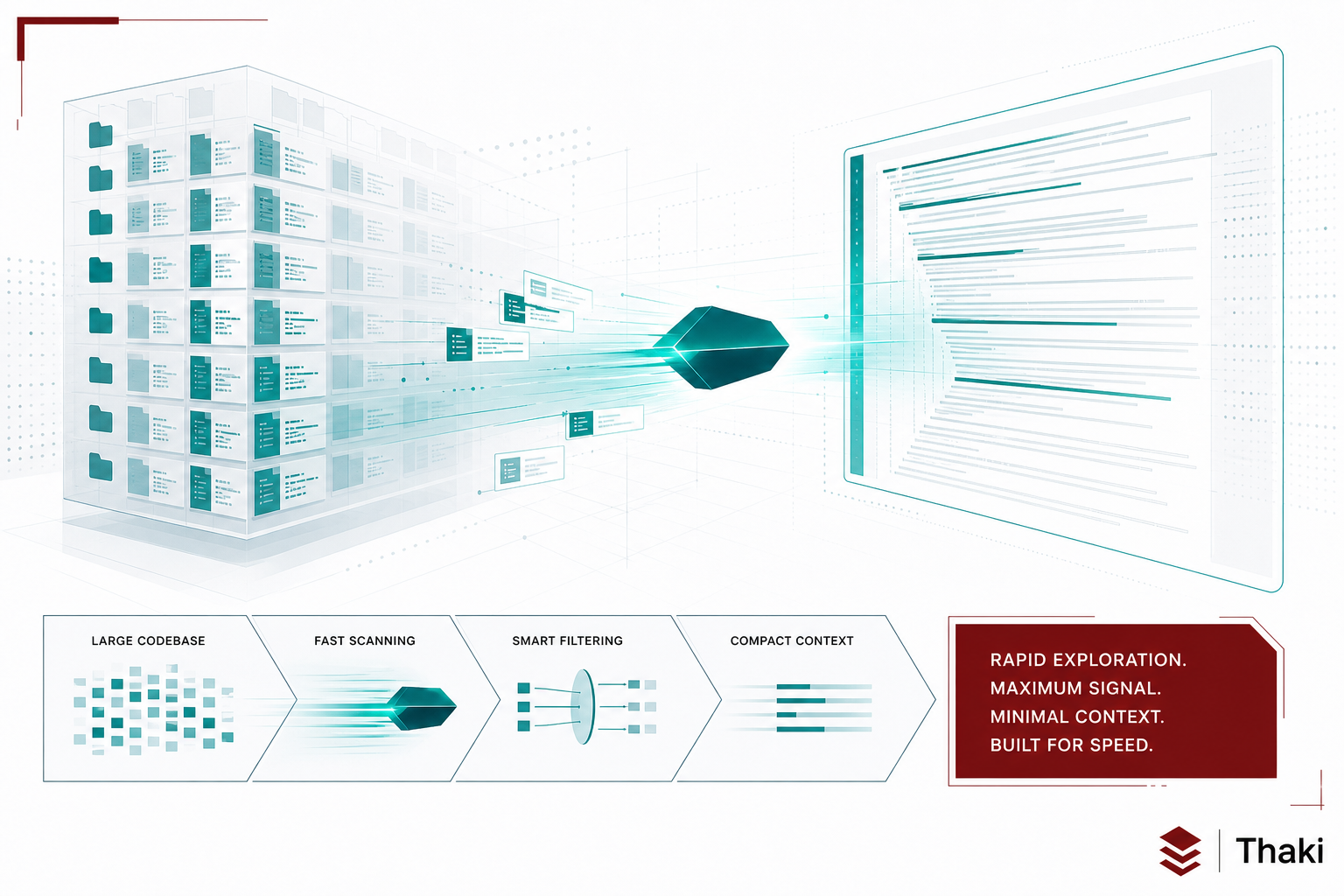
Microsoft released microsoft/FastContext-1.0-4B-SFT. The accompanying paper is arXiv:2606.14066, “FastContext: Training Efficient Repository Explorer for Coding Agents.” This model has one job: when a coding agent receives a task, FastContext acts as the subagent that scans the entire repository to locate relevant files and code fragments.
The design is intentionally narrow. Only three tools are used: READ, GLOB, and GREP. Read a file, find paths, search text. No write operations. While the main agent writes code and makes decisions, FastContext handles only the retrieval of context that the main agent needs.
Why is a dedicated model necessary? In coding agent benchmarks such as SWE-bench, repository exploration consumes a significant share of total token usage. When a large main model such as GPT-5.4 or GLM-5.1 performs the exploration directly, it is expensive and slow. Delegating exploration to a 4B model reduces cost while improving overall pipeline accuracy.
Architecture
The base model is Qwen/Qwen3-4B-Instruct-2507. Parameter count is 4B and context length is 262K tokens. dtype is BF16.
Training combined SFT (Supervised Fine-Tuning) with RL (GRPO-based). The training data draws from three sources as described in the paper and model card:
parallel_toolcalls: patterns that broadly scan multiple files in parallel on the first turnmultiturn_traj: patterns that gather evidence across multiple turnslinerange: patterns that cite precise line ranges
These three sources reflect actual agent runtime behavior, encoding the principle that exploration strategy should adapt to context.
The model family includes FC-4B-SFT (this model), FC-4B-RL, and FC-30B-SFT. FC-30B-SFT is based on Qwen3-Coder-30B-A3B.
Benchmarks
Figures from the model card and paper measure changes when FastContext is attached as a subagent to a main agent. The comparison baseline is operation without any exploration (w/o Explore).
| Main agent | Benchmark | Accuracy change | Token change |
|---|---|---|---|
| GPT-5.4 | SWE-bench Multilingual | +3.3% | -26.0% |
| GLM-5.1 | SWE-bench Pro | +5.0% | unknown |
| Kimi-K2.6 | SWE-bench Multilingual | +2.0% | unknown |
The key result is higher accuracy alongside fewer tokens. A 26% token reduction with GPT-5.4 is a meaningful cost figure. With the 4B model handling the broad search that the main agent used to perform, the main agent can focus solely on writing code and making decisions.
The code repository is publicly available at https://github.com/microsoft/fastcontext.
Serving and Deployment
The license is MIT. Commercial use, modification, and redistribution are unrestricted.
As a 4B model, resource requirements are low. Approximately 8GB VRAM at BF16 is sufficient, covering A100 40GB, A10G 24GB, and RTX 4090 24GB. vLLM and SGLang are officially supported, and quantized variants for llama.cpp, Ollama, LM Studio, and Jan are also available.
A single GPU is sufficient for vLLM serving.
vllm serve microsoft/FastContext-1.0-4B-SFT \
--dtype bfloat16 \
--max-model-len 131072
Using the full 262K context requires careful calculation of GPU VRAM and KV cache memory. In practice, the p95 context length for actual repository exploration tasks is usually shorter, so measuring real usage patterns first and then setting --max-model-len accordingly is the rational approach.
ThakiCloud Perspective and Connection to subagent-model-routing
Separating subagent roles in the agent pipeline. The subagent-model-routing rule in operation on the ThakiCloud platform specifies using small models such as Haiku for exploration and file-reading tasks. FastContext is exactly the dedicated model that role calls for. A configuration pairing claude-sonnet or another large model as the main coding agent with FastContext-4B attached as a repository exploration subagent via an on-premises vLLM endpoint is straightforward.
# Kueue WorkloadPriorityClass example
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
name: fastcontext-inference
namespace: ai-agents
spec:
clusterQueue: small-gpu-queue
The 4B model’s small footprint makes it cost-effective when placed in Kueue’s small GPU queue. While the main agent uses a large GPU queue, FastContext runs independently in a separate small queue.
Cost reduction path. If a significant share of coding agent task tokens on the ThakiCloud platform currently goes toward repository exploration, introducing FastContext can reduce main agent token consumption. How closely the SWE-bench figure of 26% token reduction carries over to real workloads depends on the characteristics of the internal codebase, so a pilot measurement should come first.
The MIT license permits on-premises deployment and fine-tuning without restriction. Additional fine-tuning targeted at the languages and structures of specific internal codebases can push exploration accuracy further. The training data formats (parallel_toolcalls, multiturn_traj, linerange) are publicly available, making it possible to build similar datasets from internal repository exploration traces.