Measuring AI’s Economic Impact Beyond Log Analysis: A Look at Anthropic’s Economic Index ‘Cadences’ Report

Overview
Once you bring an AI platform into an enterprise, you eventually face one question: “So how much did it actually help?” Until now, the answer has mostly been system metrics. How many API calls happened, how many tasks were processed, how many milliseconds the response took. The numbers are clean, but they never reach what executives really want to know: “What did our organization actually produce more of?”
That is why Anthropic’s Economic Index report “Cadences”, published on June 26, 2026, is interesting. It is not a routine usage-statistics update. It publicly declares that the way AI’s economic impact is measured has itself changed. Starting from the recognition that chat logs alone cannot explain how AI affects work, it broadens the basis of measurement along three tracks.
For a company like ThakiCloud, which actually operates a multi-tenant AI/ML platform on Kubernetes, this shift is not someone else’s story. The report shows, with data, the move in how we explain ROI to customers from “system metrics” toward “work outputs and worker perceptions.” This post organizes the three methodological shifts based on the report’s official material and considers what we can take from them as a platform.
What Is This Report?
Anthropic has analyzed Claude usage through the Economic Index since 2023. Every prior report leaned on seven-day sample data: slicing out one week and examining usage patterns within it. A year ago, most Claude usage was a conversation between a user and an assistant, so even this method captured a reasonable picture.
But as Claude Code and Cowork grew rapidly, a large share of sessions shifted to long-running agentic tasks. Chat transcripts no longer fully capture how people use AI. Anthropic says it reworked its data pipeline in three directions to keep pace: sampling at a higher rate to see patterns down to the hourly level, introducing a new classifier that labels the output of each conversation, and breaking out chat/Cowork and 1P API results at a monthly level for finer granularity.
One more track is added. Anthropic admits it has lacked visibility into impact outside user sessions, that is, how people perceive AI. So it presents initial results from the Economic Index Survey launched in April 2026. In short, the report is built on three axes: hourly cadences, artifact classification, and perception survey.
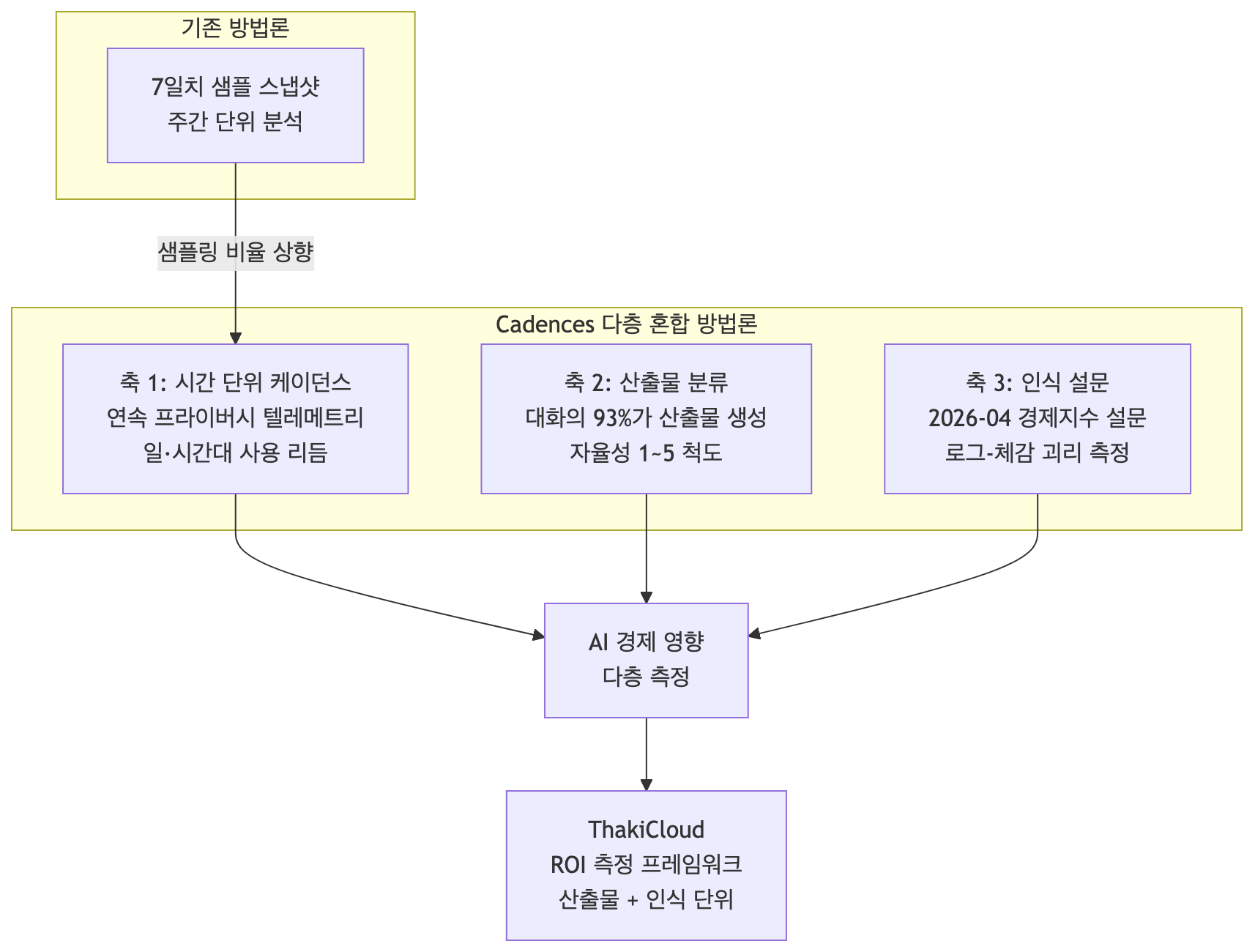
Axis 1: Hourly Cadences
The most striking change is the introduction of privacy-preserving telemetry. By continuously sampling a slice of conversations each day, it captures daily and hourly flows, unlike the prior seven-day snapshots. This data makes it possible, for the first time, to see how the rhythms of daily life are reflected in Claude usage.
The results are intuitive yet new. Claude usage tracks the weekday work pattern, while personal prompts rise on weekends. Going hour by hour, it gets sharper. People most often ask for sleep advice around 5 a.m., and ask for recipes around 6 p.m. News requests cluster in the morning. Patterns also react to specific dates: tax-related requests surged just before the US filing deadline of April 15.
Differences by the nature of work also appear. When people do turn to Claude for work on nights and weekends, those tasks skew toward higher-wage occupations, such as marketing managers or programmers, who are more likely to work outside traditional hours. By contrast, tasks in the bottom wage quartiles, like telemarketing or clerical work, fall to a smaller share on nights and weekends. Anthropic adds that the pattern holds even in a robustness check that removes computer and mathematical occupations. It is a signal that AI is functioning not as simple automation but as an assistive tool for high-skill work.
Axis 2: The Artifact Classifier
The second shift is classifying the outputs of conversations. Anthropic sorted what artifact each chat and Cowork conversation produces into more than 30 categories: a document, an explanation, a piece of code, an academic paper, and so on, meaning the primary output Claude produced in that conversation.
The classifier judged that 93% of Claude conversations produce an artifact. The most common types are explanations (17%), documents and reports (15%), and guidance (11%). Conversational outputs like explanations or guidance and written deliverables like documents or presentations each account for about a third, while code and technical outputs like apps or scripts account for about a sixth.
A second finding follows, the autonomy score. Anthropic measures how much judgment is delegated to Claude on a 1-to-5 scale. Tasks with largely fixed answers, like translation or calculation, have low autonomy, while tasks that require choosing among many options, like building apps, games, or presentations, have high autonomy.
The same artifact is measured as having higher autonomy when made with Claude Code. Across 26 of the 31 outputs shown, autonomy was higher on Claude Code than chat or Cowork, with an average gap of 0.37 points. For scripts and code snippets the gap widens to 0.53 points. About two thirds of this difference comes from the same tasks being executed with more delegation. Blog posts are a good example: the median chat/Cowork conversation producing one involves 13 rounds of back-and-forth, while on Claude Code people delegate more judgment. In other words, users are handing AI more autonomy.
Axis 3: The Perception Survey
The third axis is data drawn not from logs but by asking people directly. Anthropic launched the Economic Index Survey in April 2026, asking actual Claude users how much of their work AI can do. Survey responses are linked to usage data through privacy-preserving methods.
Respondents were asked what share of their work tasks AI can do entirely on its own today (reported exposure) and what share they expect it to handle in 12 months (anticipated exposure). Close to 6 in 10 respondents chose a higher band for next year, and over a third expect AI to be able to do most or nearly all of their work tasks next year.
The differences across groups are clear. Respondents in lower-income countries tended to feel AI could replace more of their work. Anthropic cites prior research showing such countries tend to use Claude in more automated ways. Differences by experience also appear: workers with at least 15 years of experience placed the share of tasks AI can do roughly 10 percentage points lower than those in their first year, with the interpretation that experienced workers have accumulated tacit, context-specific expertise that AI struggles to mimic. Respondents named judgment, contextual awareness, situational reasoning, and the relational dimensions of building trust and managing people as things AI cannot do. Worries about displacement were concentrated among early-career and low-wage workers.
Implications for ThakiCloud’s K8s AI/ML SaaS Platform
What this report offers ThakiCloud lies not in a feature but in a measurement framework. Anthropic’s approach starts from the premise that “logs alone cannot explain AI’s value,” and that is a perspective we can apply directly as an enterprise AI platform operator.
Until now, we too have centered ROI explanations on system metrics: call counts, throughput, response speed. But this report poses questions at a different layer. What was produced in that conversation? Was the output made during work hours or during overnight overtime? How much autonomy did the user delegate to AI? How much do users themselves feel AI replaces their work?
These questions are measurable on our stack. ThakiCloud handles Kubernetes- and Kueue-based GPU scheduling, vLLM serving, and multi-tenant agent operation in one place. Layering an artifact classifier on the telemetry from this stack lets us capture when, and in what form, a customer’s employees produce outputs together with AI. Then we can explain AI’s effect not as the abstract “improved efficiency” but in concrete output units. The finding that high-wage tasks rise on overnight shifts can become a gauge for whether AI is settling in as an assistive tool for high-skill work in our customers’ organizations too.
The way the survey and logs are linked is also worth borrowing. Measuring the gap between actual usage data and perceived capability reveals which groups benefit most after AI adoption and which feel anxious. That is an insight that feeds directly into a customer’s internal change management strategy. For domestic customers who must measure on-premise without sending data outside, privacy-preserving measurement design is a requirement, not an option, and our multi-tenant isolation and self-hosting structure fit that requirement precisely.
Ultimately, Anthropic’s direction is a commitment to keep refining how AI’s economic impact is measured. One of ThakiCloud’s strong differentiators is the role of a partner that goes beyond providing a platform to co-designing this measurement framework and interpreting the data. The ability to measure AI ROI not at the log level but at the level of work outputs and worker perception will be a core competitive edge in the enterprise AI platform market.
Limitations and Counterarguments
For balance, the report’s limits deserve mention. First, since the data comes from Claude users, there is sample bias. These are the usage patterns and perceptions of a group already using AI actively, so generalizing to the whole workforce is hard. Anthropic itself repeatedly notes it cannot conclusively identify occupations, and the by-occupation estimates over time are inferred backward from task characteristics, so causation cannot be asserted.
The survey data should be read even more carefully. The expectation that “AI will handle most of my work next year” is a perception, not a verified capability. The report itself confirms that perceived capability runs higher than observed occupational exposure. The gap between expectation and reality is itself the object of measurement, not grounds for treating expectation as the future.
Finally, refining a measurement method does not by itself enlarge the impact. Seeing more precisely and something happening more are different claims. The value of this report is not the conclusion that “AI has replaced this much work,” but that it rebuilds the question “how do we measure that impact more honestly” with a layered, mixed-method approach. What ThakiCloud should take is not the conclusion but the measurement attitude.
Sources
- Anthropic, “Anthropic Economic Index report: Cadences” (2026-06-26)
- Anthropic, “Anthropic Economic Index Survey” (2026-04)