SkillRet: ThakiCloud Sets the Retrieval Standard for Agents Managing Thousands of Skills
⏱️ Estimated reading time: 6 min
The More Skills an Agent Has, the Easier It Gets Lost
Anyone who has operated an LLM agent for a while hits the same wall. At first, with just a handful of skills, the agent picks the right one on its own. But once the library grows to hundreds or thousands, the situation reverses. The agent fails to find the right skill at the moment it matters, or it grabs the wrong one with a similar name. Even if a task is decomposed perfectly, the whole thing falls apart if the right tool cannot be surfaced.
That is the skill retrieval problem. Given a user request, often long and noisy natural language, pull the genuinely matching skill to the top out of thousands of candidates. It looks similar to document retrieval in RAG, but the nature is different. Documents exist to be read; skills exist to be executed. A misretrieved document slightly blurs an answer. A misretrieved skill causes the agent to take the wrong action.
The problem is clear, but there was no realistic large-scale benchmark to measure it properly. So ThakiCloud built one. The paper is “SkillRet: A Large-Scale Benchmark for Skill Retrieval in LLM Agents” (arXiv:2605.05726), authored by Hongcheol Cho, Ryangkyung Kang, and Youngeun Kim.
What SkillRet Is Made Of
SkillRet starts from scale and realism. Rather than toy lab data, it collects real publicly available agent skills and reframes them as a retrieval problem.
- 17,810 public agent skills collected.
- A two-level taxonomy: 6 top-level categories, 18 subcategories, plus semantic tags.
- 63,259 training samples.
- 4,997 evaluation queries, with the skill pool for training and evaluation kept disjoint.
That last point matters most. If evaluation reuses skills seen during training, scores look good but generalization ability remains unknown. Keeping the pools separate means honestly measuring whether retrieval works on a set of skills the model has never seen before.
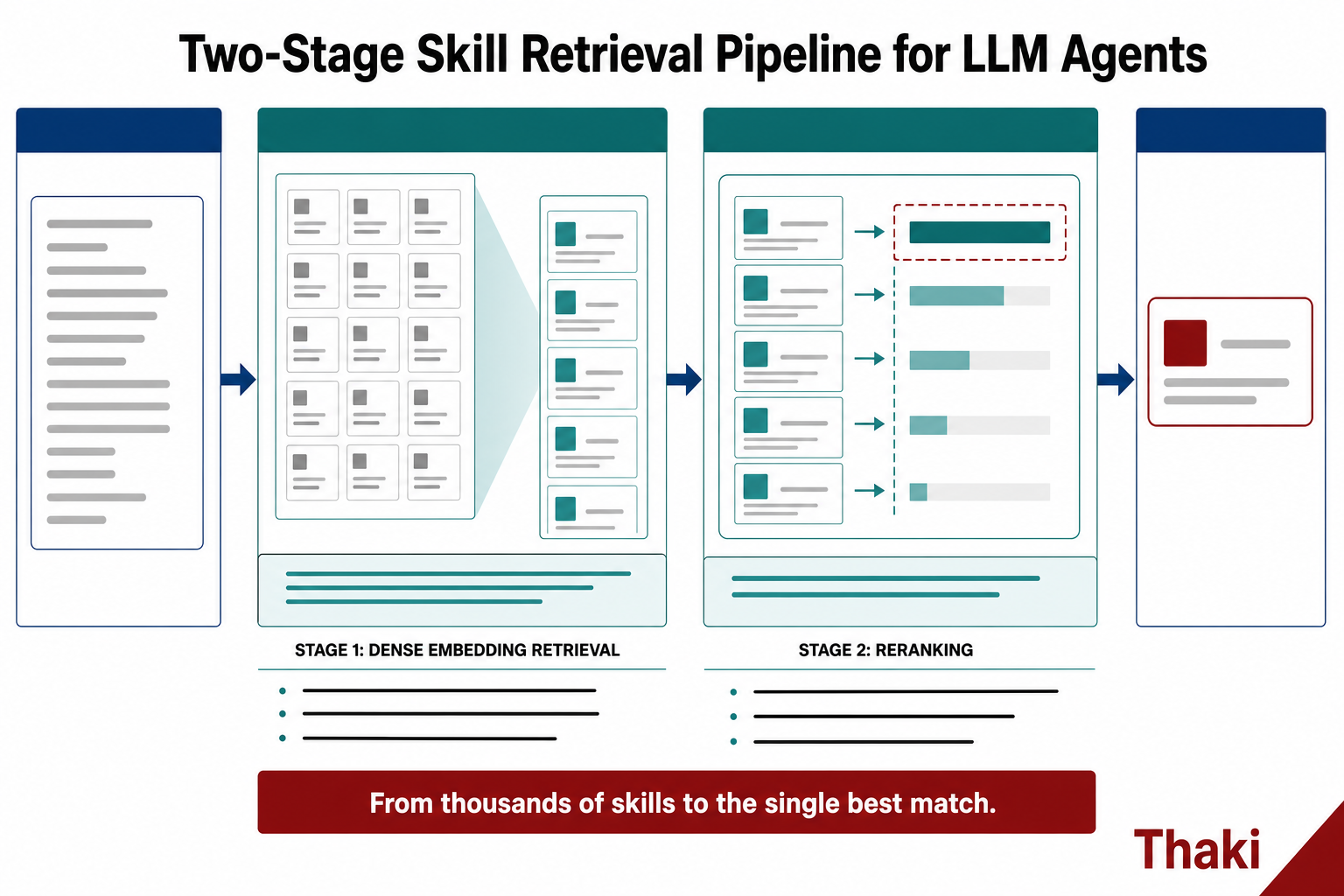
Two-Stage Pipeline: Embed to Narrow, Rerank to Select
The retrieval approach SkillRet proposes adapts a well-validated pattern from search systems to the skill domain, using a two-stage structure.
- Stage one: dense embedding retrieval. The query and all skills are projected into the same vector space, and semantically close candidates are quickly shortlisted. Scoring all thousands of skills precisely is expensive, so this stage casts a wide net first.
- Stage two: reranking. Only the candidates from stage one are scored more precisely. With a narrow candidate set, the extra compute is affordable, and accuracy improves accordingly.
This division of labor between wide filtering and narrow selection is the core idea. Rather than asking one model to handle both recall (not missing anything) and precision (ranking the right one to the top), the stages each do what they are good at.
Results: Fine-Tuning Finds Signal Inside the Noise
The numbers state the conclusion most clearly. The fine-tuned retrieval model achieved the following on the general NDCG@10 metric.
| Comparison | NDCG@10 gain |
|---|---|
| vs. the strongest existing retriever | +13.1 |
| vs. off-the-shelf retrievers | +16.9 |
The insight from these numbers goes beyond a score. Fine-tuned models focused better on skill-relevant signals even inside long, noisy queries. Real user requests are not clean. They mix background context, tangents, and ambiguous phrasing. The ability to cut through that noise and identify what the task actually requires is what separates a general retriever from a purpose-built fine-tuned one.
The published models make the picture concrete.
| Model | Base | Key metrics |
|---|---|---|
| SKILLRET-Embedding-0.6B | Qwen3-Embedding-0.6B | NDCG@15 0.7887 / Recall@15 0.8809 |
| SKILLRET-Embedding-8B | Qwen3-Embedding-8B | NDCG@10 0.8345 / Recall@10 0.9123 |
The 0.6B model was trained on 4x B200 GPUs for roughly 6 hours and recorded 1,188 downloads in the past month. The 8B model pushes precision further with a larger base. Start with 0.6B if size matters; choose 8B if accuracy is the priority.
Everything Is Open
Research gains its value when others can reproduce it. SkillRet releases the paper, data, models, and code all under Apache-2.0.
- Paper: arXiv:2605.05726
- Code: github.com/ThakiCloud/SKILLRET (Python, two-stage pipeline, automatic HF download, multi-GPU support)
- Dataset: huggingface.co/datasets/ThakiCloud/SKILLRET (220,576 records, 725 MB)
- Embedding model 0.6B: huggingface.co/ThakiCloud/SKILLRET-Embedding-0.6B
- Embedding model 8B: huggingface.co/ThakiCloud/SKILLRET-Embedding-8B
Clone the repository, let it automatically pull models and data from HF, and run training and evaluation directly in a multi-GPU environment.
Why ThakiCloud Tackled This Problem Directly
The phrase “skill economy” is not an overstatement. The era in which agents combine thousands of reusable skills to get work done has already started. And at the foundation of that economy sits a retrieval layer that finds exactly the right skill at exactly the right moment. When that layer is shaky, everything built on top of it shakes too.
ThakiCloud did not treat this retrieval layer as an abstract future challenge. Our platform already routes over 1,000 skills in production. When a task arrives, candidates are retrieved, fitness is assessed, and if nothing fits, the request falls through to default handling rather than forcing a bad match. The challenge SkillRet formalizes, pulling real signal from noisy queries, is the daily operational reality we work in.
So we formalized the problem as research, made it measurable through a benchmark, fine-tuned Qwen3-Embedding as our base model, and produced a +16.9 NDCG improvement over off-the-shelf alternatives. Then we released everything, from dataset to model weights to training code, without holding anything back, under Apache-2.0. This is not a standalone lab paper. It is evidence that a pipeline from research to product actually works. The loop from operational bottleneck to research to product improvement exists inside ThakiCloud.
What It Means to Define the Standard First
Whoever defines the measurement standard first also shapes what gets built on top of it. SkillRet is not just a model with a good score. It is a public reference point for how to measure agent skill retrieval and what doing it well actually requires. The taxonomy, evaluation queries, disjoint pool design, and two-stage pipeline are bundled as a single reference that lets anyone measure their own system with the same ruler.
Any team building agent platforms seriously will eventually confront this retrieval layer. ThakiCloud has already put the reference material out there for when that moment arrives. We turned the problem of agents losing their way as skills multiply into a measurable problem, and we made the answer available to everyone.