프롬프트를 쓰지 않고 루프를 씁니다: 코딩 에이전트의 루프 엔지니어링
개요
최근 개발자 사이에서 한 문장이 화제가 됐습니다. “이제 나는 Claude Code에 프롬프트를 넣지 않는다. Fable에 프롬프트를 넣는 루프를 돌리고 있고, 내 일은 그 루프를 짜는 것뿐이다.” 자극적인 표현이지만, 마케팅성 과장을 걷어내고 보면 여기에는 실무적으로 의미 있는 관찰이 하나 들어 있습니다. 작업의 단위가 프롬프트 한 통에서 루프 한 벌로 옮겨간다는 것입니다.
이 변화는 모델이 좋아졌다는 이야기와는 결이 다릅니다. 아무리 강한 모델이라도 한 번의 프롬프트로 끝나는 단발 요청에서는 복잡한 작업을 끝까지 밀어붙이지 못합니다. 대신 모델이 도구를 호출하고, 그 결과를 다시 입력으로 받아 다음 행동을 결정하는 반복 구조에 얹으면 이야기가 달라집니다. ThakiCloud는 쿠버네티스 기반 AI/ML SaaS 플랫폼을 운영하면서 내부 개발에도 이런 루프를 실제로 돌리고 있습니다. 그래서 “루프를 짠다”는 표현은 우리에게 트렌드 문장이 아니라 매일의 엔지니어링 과제입니다. 이 글은 그 루프가 실제로 무엇으로 구성되는지, 그리고 무엇이 이 루프를 신뢰할 수 있게 만드는지를 정리합니다.
프롬프트에서 루프로: 무엇이 바뀌나
프롬프트를 쓰는 사고방식에서 사람은 한 번의 지시로 원하는 결과를 최대한 정확히 끌어내려 합니다. 좋은 프롬프트는 여전히 중요하지만, 이 방식의 한계는 분명합니다. 결과가 틀렸을 때 사람이 직접 읽고, 무엇이 어긋났는지 판단하고, 다시 프롬프트를 다듬어야 합니다. 사람이 매 반복의 채점자이자 다음 지시자가 되는 구조입니다.
루프를 쓰는 사고방식은 그 채점과 재지시를 구조에 넘깁니다. 사람은 개별 프롬프트가 아니라 “무엇을 목표로, 무엇을 관찰하고, 언제 멈출지”를 정의합니다. 모델은 그 안에서 행동하고, 외부 도구가 결과를 판정하며, 그 판정이 다시 모델의 다음 입력이 됩니다. 사람의 역할은 매 턴을 감시하는 일에서 루프의 경계와 종료 조건을 설계하는 일로 옮겨갑니다.
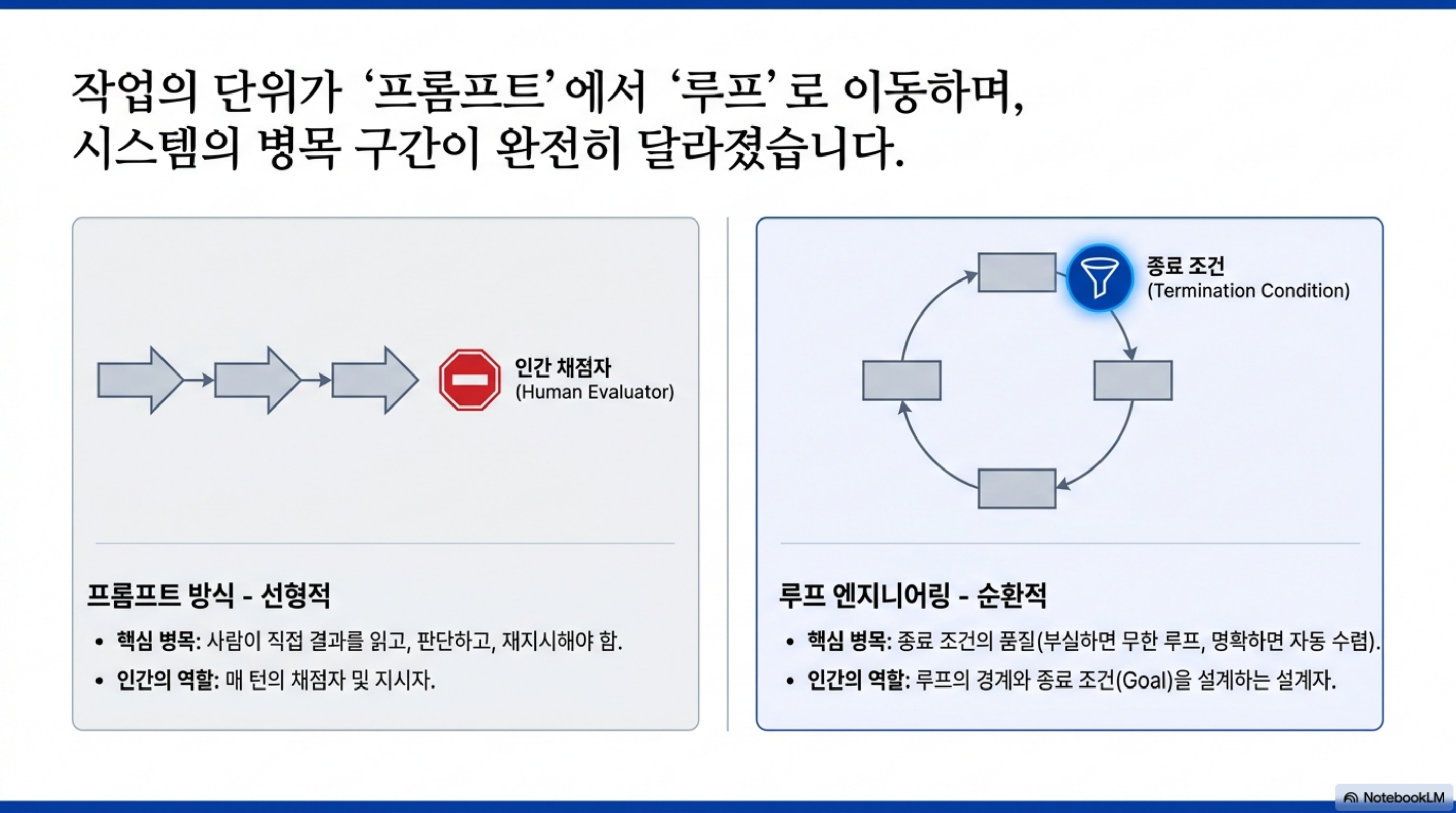
이 차이는 작아 보여도 결과적으로 큰 차이를 만듭니다. 프롬프트 방식에서 사람은 병목입니다. 사람이 결과를 다 읽어야 다음이 진행되기 때문입니다. 루프 방식에서 병목은 사람이 아니라 종료 조건의 품질입니다. 종료 조건이 명확하면 루프는 사람이 자리를 비운 사이에도 수렴을 향해 나아가고, 종료 조건이 부실하면 아무리 좋은 모델이라도 헛도는 반복에 빠집니다. 그래서 루프 엔지니어링의 핵심은 프롬프트 문장을 다듬는 재주가 아니라, 무엇을 성공으로 볼 것인가를 기계가 판정할 수 있게 만드는 설계 능력입니다.
루프의 해부: 관찰-판단-실행의 반복
실제로 잘 도는 코딩 루프는 대체로 같은 네 단계를 반복합니다. 모델이 변경을 제안하고(실행), 그 변경을 코드베이스에 적용한 뒤 외부 도구를 돌려 결과를 얻고(관찰), 그 출력을 파싱해 무엇이 왜 실패했는지 맥락으로 만들고(학습), 그 맥락을 다시 모델에 넣어 다음 제안을 받습니다(반복). 이 순환은 종료 게이트가 통과되거나 예산이 소진될 때까지 이어집니다.
flowchart TB
A[모델이 변경 제안<br/>Act] --> B[코드베이스에 적용]
B --> C[외부 도구 실행<br/>테스트·컴파일러·린터<br/>Observe]
C --> D[출력 파싱<br/>에러 메시지·라인·실패 이유<br/>Learn]
D --> E{종료 게이트<br/>통과?}
E -- "아니오" --> F[맥락을 모델에 재주입<br/>Repeat]
F --> A
E -- "예" --> G[루프 종료<br/>수렴]
D -.예산 소진.-> H[중단·사람에게 인계]
여기서 세 번째 단계인 학습이 특히 중요합니다. 도구의 출력을 요약하거나 압축해서 모델에 넣으면 루프가 잘 수렴하지 않습니다. 컴파일러가 뱉은 에러 메시지, 실패한 파일과 라인 번호, 타입 불일치의 구체적 내용을 그대로 다음 프롬프트의 맥락으로 넣어야 모델이 “왜 실패했는지”를 세션 간 기억 없이도 복원합니다. 사람이 보기에는 장황한 로그이지만, 루프에게는 그 장황함이 곧 수렴을 위한 신호입니다.
결정론적 게이트가 보상 신호입니다
루프 엔지니어링에서 가장 자주 어긋나는 지점은 종료 조건입니다. 모델에게 “이 작업이 끝났느냐”고 묻고 그 대답으로 루프를 멈추면, 모델은 “완료된 것으로 보입니다” 같은 자기 보고로 루프를 조기에 끝냅니다. 이것은 검증이 아닙니다. 신뢰할 수 있는 루프는 종료 판정을 모델이 아니라 결정론적 도구에 맡깁니다. 테스트가 통과하는가, 컴파일러가 에러 없이 빌드하는가, 타입 체커가 조용한가. 이 통과/실패 신호가 곧 강화학습에서 말하는 보상 신호의 역할을 합니다. 별도의 보상 모델을 학습시킬 필요 없이, 이미 존재하는 테스트 러너와 컴파일러가 “이 코드가 맞다”를 판정해 줍니다.

ThakiCloud는 이 원칙을 내부 루프에 그대로 박아 두었습니다. 대표적으로 pge-loop는 Go 백엔드에서 모델이 제안한 diff를 적용하고 make test-short를 돌린 뒤, 그 stderr 전체를 다음 제안의 맥락으로 되먹입니다. 종료 조건은 모델의 자기 판단이 아니라 테스트의 종료 코드입니다. 마찬가지로 Goal Mode는 목표를 달성 조건까지 자율적으로 추구하되, 매 스텝의 진행을 정해진 검증 명령으로 확인하고 예산(반복 횟수·비용·마감)이 상한을 이룹니다. 무한히 도는 것이 아니라 수렴하거나 소진될 때까지만 돕니다. 이 두 가지 안전장치, 즉 결정론적 종료 게이트와 예산 상한이 없으면 루프는 신뢰할 수 없는 도구가 됩니다.
fan-out을 쓰는 경우에는 규칙이 하나 더 붙습니다. 여러 서브에이전트를 병렬로 띄워 결과를 모을 때는, 그 결과를 합치기 전에 반드시 검증 스테이지로 루프를 닫습니다. 코드 산출물이면 테스트 게이트로, 판단이나 리서치 산출물이면 서로 다른 시각의 회의적 검증자를 여럿 띄워 표결로 걸러냅니다. 검증 없이 병렬 결과를 그대로 합치면 그럴듯하지만 틀린 산출물이 누적됩니다. 품질이 안 나올 때 가장 먼저 의심할 것은 모델의 등급이 아니라 검증 스테이지의 부재인 경우가 많습니다.
ThakiCloud 제품 적용 시사점
루프 엔지니어링은 ThakiCloud의 Paxis와 직접 맞닿아 있습니다. Paxis는 ai-platform 위에서 도는 Agent-Native Cloud 제어 평면으로, 스킬(Skills)과 도구(Tools), 정책(Policies), 감사 로그(Audit Logs)를 일급 리소스로 다룹니다. 사람이 짜는 루프가 개인 개발 환경에 머무르지 않고 플랫폼 수준의 리소스가 되려면, 루프를 구성하는 요소들이 관리 가능한 형태로 노출되어야 합니다. Paxis는 960여 개의 스킬을 BM25로 선택해 격리된 샌드박스에서 실행하고, 모든 행동을 정책 게이트와 감사 로그로 통과시킵니다. 즉 “무엇을 관찰하고 언제 멈출지”를 사람이 설계하면, Paxis가 그 루프의 실행을 격리하고 기록하고 통제하는 하부 구조를 제공합니다.
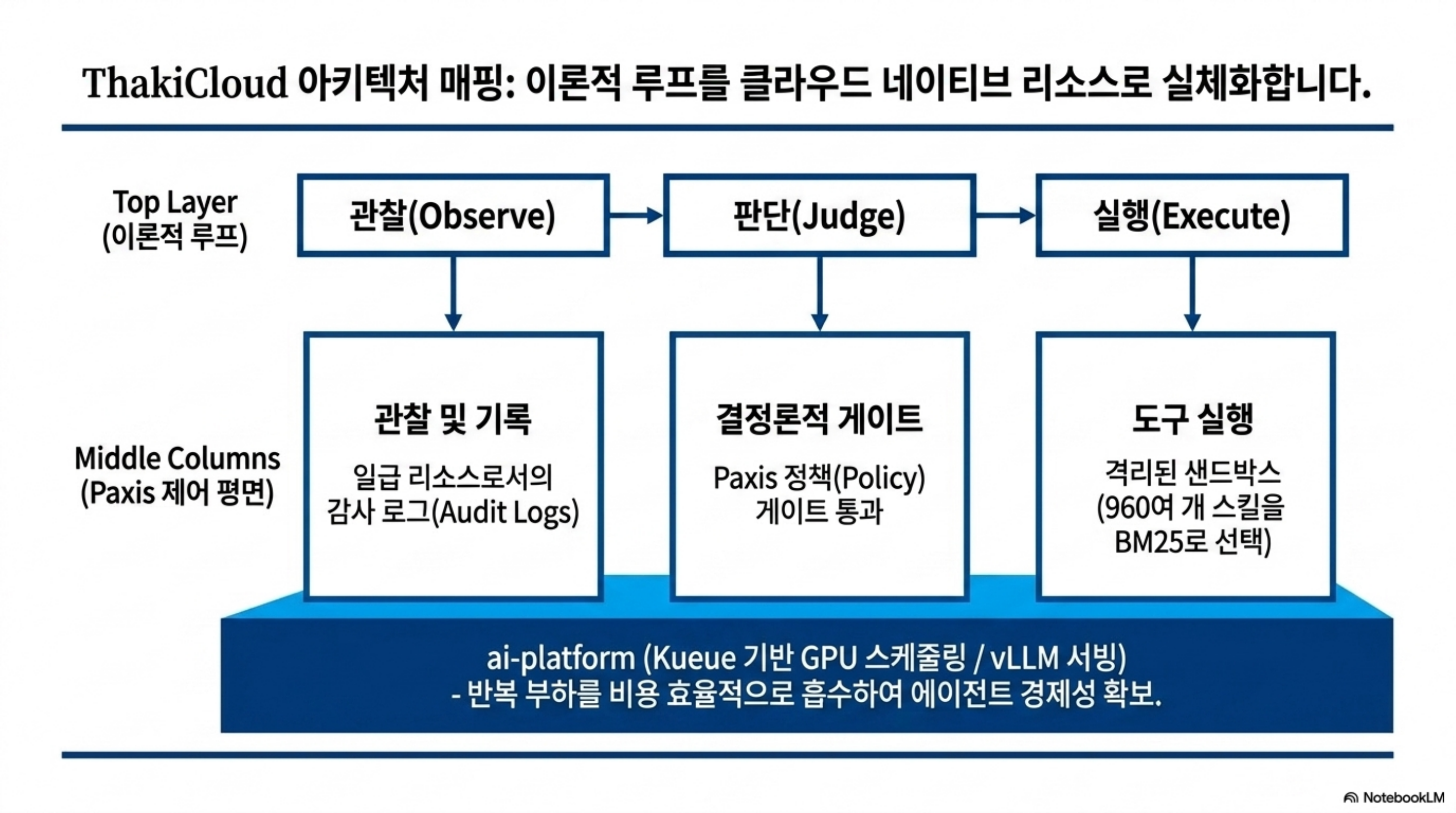
이 관점에서 결정론적 게이트는 Paxis의 정책 게이트로, 도구 실행은 샌드박스 격리 실행으로, 루프의 관찰 로그는 감사 로그로 자연스럽게 대응됩니다. 루프가 스스로를 검증하는 구조는 Paxis가 강조하는 “검증으로 닫는 fan-out”과 같은 원리입니다.
인프라 측면에서는 ai-platform 렌즈가 이 이야기를 보완합니다. 루프를 많이 돌린다는 것은 곧 반복적인 추론 호출과 테스트 실행이 늘어난다는 뜻입니다. ai-platform은 쿠버네티스와 Kueue 기반 GPU 스케줄링, vLLM 서빙, 멀티테넌트 격리로 이 반복 부하를 비용 효율적으로 흡수합니다. 낮은 서빙 비용이 있어야 루프를 자주 돌리는 것이 경제적으로 성립하고, 그 경제성이 다시 에이전트를 상시 운용 가능한 형태로 만듭니다. 저비용 서빙(ai-platform)이 에이전트 경제성(Paxis)을 만든다는 연결이 여기서 성립합니다. 온프레미스와 소버린 요구가 있는 고객에게는 이 루프 전체를 자체 인프라 안에서 돌릴 수 있다는 점이 특히 의미가 큽니다.
한계 및 반론
루프 엔지니어링을 만능으로 포장하는 것은 정직하지 않습니다. 첫째, 종료 게이트를 만들 수 없는 작업에는 루프가 오히려 위험합니다. 통과/실패를 자동으로 판정할 명령이 없으면 루프는 수렴 지점을 모른 채 예산만 태웁니다. 이럴 때는 한 번에 처리하는 단발 방식이 더 낫고, 그 사실을 정직하게 인정하는 편이 낫습니다.
둘째, 루프가 깊어질수록 사람이 결과를 신뢰하고 검토를 멈추는 경향이 생깁니다. “어차피 루프가 검증하겠지”라는 태도는 가장 은밀한 실패 모드입니다. 자동화는 사고를 대체하는 것이 아니라 보조하는 도구이며, 핵심 산출물은 여전히 사람이 주기적으로 표본 검토해야 합니다. 검증기가 아무것도 걸러내지 못한다면 그것은 전부 통과했다는 뜻이 아니라 검증기가 고장 났다는 신호일 가능성이 높습니다.
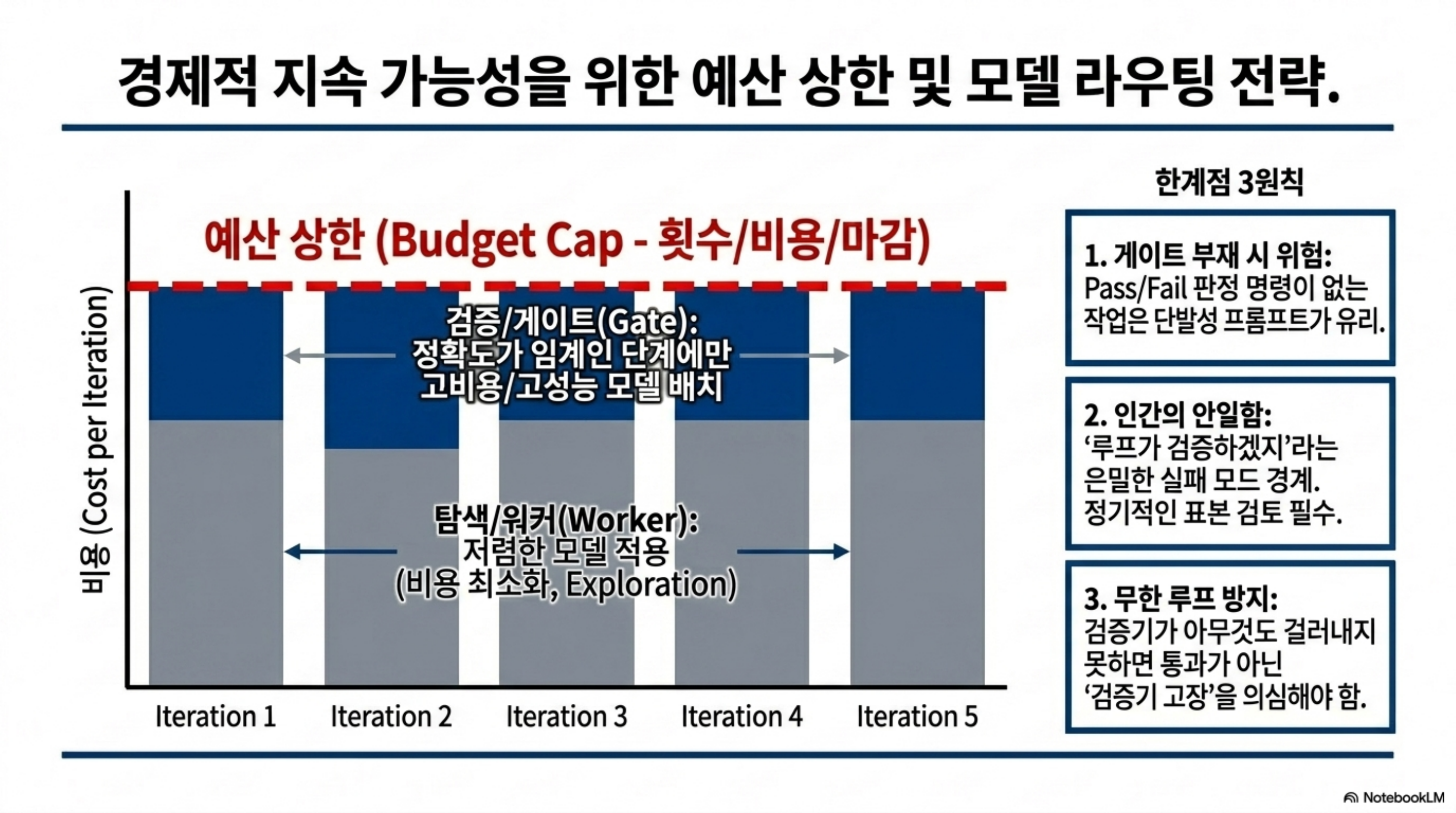
셋째, 비용입니다. 루프는 정의상 여러 번의 추론 호출을 소모합니다. 상한을 두지 않으면 예산이 순식간에 소진되고, 강한 모델을 상시로 붙여 두면 비용이 선형이 아니라 배수로 늘어납니다. 실무에서는 탐색과 반복 실행에는 저렴한 모델을 쓰고, 정확도가 임계인 검증 단계에만 비싼 모델을 배치하는 라우팅이 필요합니다. 워커는 싸게, 게이트만 비싸게라는 원칙이 여기서도 그대로 적용됩니다.
정리하면, “프롬프트를 쓰지 않고 루프를 쓴다”는 문장은 도발적이지만 그 안에는 실질이 있습니다. 다만 그 실질은 화려한 모델이 아니라, 무엇을 성공으로 볼 것인가를 기계가 판정하게 만드는 지루한 설계에서 나옵니다. ThakiCloud가 pge-loop와 Goal Mode에서 배운 교훈도 같습니다. 좋은 루프는 좋은 종료 조건에서 나옵니다.
출처
- Miles Deutscher, X(구 Twitter) 게시물, 코딩 에이전트 루프에 관한 의견
- ThakiCloud 내부 loop-engineering 실천: pge-loop, Goal Mode(검증 게이트 + 예산 상한)