스킬을 ‘소프트웨어처럼’ 다루는 메타스킬: yao-meta-skill v1.1.0 직접 검증 리포트
 스킬을 일회성 프롬프트가 아니라 버전·검증·거버넌스가 붙은 ‘재사용 자산’으로 다루는 메타스킬의 개념도입니다.
스킬을 일회성 프롬프트가 아니라 버전·검증·거버넌스가 붙은 ‘재사용 자산’으로 다루는 메타스킬의 개념도입니다.
개요
Claude Code, Cursor, Codex CLI 같은 에이전트 환경에서 스킬(Skill)은 더 이상 단순한 프롬프트 모음이 아닙니다. 반복되는 업무를 패키징해 여러 하니스(harness)를 가로질러 재사용하는 능력 상품에 가깝습니다. 그런데 스킬이 늘어날수록 품질 편차, 트리거 충돌, 컨텍스트 비용이라는 세 가지 문제가 동시에 커집니다. 중국 인플루언서 @vista8(팔로워 약 113K)이 “Anthropic 공식 Skill-creator보다 강력하다”고 추천하면서 화제가 된 오픈소스 프로젝트 yao-meta-skill은 바로 이 지점을 정조준합니다.
이름의 YAO는 “Yielding AI Outcomes”의 약자이며, 저장소 설명은 스스로를 “재사용 가능한 에이전트 스킬을 위한 엄격한 엔지니어링·평가·거버넌스·이식성 시스템”이라고 규정합니다. 저는 이 주장을 그대로 받아들이지 않고 ThakiCloud 작업 환경에 직접 클론한 뒤, 저장소가 함께 제공하는 로컬 검증 게이트를 실제로 실행해 보았습니다. 이 글은 그 실측 결과를 바탕으로 yao-meta-skill의 구조를 분해하고, 사내 .claude/skills 운영 관점에서 무엇을 빌려올 수 있는지 정리한 구현 리포트입니다.
이 도구는 무엇인가
yao-meta-skill은 “스킬을 만들어 주는 스킬”, 즉 메타스킬입니다. 워크플로 노트, 프롬프트 세트, 대화 트랜스크립트, 런북, 문서 패턴처럼 반복되는 작업을 입력으로 받아 검증 가능한 스킬 패키지로 변환합니다. 핵심 설계는 세 개의 기둥으로 정리됩니다.
첫째, Skill IR(Intermediate Representation) 입니다. 의도, 트리거, 입력, 출력, 경계(boundaries), 참조, 기대 산출물을 플랫폼 중립적인 중간 표현으로 먼저 기술합니다. 그다음 타깃 컴파일러와 어댑터가 이 IR을 OpenAI, Claude, 일반 에이전트 스킬, Agent-Skills 호환 패키지, VS Code 지향 워크플로 등 다섯 가지 타깃으로 변환합니다. 한 번 기술한 스킬을 여러 환경으로 컴파일한다는 발상은, 사내에서 같은 스킬을 Claude Code와 Cursor 양쪽에 중복 관리하던 부담을 정확히 겨냥합니다.
둘째, Output Eval Lab 입니다. 트리거 검사, 출력 단언(assertion), 실행 증거, 시간·토큰 증거, 벤치마크 재현성, 블라인드 리뷰 팩까지 스킬의 출력 품질을 데이터로 검증하는 계층입니다. 모델이 “잘 됐다”고 주장하는 대신 코드가 실제로 검증하는 구조라는 점이 인상적입니다.
셋째, Review Studio 2.0 입니다. 의도, 트리거, 출력 평가, 컨텍스트 비용, 런타임 점검, 릴리스 증거를 하나의 HTML 게이트 페이지로 모아 보여 줍니다. 스킬 하나를 릴리스하기 전에 무엇을 통과해야 하는지를 시각적으로 확정하는 관문입니다.
라이선스는 MIT이며, 매니페스트는 성숙도 등급을 “governed”, 라이프사이클 단계를 “library”, 리뷰 주기를 “quarterly”로 선언합니다. 스킬을 코드처럼 버전·등급·리뷰 주기로 관리하겠다는 의도가 메타데이터 수준에서부터 드러납니다.
 반복 작업 입력이 Skill IR을 거쳐 다중 플랫폼으로 컴파일되고, Output Eval Lab과 Review Studio 게이트를 통과해 릴리스 증거로 마무리되는 파이프라인입니다.
반복 작업 입력이 Skill IR을 거쳐 다중 플랫폼으로 컴파일되고, Output Eval Lab과 Review Studio 게이트를 통과해 릴리스 증거로 마무리되는 파이프라인입니다.
설치 및 통합 (실제 명령)
검증은 격리된 샌드박스에서 진행했습니다. 사내 규칙에 따라 작업 트리는 저장소 바깥에 두고, 종료 후 정리했습니다.
# 1) 외부 저장소 클론
git clone --depth 1 https://github.com/yaojingang/yao-meta-skill
# 2) 최소 의존성은 공용 .venv에 설치 (python-runtime 규칙)
VIRTUAL_ENV="$REPO_ROOT/.venv" uv pip install "PyYAML==6.0.3"
저장소의 의존성은 놀라울 만큼 가볍습니다. CI 요구 사항(requirements-ci.txt)은 PyYAML==6.0.3 단 한 줄이었습니다. 무거운 런타임 없이 순수 파이썬 표준 라이브러리 중심으로 검증 도구를 구성했다는 뜻이며, 이는 CI 파이프라인에 끼워 넣기 좋은 신호입니다.
저장소를 클론한 직후 측정한 실제 구성은 다음과 같습니다. 추적 파일 632개, 테스트 77개, 평가(evals) 29개, 스킬 아틀라스 항목 10개, 스키마 3개, 템플릿 2개입니다. 단일 “스킬 하나”가 아니라, 스킬을 생산·검증·거버넌스하는 작은 공장(factory)에 가깝습니다.
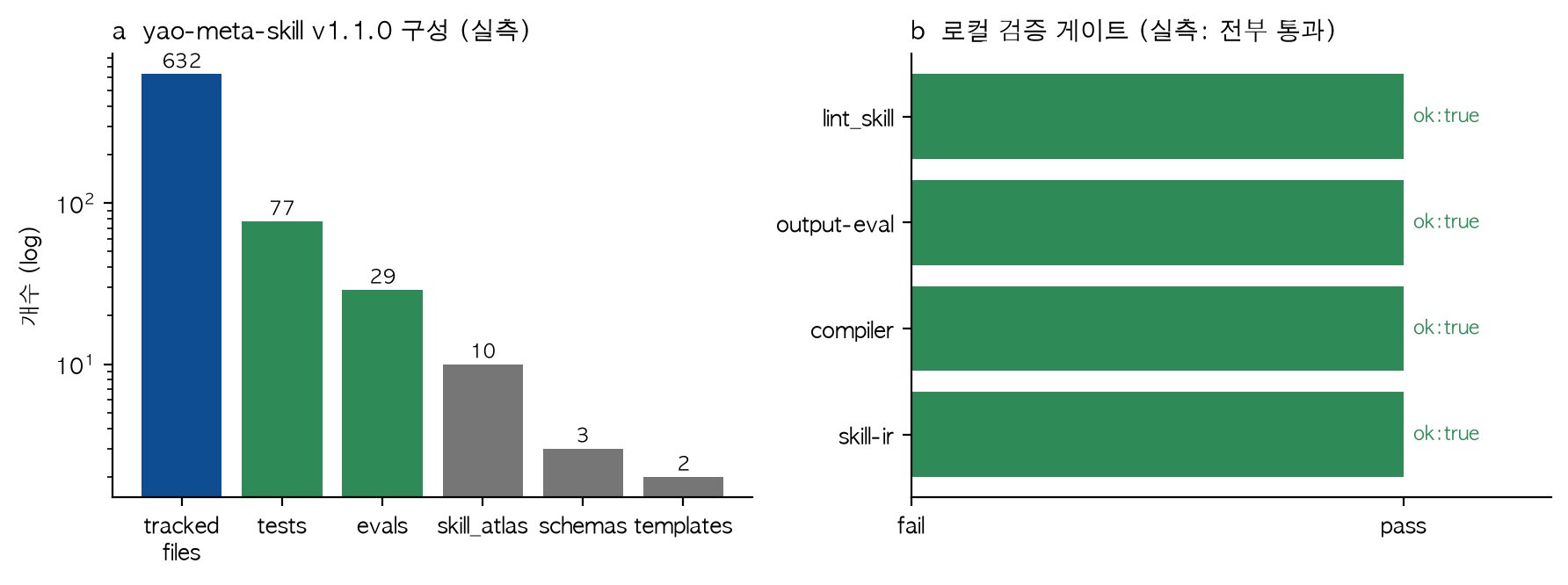 왼쪽은 저장소의 실측 구성(로그 스케일), 오른쪽은 로컬 검증 게이트 4종이 모두 통과한 결과입니다.
왼쪽은 저장소의 실측 구성(로그 스케일), 오른쪽은 로컬 검증 게이트 4종이 모두 통과한 결과입니다.
실제 검증 결과
Makefile에는 25개가 넘는 검증 타깃이 정의되어 있었습니다. 그중 스킬 IR, 컴파일러, 출력 평가, 린트 네 가지를 실제로 돌려 결과를 캡처했습니다.
make skill-ir-check
# python3 tests/verify_skill_ir.py -> {"ok": true}
# python3 tests/verify_skill_ir_paths.py -> {"ok": true}
make compiler-check
# python3 tests/verify_compile_skill.py -> {"ok": true}
make output-eval-check
# python3 tests/verify_output_eval_lab.py -> {"ok": true}
python3 scripts/lint_skill.py ./ # 번들된 SKILL.md 대상
# {"ok": true, "failures": [], "warnings": []}
네 개 게이트가 모두 ok: true로 통과했고, 린트는 실패 0건·경고 0건이었습니다. 이 수치는 제가 직접 실행해 캡처한 값이며, 외부에서 인용한 것이 아닙니다. 흥미로운 점은 검증 결과가 산문이 아니라 {"ok": true} 형태의 결정론적 JSON으로 출력된다는 것입니다. 이는 사람이 읽고 판단하는 보고가 아니라, 상위 파이프라인이 자동으로 게이트할 수 있는 기계 판독 형식입니다. ThakiCloud가 사내 룰에서 강조해 온 “포맷은 코드가 소유한다”는 원칙과 정확히 같은 방향입니다.
다만 한 가지 한계도 실측으로 드러났습니다. lint_skill.py는 인자 없이 호출하면 사용법 오류를 내고, 스킬 디렉터리를 명시해야 동작했습니다. 컨텍스트 사이즈 측정 스크립트(context_sizer.py)는 일부 경로에서 토큰 추정값을 0으로 반환했는데, 인자 전달 방식에 민감한 것으로 보였습니다. 즉 “make 타깃은 잘 동작하지만, 개별 스크립트를 직접 호출할 때는 인터페이스를 정확히 맞춰야 한다”는 운영상의 주의가 필요합니다.
ThakiCloud K8s AI/ML SaaS 플랫폼 적용 및 시사점
ThakiCloud는 이미 1000개가 넘는 사내 스킬과 룰을 운영하고 있습니다. 이 규모에서 가장 큰 비용은 스킬 자체가 아니라, 인덱스에 올라간 모든 스킬이 매 세션 지불하는 컨텍스트 세금과 트리거 충돌입니다. yao-meta-skill에서 빌려올 만한 지점은 세 가지로 압축됩니다.
첫째, Skill IR 발상의 부분 도입입니다. 사내 스킬을 Claude Code와 Cursor 양쪽에 중복 관리하는 대신, 의도·트리거·경계를 중립적으로 한 번만 기술하고 환경별로 컴파일하는 패턴은 관리 표면을 줄여 줍니다. 전면 도입은 과하더라도, 신규 스킬의 description과 트리거를 IR 스키마처럼 구조화하는 것만으로도 효과가 있습니다.
둘째, Output Eval Lab식 게이트의 차용입니다. 사내에는 이미 편집 게이트와 결정론적 검증 스크립트가 있지만, “트리거가 의도대로 발화하는가”를 데이터로 검사하는 트리거 평가는 상대적으로 약합니다. 스킬 라우터의 오발화(distractor noise)를 줄이는 데 직접 쓸 수 있는 패턴입니다.
셋째, Review Studio식 단일 릴리스 게이트입니다. 새 스킬을 머지하기 전에 의도·트리거·컨텍스트 비용·런타임을 한 페이지에서 확인하는 관문은, K8s 위에서 돌아가는 AI/ML SaaS의 배포 게이트(ArgoCD, Kueue)와 철학적으로 동형입니다. 코드 배포에 게이트를 거는 것처럼, 스킬 배포에도 게이트를 거는 것입니다.
한계 및 반론
낙관 일변도로 정리하지 않기 위해 반대 논거도 분명히 적습니다.
첫째, “공식보다 강력하다”는 주장의 출처는 인플루언서 추천이라는 점입니다. 저장소 구조와 로컬 검증이 견고한 것은 사실이지만, Anthropic 공식 Skill-creator는 대화 우선의 빠른 생성 루프에 강점이 있어 목적이 다릅니다. 두 도구는 경쟁이라기보다 상보적입니다. “더 강력하다”는 비교는 거버넌스가 필요한 팀 자산을 만들 때에 한정해 받아들이는 편이 정확합니다.
둘째, 도입 비용입니다. 632파일 규모의 공장을 그대로 들이는 것은 1인 또는 소규모 팀에는 과합니다. 핵심 발상(IR, 트리거 평가, 단일 게이트)만 선별적으로 차용하는 것이 현실적입니다.
셋째, 운영 인터페이스의 민감성입니다. 앞서 실측으로 확인했듯, 개별 스크립트는 인자에 민감하고 일부 측정값이 0으로 나오는 경우가 있었습니다. CI에 끼워 넣을 때는 make 타깃 단위로 감싸고, 개별 스크립트의 인터페이스를 고정해 두는 것이 안전합니다.
결론적으로 yao-meta-skill은 “스킬을 소프트웨어처럼 엔지니어링한다”는 방향성을 가장 구체적으로 구현한 오픈소스 사례 중 하나입니다. 전부를 도입하지 않더라도, 스킬이 자산이 되는 조직이라면 그 설계 원칙은 충분히 살펴볼 가치가 있습니다.
출처
- yao-meta-skill (GitHub, MIT): github.com/yaojingang/yao-meta-skill
- 저장소 매니페스트·검증 결과: 본 글의 모든 수치는 v1.1.0을 직접 클론해 로컬에서 측정한 값입니다.