OPD 사후학습: GLM-5.2는 어떻게 10개 넘는 전문가 모델을 이틀 만에 합쳤나
프론티어급 모델을 만드는 회사가 가중치만 공개하는 것은 이제 드문 일이 아닙니다. 그런데 Z.ai(THUDM)는 GLM-5.2를 내놓으면서 한 걸음 더 나갔습니다. 모델 가중치뿐 아니라 그 모델을 만든 강화학습 사후학습(RL post-training) 인프라 전체를 오픈소스로 풀었습니다. 가장 눈에 띄는 대목은 사후학습 방식입니다. Z.ai는 10개가 넘는 전문가 모델을 약 이틀 만에 하나로 합쳐 GLM-5.2를 완성했다고 보고합니다. 이 병렬 병합 과정을 OPD라고 부릅니다.
저희 ThakiCloud는 K8s 기반 AI/ML SaaS 플랫폼에서 학습 워크로드와 GPU 오케스트레이션을 다룹니다. “프론티어 모델을 어떻게 학습했는가”가 통째로 공개된 사례는 온프레미스 학습 인프라를 설계하는 입장에서 귀한 레퍼런스입니다. 이 글은 OPD 사후학습이라는 방식과, RL 스택 전체가 오픈된다는 사실이 무엇을 바꾸는지 짚어보겠습니다.
RL 사후학습 프레임워크 slime 자체에 대한 개괄은 별도 글 RL 사후학습을 인프라로: slime 오픈소스 프레임워크와 RL 스케일링에서 다뤘습니다. 이 글은 그 위에서 돌아가는 OPD 사후학습과 전문가 모델 병합에 초점을 맞춥니다.

GLM-5.2는 어떤 모델인가
먼저 대상 모델을 짚고 넘어가겠습니다. GLM-5.2는 753B 규모의 오픈웨이트 모델입니다. 긴 호흡의 작업(long-horizon task)을 겨냥했고, 1M 토큰 컨텍스트를 지원합니다. Z.ai는 IndexShare라는 기법으로 1M 컨텍스트 길이에서 토큰당 FLOPs를 2.9배 줄였다고 밝혔습니다. 즉 긴 컨텍스트를 다루면서도 추론 비용을 억제하는 쪽으로 설계가 맞춰져 있습니다.
벤치마크 수치를 보면 위치가 보입니다. 코딩 작업을 평가하는 Terminal-Bench 2.1에서 81.0을 기록해 Claude Opus 4.8의 85.0을 추격했습니다. SWE-bench Pro에서는 62.1로 직전 버전 GLM-5.1의 58.4보다 올랐습니다. 장기 작업을 보는 FrontierSWE에서는 Opus 4.8과의 격차가 약 1%까지 좁혀졌다고 보고됩니다. 클로즈드 프론티어 모델과 한 자릿수 격차까지 좁힌 오픈웨이트 모델이라는 점이 핵심입니다. 라이선스는 MIT이며 HuggingFace와 ModelScope에서 받을 수 있습니다.
이 정도 성능을 가진 모델을 “어떻게 학습했는가”가 공개됐다는 것이 이번 사례의 무게입니다.
OPD 사후학습이란 무엇인가
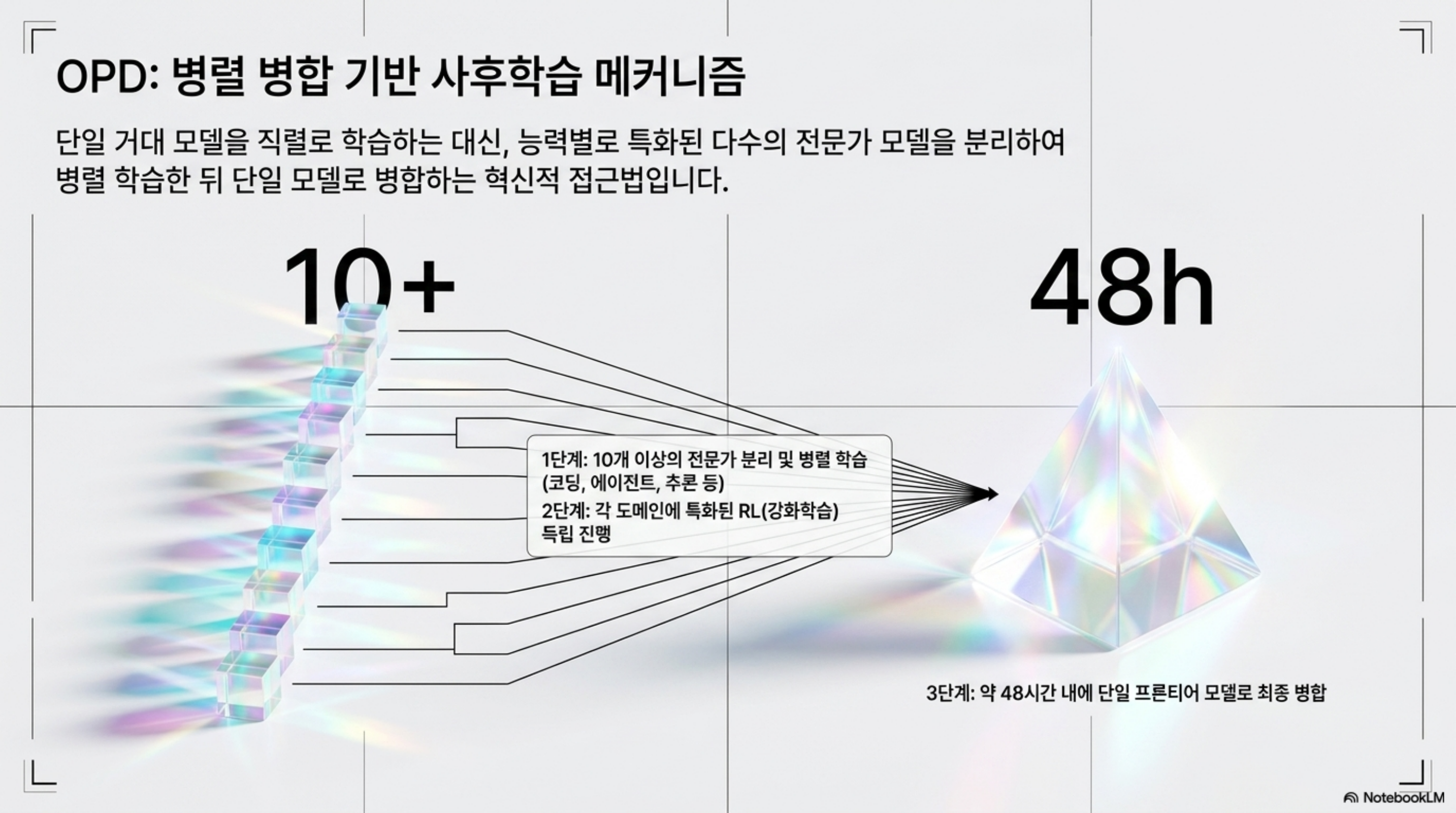
OPD는 GLM-5.2 사후학습 단계에서 쓰인 병렬 학습 및 병합 방식입니다. 핵심 아이디어는 단순하지만 인프라적으로는 까다롭습니다. 하나의 거대한 모델을 모든 능력에 대해 한 번에 RL로 학습하는 대신, 능력별로 여러 전문가 모델을 따로 RL 학습한 뒤 이들을 하나의 최종 모델로 합치는 것입니다.
Z.ai의 보고에 따르면 GLM-5.2 사후학습에서 slime을 사용해 병렬 OPD 학습을 수행했고, 10개가 넘는 전문가 모델을 최종 모델로 병합했으며, 전체 OPD 과정은 약 이틀이 걸렸습니다. 여기서 두 가지 숫자가 의미심장합니다. 전문가 모델이 10개 이상이라는 것은 코딩, 에이전트, 추론 같은 능력을 분리해 각각 RL로 끌어올렸다는 뜻입니다. 그리고 약 이틀이라는 시간은, 그 많은 전문가를 따로 학습하고 합치는 일이 비현실적으로 길지 않게 돌아갔다는 뜻입니다. (OPD 약어의 정확한 풀이는 공식 자료에서 명시적으로 확인되지 않아 여기서는 단정하지 않겠습니다. 검증된 사실은 “병렬 전문가 학습 후 병합”이라는 동작과 위 수치입니다.)
이 접근이 가지는 실무적 장점은 분명합니다.
- 병렬화: 능력별 전문가를 독립적으로 학습하면 작업이 분산됩니다. 한 거대 모델을 직렬로 모든 도메인에 대해 RL 학습하는 것보다 GPU 풀을 넓게 쓸 수 있습니다.
- 격리된 보상 설계: 코딩과 추론은 보상 신호가 다릅니다. 전문가별로 분리하면 도메인에 맞는 보상과 검증기를 따로 둘 수 있어 보상 해킹의 영향이 한 전문가 안에 갇힙니다.
- 반복 속도: 한 도메인의 데이터나 보상을 고칠 때 전체를 다시 돌릴 필요가 없습니다. 해당 전문가만 다시 학습하고 병합 단계만 갱신하면 됩니다.
물론 어려움도 같이 옵니다. 여러 전문가를 하나로 합칠 때 능력이 서로 간섭하거나 상쇄되는 문제가 생길 수 있습니다. 병합이 단순 가중치 평균이 아니라 별도의 학습 과정을 포함한다면, 그 병합 자체가 또 하나의 사후학습 단계가 됩니다. Z.ai가 “병렬 OPD 학습”이라고 표현한 이유도 병합이 단순 산술 평균을 넘는 과정이기 때문으로 보입니다.
slime: OPD를 떠받치는 오픈소스 RL 인프라
OPD를 가능하게 한 토대가 slime입니다. slime은 RL 스케일링을 위한 LLM 사후학습 프레임워크이며 Apache-2.0으로 공개돼 있습니다. 구조는 세 부분으로 나뉩니다.
- 학습(Megatron): 정책 학습 루프를 담당하며 데이터 버퍼에서 데이터를 읽습니다.
- 롤아웃(SGLang + 라우터): 새 데이터를 생성해 버퍼에 다시 저장합니다.
- Data Buffer: 프롬프트 초기화와 커스텀 데이터 생성 워크플로를 관리합니다.
slime이 강조하는 설계 원칙은 비동기와 디커플링입니다. Megatron 학습, SGLang 롤아웃, 커스텀 데이터 생성, 보상 계산, 검증기 피드백, 환경 상호작용이 모두 같은 학습 및 롤아웃 경로를 따라 흐릅니다. RL 사후학습이 인프라적으로 어려운 이유가 바로 추론(롤아웃)과 학습(업데이트)이 한 루프에서 교대로 돌기 때문인데, slime은 이 둘을 분리해 각자의 자원 프로파일에 맞게 스케줄링하도록 설계됐습니다.
지원 모델 범위도 넓습니다. Qwen 계열(Qwen3.6, Qwen3.5, Qwen3Next, Qwen3MoE, Qwen3, Qwen2.5), DeepSeek V3 계열(V3, V3.1, R1), Llama 3를 지원합니다. GLM 4.5부터 5.2까지 실제 프론티어 모델 학습에 쓰였다는 점에서 검증된 코드라는 신뢰가 따라옵니다.
설치는 표준 파이썬 패키지 방식을 따릅니다. 저장소에 requirements.txt, setup.py, pyproject.toml이 포함돼 있고 /docker 디렉터리로 컨테이너 환경도 제공합니다. 다만 실제 RL 사후학습을 돌리려면 다수의 GPU가 필요하므로, 이 글에서는 직접 학습을 재현하지 않고 공개된 사실과 구조를 분석하는 데 집중했습니다. 단일 워크스테이션에서 수치를 만들어 붙이는 것은 사실 왜곡이 되므로 하지 않았습니다.
전체 RL 스택이 오픈된다는 것의 의미

가중치 공개와 학습 인프라 공개는 무게가 다릅니다. 가중치만 있으면 추론은 할 수 있지만, 그 모델을 우리 도메인에 맞게 다시 RL로 사후학습하는 길은 막혀 있습니다. 반대로 학습 인프라가 함께 열리면 다음이 가능해집니다.
- 재현 가능성: 보고된 사후학습 절차를 코드 수준에서 따라갈 수 있습니다. 논문 그림이 아니라 실행 가능한 파이프라인이 손에 들어옵니다.
- 도메인 적응: 공개된 RL 스택 위에서 우리 데이터와 우리 보상으로 전문가를 학습하고 병합할 수 있습니다. OPD식 능력별 분리 학습을 자체 도메인에 적용할 여지가 생깁니다.
- 비용 통제: 외부 API에 학습을 맡기지 않고 온프레미스에서 사후학습을 돌릴 수 있습니다. 데이터가 외부로 나가지 않으므로 규제 대응에도 유리합니다.
핵심은 “프론티어 모델을 어떻게 만드는가”가 더 이상 폐쇄된 노하우가 아니라 공개된 엔지니어링이 됐다는 점입니다. 이는 자체 인프라로 모델을 다듬으려는 조직에게 진입 장벽을 크게 낮춥니다.
ThakiCloud K8s AI/ML SaaS 플랫폼 적용 및 시사점
OPD와 slime이 보여주는 그림은 저희가 K8s 위에서 다루는 학습 인프라 문제와 정확히 겹칩니다.
첫 번째는 GPU 오케스트레이션입니다. OPD처럼 10개 이상의 전문가를 병렬로 학습하려면 여러 학습 잡을 동시에 스케줄링하고, 각 잡 안에서 롤아웃(추론)과 정책 업데이트(학습)라는 성격이 다른 워크로드를 같은 GPU 풀에 배치해야 합니다. ThakiCloud는 Kueue로 GPU 잡 큐잉과 쿼터를 관리하므로, 전문가별 학습을 독립 잡으로 띄우고 우선순위와 자원 상한을 부여하는 구조가 자연스럽게 맞아떨어집니다. slime의 비동기 디커플링 설계는 롤아웃 파드와 학습 파드를 따로 스케일링하는 K8s 패턴으로 옮기기 좋습니다.
두 번째는 멀티테넌트 사후학습입니다. 저희 플랫폼은 여러 고객 환경에서 워크로드를 운용합니다. OPD의 전문가 분리 학습은 테넌트별, 도메인별로 전문가를 따로 학습한 뒤 병합하는 워크플로와 개념이 닮았습니다. 고객 데이터가 섞이지 않도록 전문가 학습을 격리하고, 병합 단계만 통제된 환경에서 수행하는 식의 설계를 검토할 수 있습니다.
세 번째는 온프레미스 경제성입니다. 사후학습 스택이 오픈소스이고 대상 모델이 MIT 라이선스라면, 외부 학습 서비스 없이 온프레미스에서 도메인 특화 모델을 다듬는 경로가 열립니다. 데이터 외부 반출이 어려운 고객, 비용을 통제해야 하는 고객, 자체 보안 요구가 강한 고객에게 이는 곧 제품 경쟁력이 됩니다. 저희가 강조해 온 self-hosting과 비용 효율이라는 방향과 같은 선상에 있습니다.
당장 OPD 전체를 재현하는 것은 다수 GPU가 필요해 무거운 작업입니다. 다만 slime 기반의 소규모 RL 사후학습을 Kueue 잡으로 띄워 파이프라인을 검증하고, 여기서 얻은 운용 패턴을 점진적으로 확장하는 접근은 현실적인 로드맵입니다.
한계 및 반론

균형을 위해 약점도 짚겠습니다.
가장 큰 제약은 검증의 한계입니다. 전문가 10개 이상, 약 이틀이라는 수치는 Z.ai의 자체 보고이며 외부에서 독립적으로 재현된 결과가 아닙니다. OPD 약어의 정확한 정의와 병합 알고리즘의 세부도 공개 자료만으로는 완전히 드러나지 않습니다. 따라서 이 글의 분석은 공개된 동작과 수치를 근거로 한 해석이며, 내부 메커니즘에 대한 단정은 피했습니다.
규모의 벽도 분명합니다. 인프라가 오픈됐다고 해서 누구나 753B 모델을 사후학습할 수 있는 것은 아닙니다. 전문가 병렬 학습과 병합에는 상당한 GPU와 데이터, 보상 설계 역량이 필요합니다. 오픈소스는 진입 장벽을 낮추지만 자원 장벽을 없애지는 못합니다.
병합 자체의 위험도 있습니다. 능력별 전문가를 합칠 때 한 능력이 다른 능력을 침식할 수 있고, 벤치마크 점수가 실제 사용성과 어긋날 수 있습니다. 여러 전문가를 합친 모델이 특정 조합에서 예측하기 어려운 거동을 보일 가능성도 배제할 수 없습니다.
그럼에도 방향성은 분명합니다. 프론티어 모델의 학습 절차가 실행 가능한 형태로 공개되는 흐름은, 자체 인프라로 모델을 운용하려는 조직에게 실질적인 선택지를 넓혀 줍니다. 저희처럼 K8s 위에서 학습과 서빙을 함께 다루는 플랫폼에게는 특히 그렇습니다.
