DiffusionGemma 26B-A4B: 이산 텍스트 확산으로 15~20 토큰을 한 번에 생성하는 Google의 실험
⏱️ 예상 읽기 시간: 9분
무엇이 새로운가
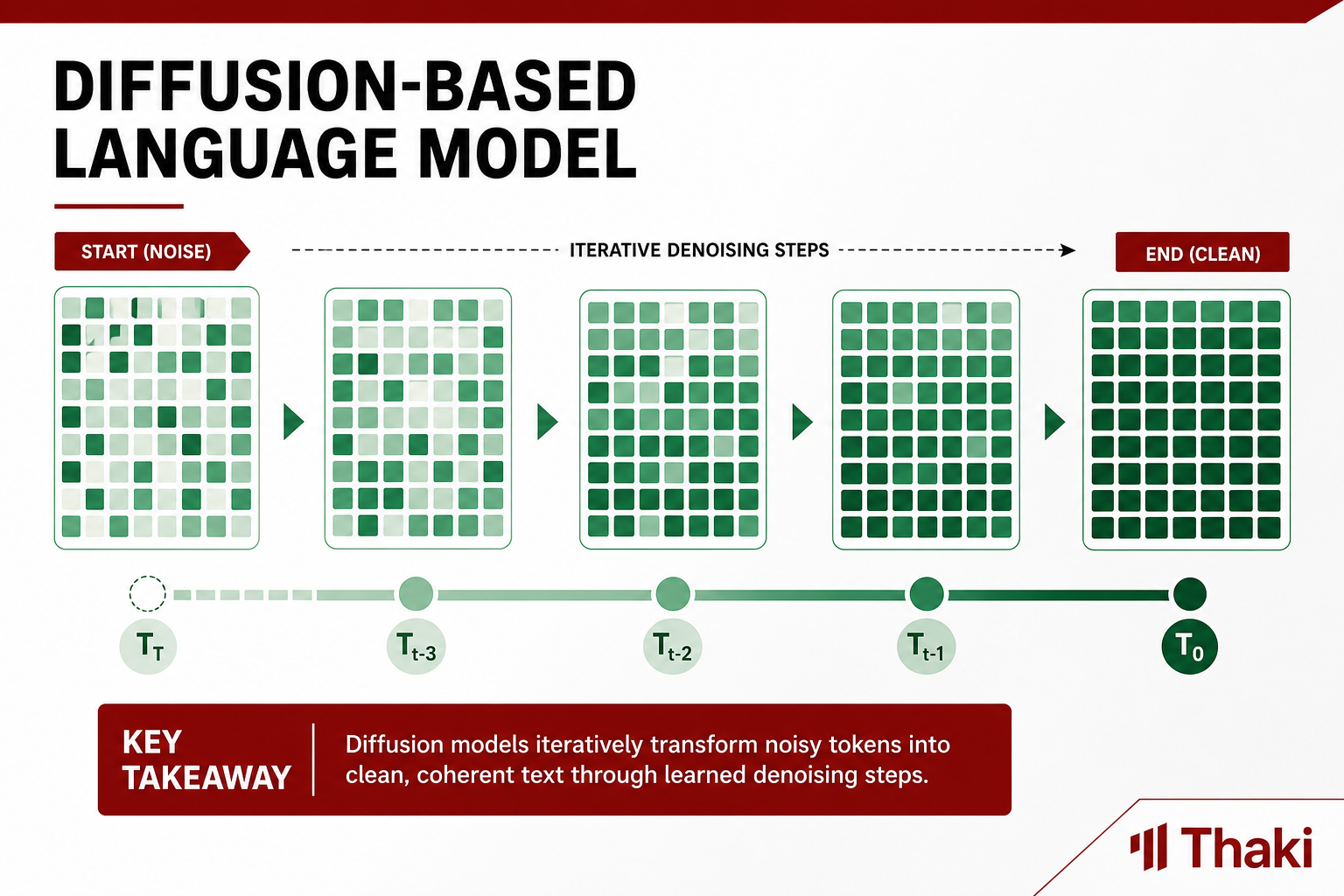
Google DeepMind가 google/diffusiongemma-26B-A4B-it를 공개했습니다. 이름에서 드러나듯 Gemma 아키텍처를 기반으로 하되, 텍스트 생성 방식이 근본적으로 다릅니다. 기존 언어 모델은 토큰을 왼쪽에서 오른쪽으로 하나씩 예측하는 autoregressive 방식을 씁니다. DiffusionGemma는 그 대신 이산 텍스트 확산(discrete text diffusion)을 씁니다. 노이즈가 섞인 시퀀스를 반복적으로 정제해 최종 텍스트를 얻는 방식입니다.
실제 생성 속도로 보면 한 번의 forward pass에서 15~20개 토큰을 동시에 생성합니다. H100 FP8 저배치 조건에서 1,100 tokens/sec를 넘는다고 모델 카드에 기재되어 있습니다. 이 수치는 Google이 측정한 값이며 하드웨어 구성과 배치 크기에 따라 달라집니다.
라이선스는 Apache-2.0입니다. 상업적 사용과 파생 모델 배포가 가능한 표준 오픈소스 라이선스입니다.
아키텍처
파라미터 구성은 다음과 같습니다.
- 총 파라미터: 25.2B
- 활성 파라미터: 3.8B
- 레이어: 30
- 전문가: 128 total, 8 active + 1 shared
- 어휘 크기: 262,144
- 비전 인코더: 약 550M 파라미터
- 슬라이딩 윈도우: 1,024 토큰
- 캔버스 길이: 256
- 컨텍스트: 최대 256K 토큰
구조적으로 인코더-디코더이고 양방향 어텐션을 씁니다. 표준 causal language model의 단방향 어텐션과 달리 전체 시퀀스를 동시에 볼 수 있습니다. 이것이 이산 확산과 결합해 한 번의 패스에서 복수 토큰을 생성할 수 있는 기반입니다.
텍스트 외에 이미지와 비디오를 입력으로 받습니다. 이미지는 가변 해상도와 종횡비를 지원합니다.
지원 언어는 140개 이상의 언어로 훈련되었고 35개 이상의 언어를 지원한다고 명시되어 있습니다. 훈련 데이터 기준 날짜는 2025년 1월입니다.
벤치마크
모델 카드에 기재된 수치는 instruction-tuned 버전, Entropy Bound sampler 기준입니다.
| 벤치마크 | 점수 |
|---|---|
| MMLU Pro | 77.6% |
| AIME 2026 (도구 없음) | 69.1% |
| LiveCodeBench v6 | 69.1% |
| GPQA Diamond | 73.2% |
| BigBench Extra Hard | 47.6% |
| MMMU Pro (비전) | 54.3% |
| MATH-Vision | 70.5% |
AIME 2026 69.1%와 GPQA Diamond 73.2%는 수학 추론과 과학 문제 풀이에서 상당한 수준입니다. 활성 파라미터 3.8B라는 점을 감안하면 흥미로운 수치이지만, 벤치마크는 항상 특정 조건의 스냅샷임을 기억해야 합니다.
확산 생성의 K8s 배포 특이점
autoregressive 모델과 다른 생성 방식은 서빙 인프라에도 영향을 줍니다.
KV 캐시 패턴이 다릅니다. autoregressive 모델은 생성된 토큰의 KV를 순차적으로 캐시해 다음 토큰 예측에 씁니다. 이산 확산은 전체 시퀀스를 반복 정제하므로 표준 KV 캐시 메커니즘이 그대로 적용되지 않을 수 있습니다. vLLM이나 SGLang의 PagedAttention 최적화가 어떻게 동작하는지 실제 테스트로 확인해야 합니다.
배치 처리 특성이 다릅니다. autoregressive 모델에서 배치 내 다른 시퀀스 길이는 padding이나 continuous batching으로 처리합니다. 확산 모델은 반복 횟수(diffusion steps)와 캔버스 길이 조합에 따라 처리 시간이 달라집니다. 요청별 처리 시간 편차가 표준 AR 모델과 다른 패턴을 보일 수 있습니다.
추론 메모리. 총 25.2B BF16 기준 약 50.4GB VRAM이 필요합니다. 비전 인코더 550M를 포함해도 A100 80GB 1장 또는 H100 80GB 1장에 들어갑니다. 활성 파라미터 3.8B 기반 설계이므로 throughput 관점에서는 dense 25B보다 유리합니다.
공식 지원 프레임워크는 Transformers, vLLM, SGLang, Docker Model Runner입니다. 양자화 변형이 26종 공개되어 있습니다.
# vLLM 서빙 예시
vllm serve google/diffusiongemma-26B-A4B-it \
--dtype bfloat16 \
--max-model-len 32768
이산 확산 모델 특성상 vLLM 버전 호환성을 먼저 확인해야 합니다. 표준 AR 모델용으로 최적화된 일부 기능이 동작하지 않을 수 있습니다.
thinking 모드를 설정 가능하며 system prompt와 function calling을 네이티브로 지원합니다.
ThakiCloud 관점
확산 LLM 추론 패러다임 실험 환경. DiffusionGemma는 현재 프로덕션 워크로드보다는 추론 패러다임 연구와 실험에 더 적합합니다. ThakiCloud 플랫폼에서 격리된 실험용 Kueue WorkloadClass를 만들어 확산 모델의 실제 throughput과 품질을 autoregressive 모델과 나란히 비교 측정하는 용도로 쓸 수 있습니다. 이산 확산이 특정 태스크 유형에서 AR 대비 어떤 차이를 보이는지 데이터를 모으는 것이 먼저입니다.
256K 컨텍스트와 멀티모달. 256K 컨텍스트와 이미지/비디오 입력 지원은 장문서 이해나 긴 코드베이스 분석 태스크에 활용 가능합니다. Apache-2.0 라이선스라 상업적 활용과 파생 모델 개발에 제약이 없는 점도 온프렘 통합 시 유리합니다.
확산 LLM은 아직 생태계가 autoregressive 모델만큼 성숙하지 않습니다. 서빙 프레임워크의 확산 모델 지원 현황, 양자화 효과, 실제 배포 안정성을 직접 검증하는 단계가 필요합니다.