NVIDIA Nemotron-3-Ultra-550B: LatentMoE 하이브리드, 1M 컨텍스트, 한국어 지원 온프렘 분석
⏱️ 예상 읽기 시간: 8분
Nemotron-3-Ultra-550B 개요
NVIDIA가 2026년 6월 4일 공개한 nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16은 총 550B 파라미터, active 55B인 MoE 계열 모델이다. 라이선스는 OpenMDW-1.1이다.
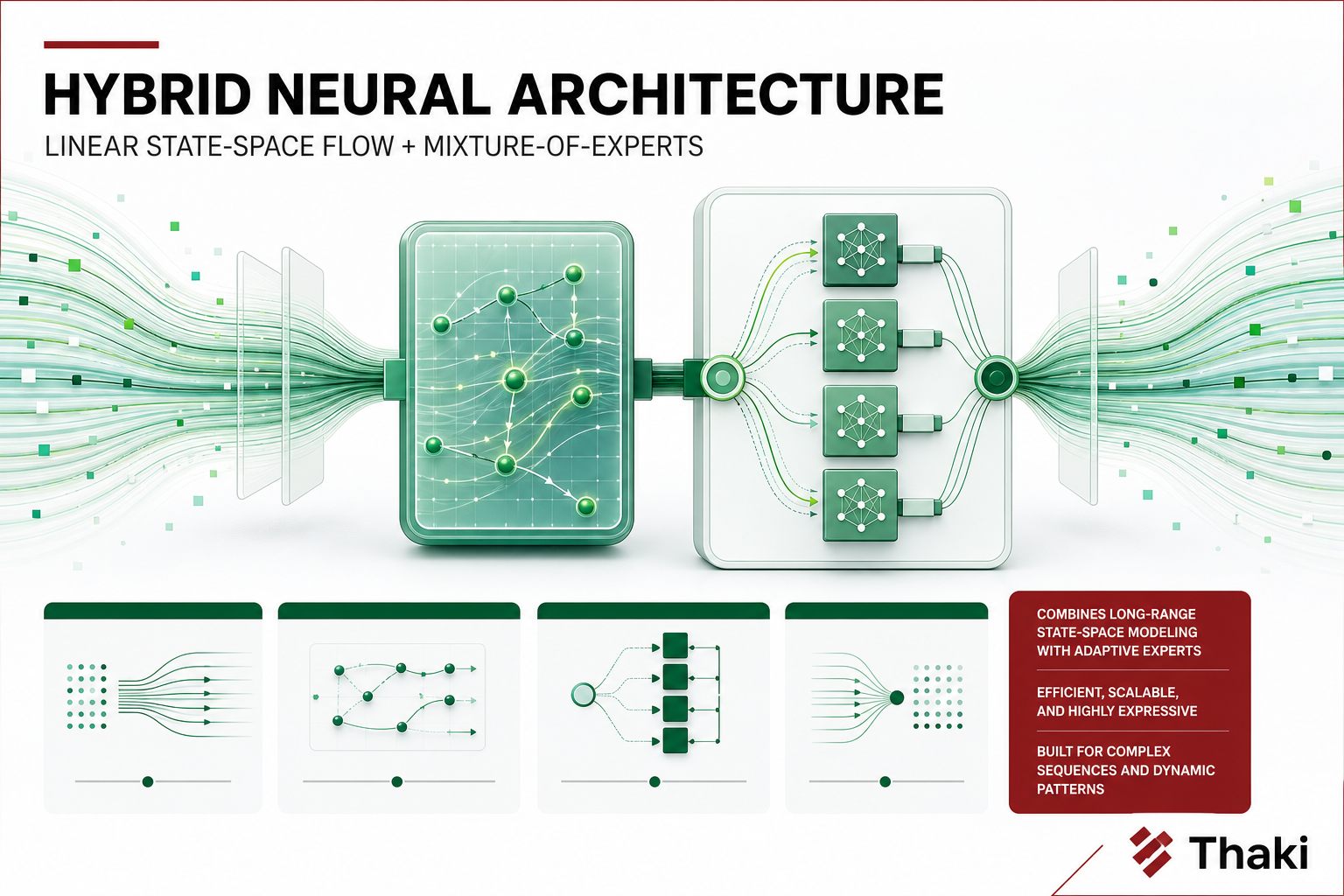
이 모델의 가장 큰 특징은 아키텍처 혼합 방식이다. Mamba-2 기반 SSM, MoE, 표준 Attention을 결합한 LatentMoE 하이브리드이며, MTP(Multi-Token Prediction) speculative decoding도 통합됐다. 1M 토큰 컨텍스트를 지원한다.
LatentMoE 하이브리드 아키텍처
Mamba-2 + MoE + Attention 결합
기존 트랜스포머 기반 LLM은 어텐션의 $O(L^2)$ 복잡도가 긴 컨텍스트에서 병목이 된다. SSM(State Space Model) 계열, 특히 Mamba 아키텍처는 선형 복잡도($O(L)$)로 이 문제를 다른 방식으로 접근한다. Mamba-2는 이를 구조화된 상태공간 행렬로 개선한 버전이다.
Nemotron-3-Ultra는 Mamba-2 레이어와 표준 Attention 레이어를 혼합하고, 여기에 MoE를 결합한다. 이론적으로는 짧은 시퀀스에서 Attention의 정확한 패턴 포착 능력을 쓰고, 긴 시퀀스로 갈수록 SSM의 선형 복잡도 이점이 작동하는 구조다.
중요한 점은 이 조합이 실제 1M 컨텍스트 서빙에서 어떻게 작동하는지에 대한 실측 데이터가 아직 많지 않다는 것이다. VRAM 요구사항이나 긴 컨텍스트에서의 실제 throughput은 직접 테스트 전까지는 불확실한 부분이 있다.
학습 규모
약 20조 토큰으로 사전학습했으며 컷오프는 2025년 9월이다. 코퍼스 크기는 53.8TiB, 226개 데이터셋을 활용했다. 사후학습 컷오프는 2026년 5월이다. BF16이 기본이고 일부 NVFP4 프리트레인 레시피도 공개됐다.
추론 모드
chat template으로 추론(Thinking) 모드와 일반 응답 모드를 전환할 수 있다. tool calling과 구조화된 출력(JSON schema 등)도 지원한다.
언어 지원
영어, 프랑스어, 스페인어, 이탈리아어, 독일어, 일본어, 힌디어, 한국어, 포르투갈어(브라질), 중국어 총 10개 언어를 공식 지원한다. 한국어 포함이 명시적이다.
벤치마크
HF 모델카드 기준 수치다.
| 벤치마크 | Nemotron-3-Ultra |
|---|---|
| SWE-Bench Verified | 70.7% |
| MMLU-Pro | 86.8% |
| IOI 2025 | 570.0 |
| LiveCodeBench v6 | 89.0% |
| GPQA (no tools) | 87.0% |
SWE-Bench Verified 70.7%는 소프트웨어 엔지니어링 태스크에서 강한 성능이다. MMLU-Pro 86.8%는 지식 기반 멀티도메인 QA에서의 수치로 높은 편이다. IOI 2025 570.0은 국제정보올림피아드 문제 집합에서의 점수다. GPQA 87.0%는 대학원급 과학 질문 답변에서의 성능이다.
서빙 및 배포
최소 하드웨어 요구사항
공식 문서 기준 단일 노드 최소 요건은 B200 또는 GB200 8장이다. 이는 DGX B200 또는 GB200 시스템에 해당한다. 멀티노드 구성에서는 H100, H200, GB200, GB300 8장 이상과 Ray 오케스트레이션이 필요하다. 기존 A100 클러스터에서의 공식 지원 경로는 현재 모델카드에 명시되어 있지 않다.
이 요구사항은 이번에 다루는 4개 모델 중 가장 높은 진입 장벽이다.
지원 프레임워크
- vLLM v0.22.0 이상 (TP/EP 지원, MTP speculative decoding 5토큰)
- SGLang v0.5.12.post1 이상 (chunked prefill, EAGLE)
- TensorRT-LLM 1.3.0rc17 (Blackwell 전용)
- 커뮤니티 GGUF, GPTQ 변형
FP8 KV-cache와 NVFP4 변형도 지원된다. TensorRT-LLM 경로는 현재 Blackwell 아키텍처(B200/GB200)에 최적화되어 있다.
배포 모드
MTP speculative decoding을 vLLM에서 5토큰 단위로 쓸 수 있어서 throughput 향상이 기대된다. chunked prefill은 긴 컨텍스트 프리필 시 메모리 피크를 낮추는 데 효과적이다.
ThakiCloud 관점
이 모델을 온프렘에서 검토할 때 세 가지를 먼저 짚어봐야 한다.
LatentMoE 하이브리드의 이론적 이점과 실측 불확실성. Mamba-2와 Attention을 결합한 아키텍처는 긴 컨텍스트에서 SSM의 선형 복잡도 이점을 결합한다는 이론적 근거가 있다. 그러나 1M 컨텍스트에서의 실제 VRAM 사용량과 throughput은 직접 측정 전까지 불확실한 부분이 남는다. 신규 아키텍처이고 실무 데이터가 아직 희소하다. 온프렘 도입 검토 시 벤더 수치만 보지 말고 자체 환경에서 실측하는 단계를 빼면 안 된다.
단일노드 최소 B200 8장, 사실상 DGX B200 전용. H100 클러스터를 보유한 조직이 지금 당장 이 모델을 최적 성능으로 올리기는 어렵다. 멀티노드 H100 구성은 가능하지만 Ray 오케스트레이션과 추가 네트워크 대역폭이 필요하다. B200/GB200로의 전환을 고려 중인 조직에게는 검토 대상이 되지만, 현재 인프라가 A100이라면 커뮤니티 GGUF 경로로 기능 평가 수준에 머무는 것이 현실적이다.
한국어 공식 지원이 국내 엔터프라이즈 온프렘 근거가 된다. 한국어가 10개 공식 지원 언어 중 하나로 명시된 것은 중요하다. 많은 대형 모델이 한국어를 지원한다고 하지만 공식 평가 언어에 포함되는 경우는 드물다. 금융, 공공, 의료 등 한국어 문서 처리가 핵심인 엔터프라이즈 온프렘 도입의 근거 자료로 쓸 수 있다. 다만 한국어 벤치마크 수치가 별도로 제시되지 않아서, 실제 한국어 성능 검증은 자체 평가 세트로 진행해야 한다.
OpenMDW-1.1 라이선스는 NVIDIA가 설계한 오픈 모델 라이선스다. 상용 온프렘 배포 전 라이선스 원문 검토는 필수다.