NVIDIA ASPIRE: 로봇이 실패를 스킬로 바꾸는 에이전트형 스킬 발견

개요
로봇을 오래 굴려 본 사람은 익숙한 낭비를 봅니다. 로봇이 어떤 과제를 힘들게 성공시켜도, 그 과정에서 얻은 시행착오는 대부분 버려집니다. 다음 과제에서는 또 처음부터 더듬습니다. 실패를 딛고 만든 미세한 노하우, 이를테면 그리퍼가 미끄러졌을 때의 복구 방법이나 특정 물체를 다룰 때의 접근 각도 같은 것들이 시스템 어디에도 남지 않습니다. 사람이라면 한 번 배운 요령을 다음에 다시 쓰는데, 로봇은 그러지 못합니다.

NVIDIA GEAR 연구진이 2026년 6월 30일 공개한 ASPIRE(Agentic /Skills Discovery for Robotics, arXiv 2607.00272)는 정확히 이 지점을 겨냥합니다. ASPIRE의 발상은 단순하지만 강력합니다. 로봇에게 미리 정해진 정책을 주입하는 대신, 대형 언어 모델(LLM)이 로봇 제어 코드를 직접 작성하고, 그 코드를 실제 실행 환경에서 돌려 실패를 관찰하며, 반복적으로 수리한 뒤, 검증된 수리 경험을 재사용 가능한 스킬(Skill) 로 증류합니다. 경험이 버려지지 않고 복리처럼 쌓입니다.
이 글은 검증된 논문과 프로젝트 페이지를 근거로 ASPIRE의 구조와 실측 결과를 정리합니다. 그리고 이 흐름이 로봇공학만의 이야기가 아니라 소프트웨어 에이전트에도 그대로 적용된다는 점, 특히 ThakiCloud의 Agent-Native Cloud인 Paxis가 스킬을 일급 리소스로 다루는 방식과 어떻게 맞닿는지를 마지막에 짚습니다.
ASPIRE는 무엇인가
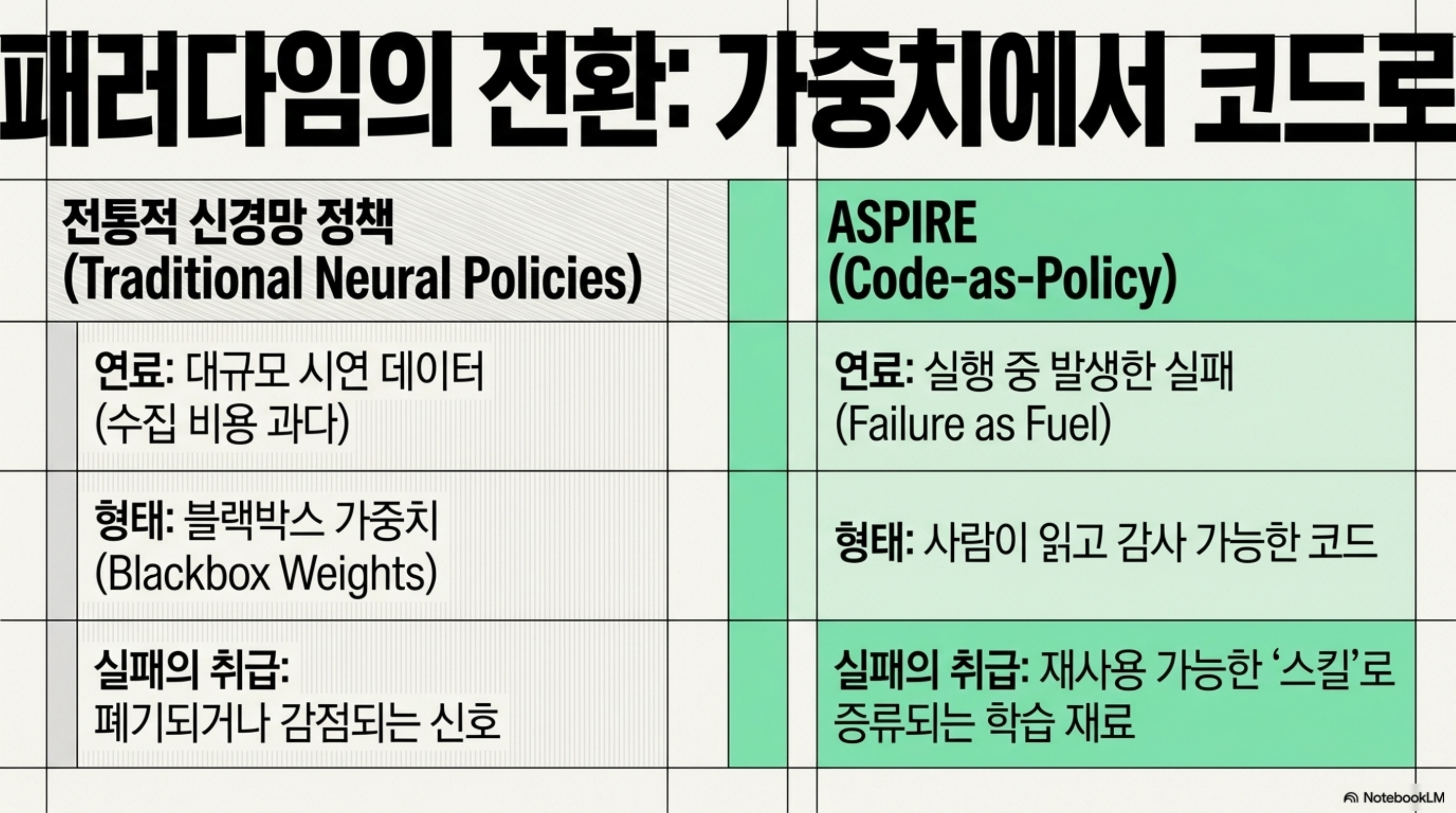
ASPIRE는 code-as-policy 패러다임 위에 지속 학습(continual learning) 루프를 얹은 시스템입니다. 전통적인 로봇 학습은 대량의 시연 데이터로 신경 정책을 훈련하고, 새 상황을 만나면 다시 데이터를 모아 재훈련하는 방식이 많았습니다. 여기에는 두 가지 부담이 따릅니다. 데이터 수집 비용이 크고, 한 번 학습한 지식이 새로운 변형 앞에서 쉽게 무너집니다.
ASPIRE는 정책을 신경망 가중치가 아니라 실행 가능한 코드로 표현합니다. LLM이 과제를 받아 제어 프로그램을 작성하면, 그 프로그램이 시뮬레이션 또는 실제 로봇에서 실행됩니다. 실행이 실패하면 ASPIRE는 실행 궤적을 기록하고, 실패 원인을 분석하며, 프로그램을 고쳐 다시 시도합니다. 이 반복이 성공에 도달하면, 그 과정에서 검증된 수리 지식이 스킬 라이브러리에 저장됩니다. 다음 과제는 빈손이 아니라 이 라이브러리를 참조해 시작합니다.
flowchart TB
A[과제 지시] --> B[LLM이 제어 코드 작성<br/>code-as-policy]
B --> C[실제 실행<br/>시뮬레이션 또는 로봇]
C --> D{성공 여부}
D -- 실패 --> E[궤적 기록·실패 원인 분석]
E --> F[프로그램 수리]
F --> C
D -- 성공 --> G[검증된 수리 경험 증류]
G --> H[재사용 가능한 스킬 라이브러리]
H -.다음 과제가 참조.-> B
핵심은 마지막 화살표입니다. 스킬 라이브러리가 다음 과제 작성의 입력으로 되돌아가면서, 시스템은 시간이 지날수록 더 나은 코드를 더 빨리 씁니다. 논문은 이렇게 쌓인 지식이 그리퍼 복구 휴리스틱, 내비게이션 전략, 프롬프트 레시피, 절차적 수정 같은 형태로 과제를 넘나들며 전이(transfer) 된다고 설명합니다. 특정 과제 하나를 잘 푸는 것이 아니라, 푸는 능력 자체가 축적됩니다.
실패를 스킬로 증류하는 루프
ASPIRE를 다른 로봇 학습과 구분하는 지점은 실패를 다루는 방식입니다. 대부분의 파이프라인에서 실패는 폐기 대상이거나, 기껏해야 보상 신호를 깎는 음의 신호입니다. ASPIRE는 실패를 학습 재료로 봅니다. 실패한 실행의 궤적에는 “무엇이 왜 어긋났는가”라는 정보가 들어 있고, LLM은 이 정보를 읽어 코드를 어디서 어떻게 고쳐야 하는지 추론합니다.
이 수리가 한 번의 임기응변으로 끝나면 의미가 제한적입니다. ASPIRE의 기여는 검증된 수리를 일반화 가능한 스킬로 증류하는 데 있습니다. 예를 들어 특정 물체를 집다가 미끄러진 실패를 고쳐 성공했다면, 그 복구 절차는 그 물체에만 묶이지 않고 유사한 파지 상황에 재적용될 수 있는 형태로 추상화됩니다. 스킬은 텍스트로 표현된 코드 조각이므로 사람이 읽고 감사할 수 있고, 라이브러리로 관리하며 버전을 매길 수 있습니다. 이는 블랙박스 신경 정책과 대비되는 큰 장점입니다.
이 구조 덕분에 ASPIRE는 추가 학습 데이터 없이 성능을 끌어올립니다. 새 시연을 수집해 모델을 재훈련하는 대신, 실행-실패-수리-증류 루프를 반복하는 것만으로 성공률이 오릅니다. 데이터 수집이 병목인 로봇공학에서 이는 실무적으로 중요한 성질입니다.
실제 실험 결과
논문과 프로젝트 페이지가 보고한 수치는 이 루프가 단순한 개념 이상임을 보여 줍니다. 가장 인상적인 결과는 Robosuite의 양팔 물체 핸드오버(bimanual object handover) 과제입니다. 기본 성공률 20%에서 시작해, 반복적 디버깅만으로 92%까지 올랐습니다. 추가 시연 데이터를 전혀 넣지 않고, 실행-수리 루프만으로 도달한 수치입니다.
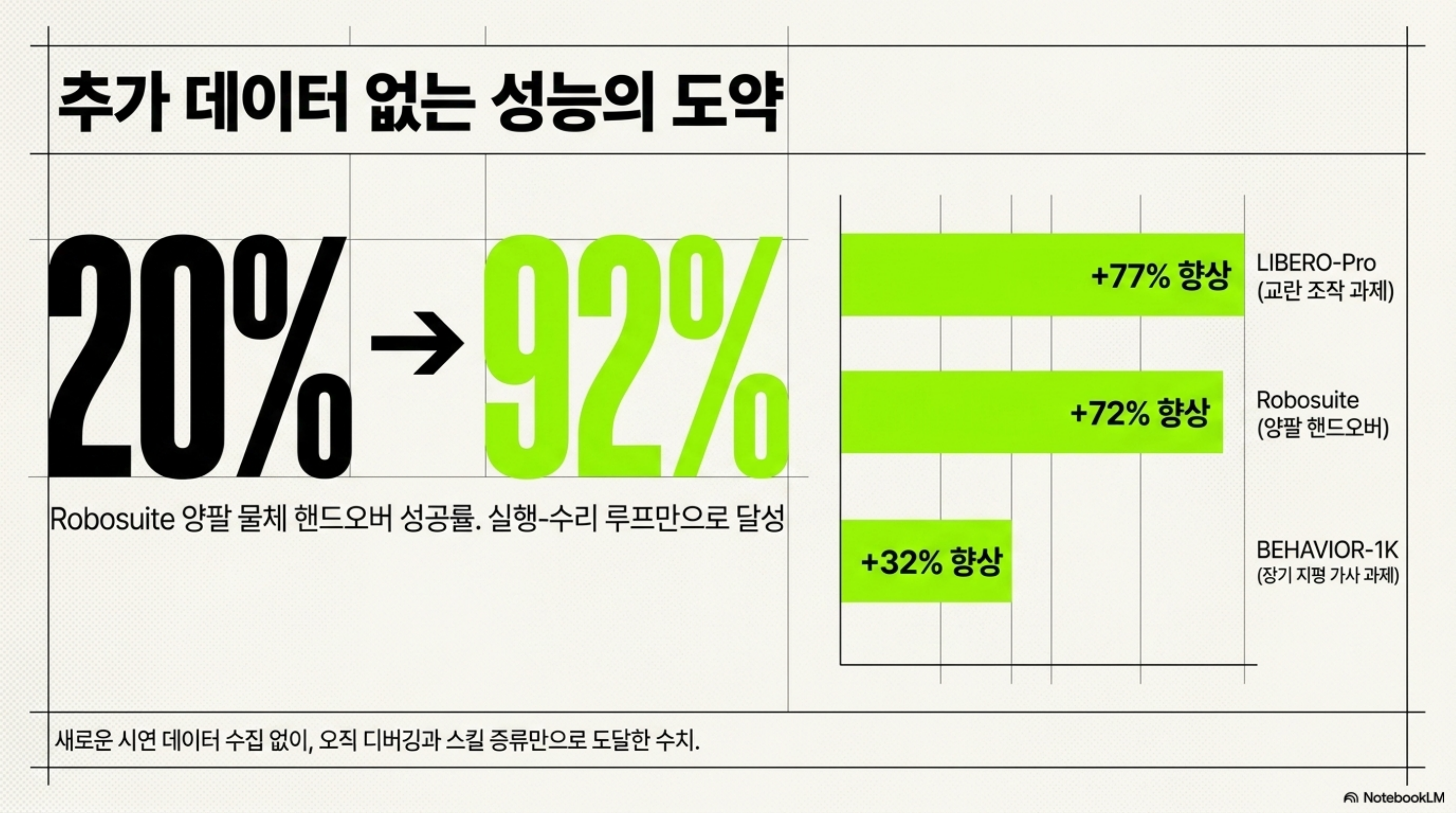
과제 유형을 넓혀도 이점이 유지됩니다. 논문은 ASPIRE가 선행 방법 대비 다음과 같은 향상을 보였다고 보고합니다. 교란(perturbation)이 가해진 조작 과제인 LIBERO-Pro에서 최대 77%, Robosuite 양팔 핸드오버에서 72%, 장기 지평(long-horizon) 가사 과제인 BEHAVIOR-1K에서 최대 32%의 성능 우위입니다. 특히 장기 과제 일반화 실험에서는 스킬 라이브러리가 커질수록 성공률이 꾸준히 올랐다고 합니다. 라이브러리의 성장과 성능의 상승이 함께 간다는 점은, 경험이 실제로 복리로 쌓인다는 이 시스템의 핵심 주장을 뒷받침합니다.
연구진은 NVIDIA GEAR 연구실을 중심으로 미시간대(UMich), 일리노이대(UIUC), UC 버클리, 카네기멜런대(CMU) 소속 연구자들로 구성됩니다. NVIDIA는 릴리스 시점에 ASPIRE의 스킬 라이브러리를 오픈소스로 공개한다고 밝혔으며, 상세는 프로젝트 페이지(research.nvidia.com/labs/gear/aspire)에서 확인할 수 있습니다. 다만 코드 저장소의 구체적 라이선스는 공개 시점 기준으로 명시가 확인되지 않아, 도입 전에는 실제 저장소의 라이선스 조항을 직접 확인하는 편이 안전합니다.
ThakiCloud 제품 적용 시사점
ASPIRE의 대상은 로봇 팔이지만, 그 아키텍처가 던지는 메시지는 소프트웨어 에이전트에 그대로 옮겨집니다. “에이전트가 코드를 쓰고, 실패에서 배우며, 검증된 경험을 재사용 가능한 스킬로 증류해 라이브러리에 쌓는다”는 문장에서 ‘로봇’을 ‘클라우드 에이전트’로 바꾸면, 그것이 바로 ThakiCloud의 Agent-Native Cloud인 Paxis가 지향하는 구조입니다.
Paxis는 Skills·Tools·Policies·Audit Logs를 일급 리소스로 다룹니다. ASPIRE의 스킬 라이브러리가 Paxis에서는 BM25로 선택되는 960여 개의 스킬 하니스에 해당하고, ASPIRE의 code-as-policy 실행은 Paxis의 격리 샌드박스 실행에 대응합니다. ASPIRE가 실패 궤적을 기록하고 분석하듯, Paxis는 모든 에이전트 행동을 정책 게이트와 감사 로그로 통과시켜 무엇이 왜 실패했는지 소급 추적할 수 있게 합니다. 그리고 ASPIRE의 증류 루프가 지향하는 자기 개선은 Paxis의 자가진화 스킬로 구현됩니다. 실행에서 얻은 교훈이 새 스킬이나 스킬 개정으로 되돌아가, 다음 실행이 빈손에서 시작하지 않게 만드는 흐름입니다.

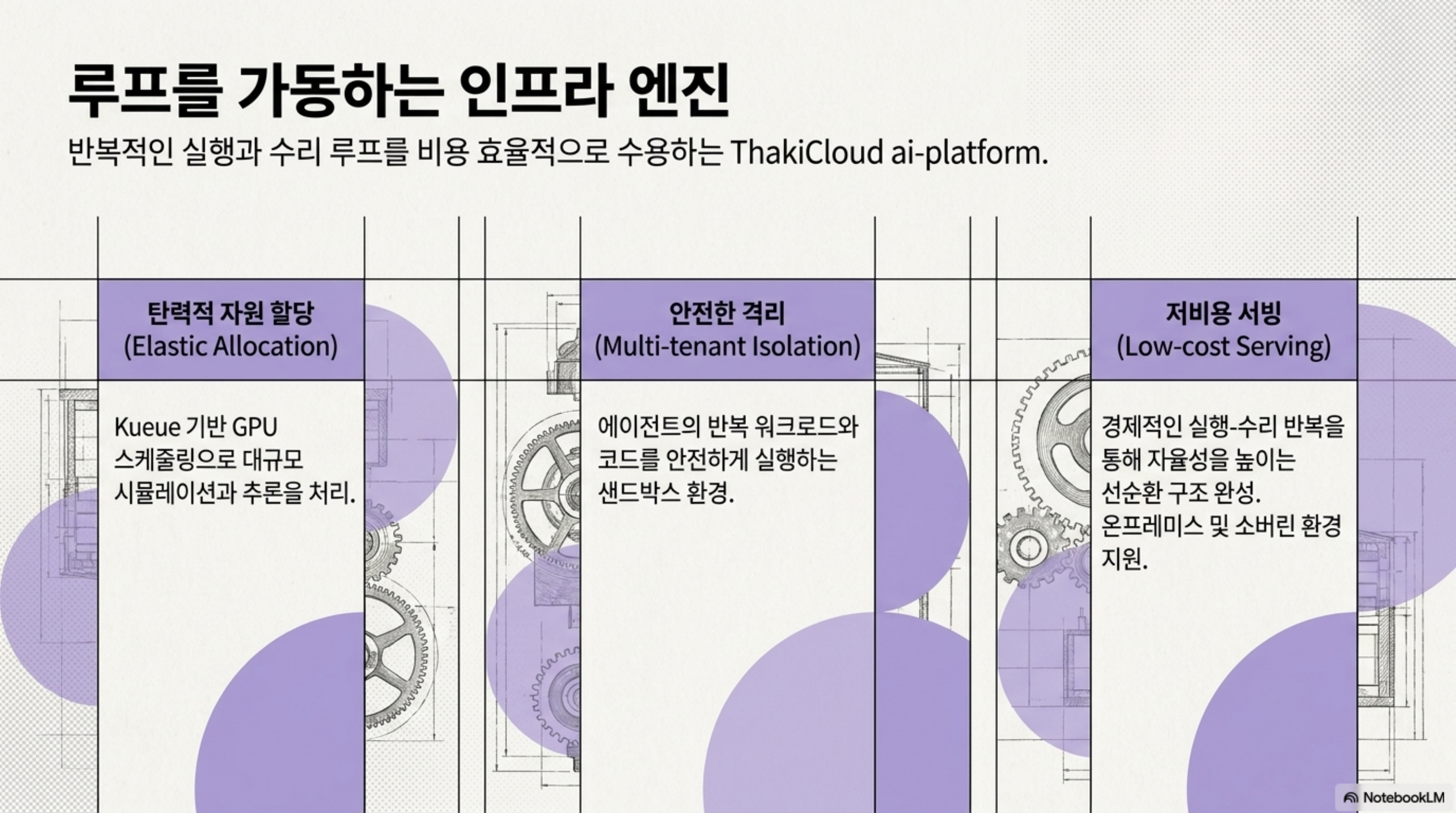
인프라 관점에서는 ThakiCloud의 ai-platform이 이 루프의 토대를 제공합니다. ASPIRE류의 반복 실행-수리 루프는 시뮬레이션과 추론을 대량으로 돌려야 하므로 GPU 자원의 탄력적 스케줄링이 전제됩니다. ai-platform은 Kueue 기반 GPU 스케줄링과 멀티테넌트 격리 위에서 이런 반복 워크로드를 비용 효율적으로 수용하도록 설계되어 있습니다. 저비용 서빙이 에이전트의 실행-수리 반복을 경제적으로 만들고, 그렇게 쌓인 스킬이 다시 에이전트의 자율성을 높이는 선순환입니다. 온프레미스와 소버린 환경을 요구하는 고객에게는 이 전체 루프를 자체 인프라 안에서 돌릴 수 있다는 점이 특히 의미가 있습니다.
한계 및 반론
ASPIRE의 결과가 인상적이더라도 몇 가지 유보가 필요합니다. 첫째, 보고된 수치는 대부분 시뮬레이션 벤치마크(Robosuite, LIBERO-Pro, BEHAVIOR-1K)에서 나온 것입니다. 시뮬레이션에서의 반복 디버깅은 값싸고 안전하지만, 실제 하드웨어에서는 매 시도가 시간과 마모, 안전 리스크를 수반합니다. 실행-실패-수리 루프의 경제성이 실물 로봇에서도 유지되는지는 별도의 검증이 필요합니다.

둘째, code-as-policy는 LLM이 유효한 제어 코드를 쓸 수 있는 과제에서 강하지만, 정밀한 연속 제어나 고빈도 피드백이 필요한 동작에서는 코드로 표현하기 어려운 영역이 남습니다. ASPIRE는 이런 저수준 제어를 기존 스킬이나 프리미티브에 위임하는 것으로 보이며, 그 프리미티브의 품질이 전체 성능의 상한을 정할 수 있습니다.
셋째, 스킬 라이브러리가 커질수록 검색과 선택의 부담이 늘어납니다. 라이브러리 성장이 성능 상승과 함께 간다는 결과는 고무적이지만, 규모가 더 커졌을 때 잘못된 스킬을 고르거나 오래된 스킬이 오답을 유발하는 문제가 없는지는 지속적으로 지켜봐야 합니다. 이는 Paxis의 스킬 하니스가 이미 마주한 과제이기도 하며, BM25 선택과 정책 게이트, 감사 로그가 바로 이 위험을 관리하기 위한 장치입니다.
그럼에도 ASPIRE가 제시한 방향, 즉 실패를 버리지 않고 검증된 스킬로 복리처럼 쌓는다는 원칙은 로봇과 소프트웨어 에이전트 양쪽에서 앞으로 표준이 될 가능성이 큽니다. 능력을 데이터가 아니라 축적된 스킬로 키운다는 관점의 전환이 이 연구의 진짜 기여입니다.
출처
- ASPIRE: Agentic /Skills Discovery for Robotics, arXiv 2607.00272: https://arxiv.org/abs/2607.00272
- 프로젝트 페이지 (NVIDIA GEAR): https://research.nvidia.com/labs/gear/aspire/
- 논문 페이지 (Hugging Face): https://huggingface.co/papers/2607.00272