환경을 먼저 상상하는 에이전트: Qwen-AgentWorld 언어 월드 모델을 뜯어봤습니다
⏱️ 예상 읽기 시간: 14분
📄 심층 리뷰 전문(DOCX): 이 논문의 상세 피어리뷰를 Google Drive에서 다운로드할 수 있습니다.
개요
요즘 에이전트는 대부분 같은 방식으로 일합니다. 과제를 받고, 일단 시도하고, 틀리면 고칩니다. 실제 환경에서 시행착오를 반복하는 구조입니다. 이 방식은 직관적이지만 비쌉니다. 환경이 실제 터미널이거나 실제 브라우저이거나 실제 안드로이드 기기라면, 매 시도마다 진짜 비용과 진짜 위험이 발생합니다.

2026년 6월 24일 Alibaba의 Qwen 팀이 공개한 Qwen-AgentWorld는 이 전제를 뒤집습니다. 에이전트를 “행동을 더 잘하도록” 학습시키는 대신, 모델이 환경 자체를 예측하도록 학습시킵니다. 즉 현재 관측과 행동이 주어졌을 때 다음 환경 상태가 무엇이 될지를 머릿속에서 먼저 그려보는 언어 월드 모델(Language World Model, LWM)입니다. 체스 선수가 수를 두기 전에 세 수 앞을 읽는 것과 같은 발상입니다.
저희 ThakiCloud는 쿠버네티스 기반 AI/ML SaaS 플랫폼에서 멀티테넌트 에이전트 워크로드를 직접 운영합니다. 고객마다 다른 환경, 다른 도구, 다른 제약 위에서 에이전트가 돌아가야 하므로 “환경을 어떻게 다루는가”는 저희에게 추상적인 연구 주제가 아니라 운영 비용과 직결되는 문제입니다. 그래서 이 모델을 공식 기술 보고서(arXiv 2606.24597)와 깃허브 공개 자료를 근거로 분석하고, 우리 플랫폼 관점에서 어디에 맞고 무엇을 조심해야 하는지를 함께 정리했습니다.
Qwen-AgentWorld는 무엇인가
월드 모델은 현재 관측과 행동을 바탕으로 환경의 동역학을 예측하는 모델입니다. 추론과 계획의 핵심 인지 메커니즘으로 오래 연구되어 온 개념인데, 그동안 로보틱스나 게임처럼 시각·물리 환경에서 주로 다뤄졌습니다. Qwen-AgentWorld는 이 월드 모델을 언어 모델 위에서, 긴 사고 연쇄(chain-of-thought) 추론으로 구현했다는 점이 다릅니다.
핵심 특징은 7개 도메인을 하나의 모델로 시뮬레이션한다는 것입니다. MCP, Search, Terminal, SWE, Web, OS, Android 일곱 가지 에이전트 상호작용 환경을 단일 모델이 다룹니다. 예를 들어 “리눅스 터미널 환경을 시뮬레이션하라”는 시스템 프롬프트와 사용자 명령이 주어지면, 모델은 그 명령을 실제로 실행하지 않고도 터미널이 내놓을 출력을 예측합니다.
또 하나 중요한 설계는 네이티브 월드 모델이라는 점입니다. 환경 모델링을 학습 후반에 덧붙인 부가 기능이 아니라, 학습 첫 단계(CPT)부터 학습 목표로 삼았습니다. 1천만 건이 넘는 실세계 상호작용 궤적을 활용해 처음부터 “환경을 모델링하는 능력”을 주입한 것입니다. 저자들의 표현을 빌리면, LLM은 환경에서 잘 행동하도록 학습되어 왔지만 환경 자체를 모델링하도록 학습된 적은 없었고, Qwen-AgentWorld가 그 빈 자리를 노립니다.
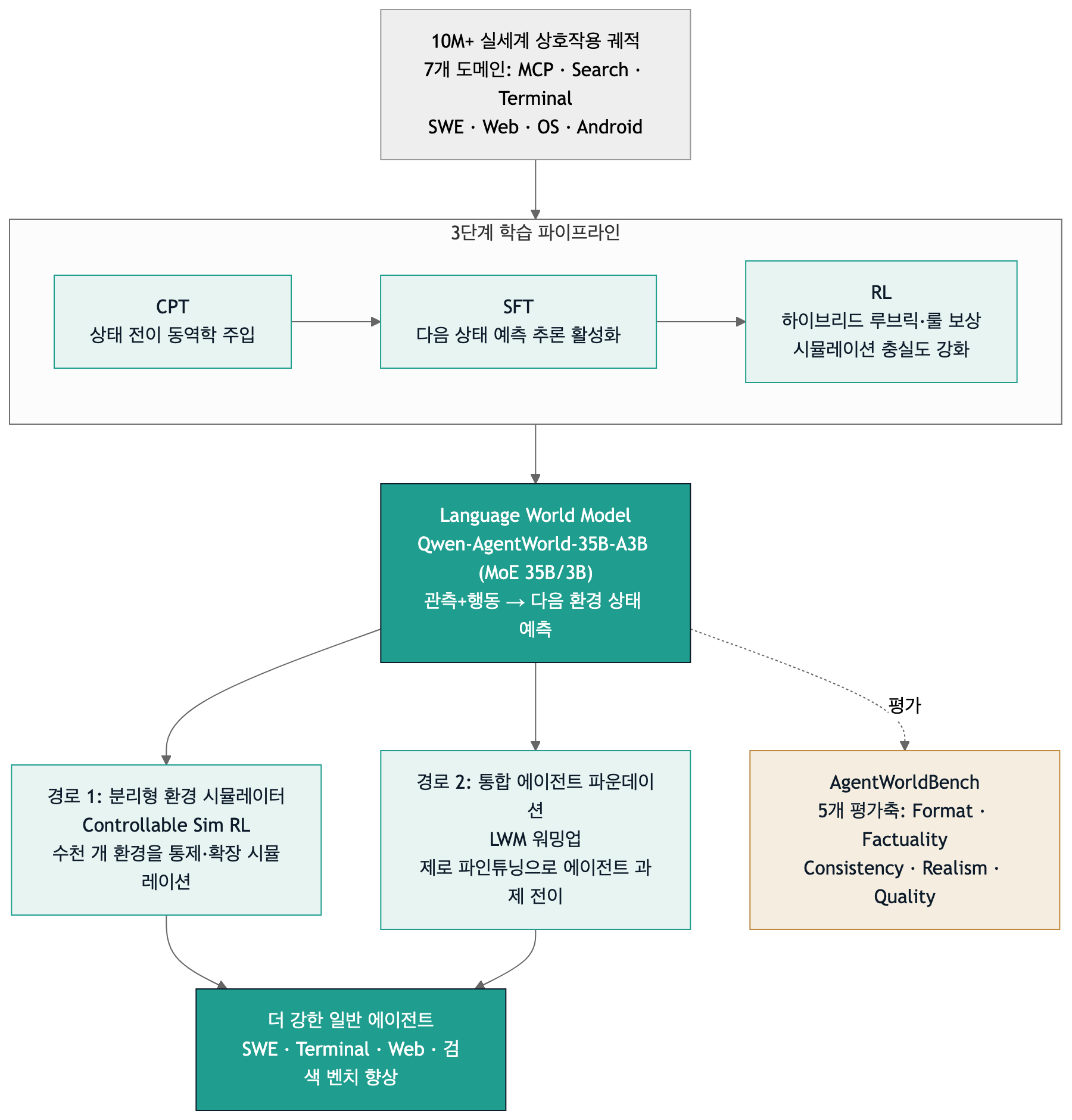 Qwen-AgentWorld의 3단계 학습 파이프라인(CPT/SFT/RL)과 두 가지 다운스트림 활용 경로를 정리한 구조도입니다.
Qwen-AgentWorld의 3단계 학습 파이프라인(CPT/SFT/RL)과 두 가지 다운스트림 활용 경로를 정리한 구조도입니다.
세 단계 학습 파이프라인
Qwen-AgentWorld는 세 단계 학습으로 만들어집니다. 각 단계가 맡는 역할이 명확하게 분리되어 있습니다.
- CPT(Continual Pre-Training): 상태 전이 동역학과 보강된 전문 코퍼스로부터 범용 월드 모델링 능력을 주입합니다. 환경이 어떤 행동에 어떻게 반응하는지를 모델의 기반 지식으로 심는 단계입니다.
- SFT(Supervised Fine-Tuning): 다음 상태 예측(next-state-prediction) 추론을 활성화합니다. 단순히 다음 상태를 맞히는 것이 아니라, 왜 그런 상태가 되는지를 사고 연쇄로 풀어내도록 만듭니다.
- RL(Reinforcement Learning): 하이브리드 루브릭·룰 보상으로 시뮬레이션 충실도를 끌어올립니다. 형식이 맞는지, 사실에 부합하는지, 일관적인지 등을 보상 신호로 삼아 예측 품질을 다듬습니다.
공개된 모델은 Qwen-AgentWorld-35B-A3B입니다. 전체 350억 파라미터 중 30억만 활성화되는 MoE(Mixture-of-Experts) 구조이고, 컨텍스트 길이는 256K입니다. 기술 보고서에는 더 큰 Qwen-AgentWorld-397B-A17B도 등장하지만, 이 397B 가중치는 공개되지 않았습니다. 공개 범위를 정확히 짚자면, 35B-A3B 모델 가중치와 AgentWorldBench 벤치마크가 Apache-2.0으로 공개되었고 397B는 보고서 안의 결과로만 존재합니다. 뒤에서 다시 다루겠지만, 이 구분은 “로컬에서 바로 돌려보라”는 홍보 문구를 읽을 때 반드시 기억해야 하는 지점입니다.
벤치마크: AgentWorldBench
언어 월드 모델을 어떻게 평가할까요? Qwen 팀은 AgentWorldBench라는 전용 벤치마크를 함께 공개했습니다. 5개 프런티어 모델이 9개 기존 벤치마크에서 만들어낸 실제 상호작용을 모아 구성했고, 예측된 환경 관측을 Format(형식), Factuality(사실성), Consistency(일관성), Realism(현실성), Quality(품질) 다섯 축으로 채점합니다. 채점에는 별도 심판 모델(gpt-5.2)을 씁니다.
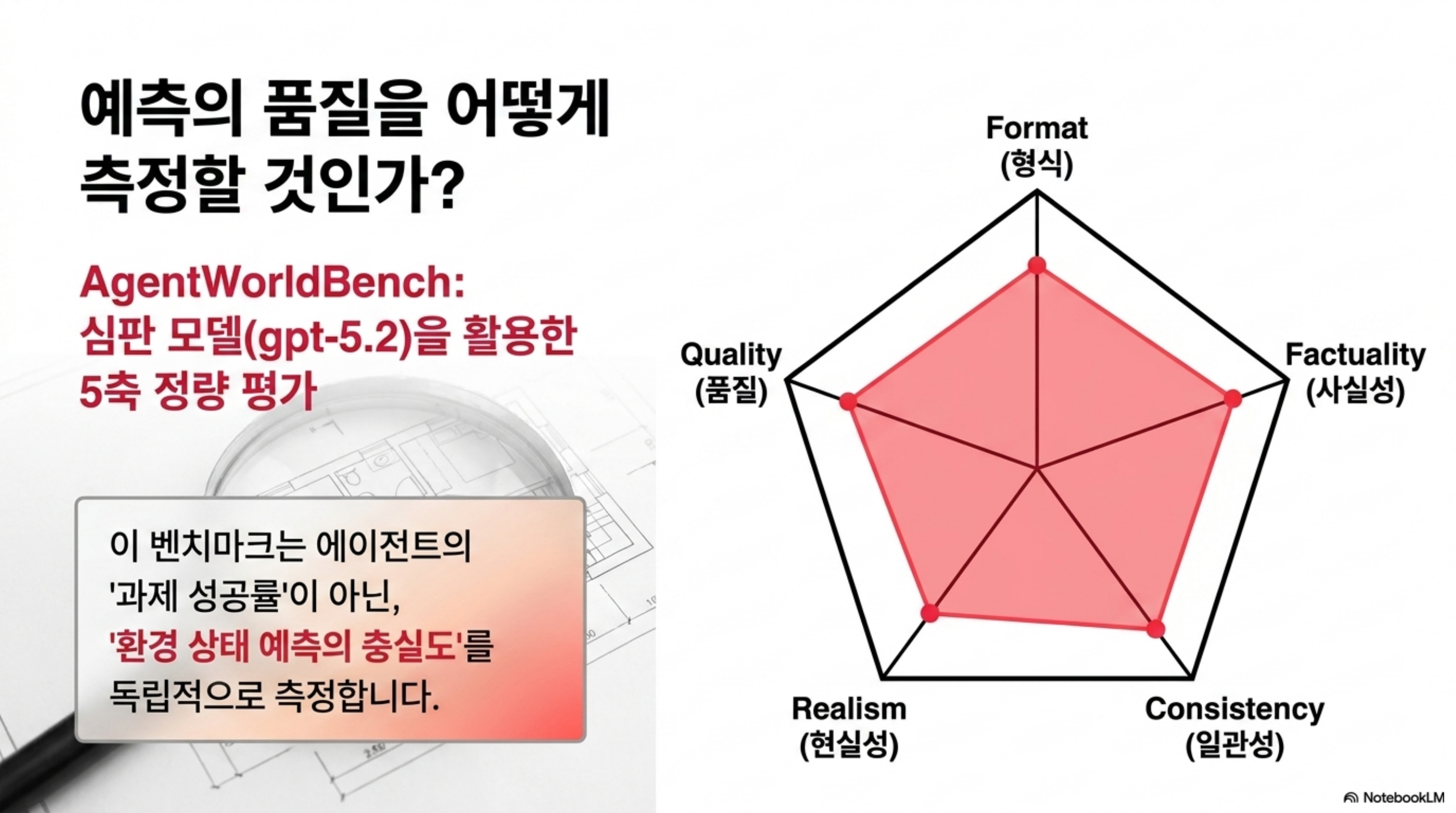 예측된 환경 관측을 형식·사실성·일관성·현실성·품질 다섯 축으로 채점합니다.
예측된 환경 관측을 형식·사실성·일관성·현실성·품질 다섯 축으로 채점합니다.
아래는 공식 깃허브 저장소에 공개된 도메인별 5축 루브릭 평균(0~100 정규화)의 전체(Overall) 점수입니다.
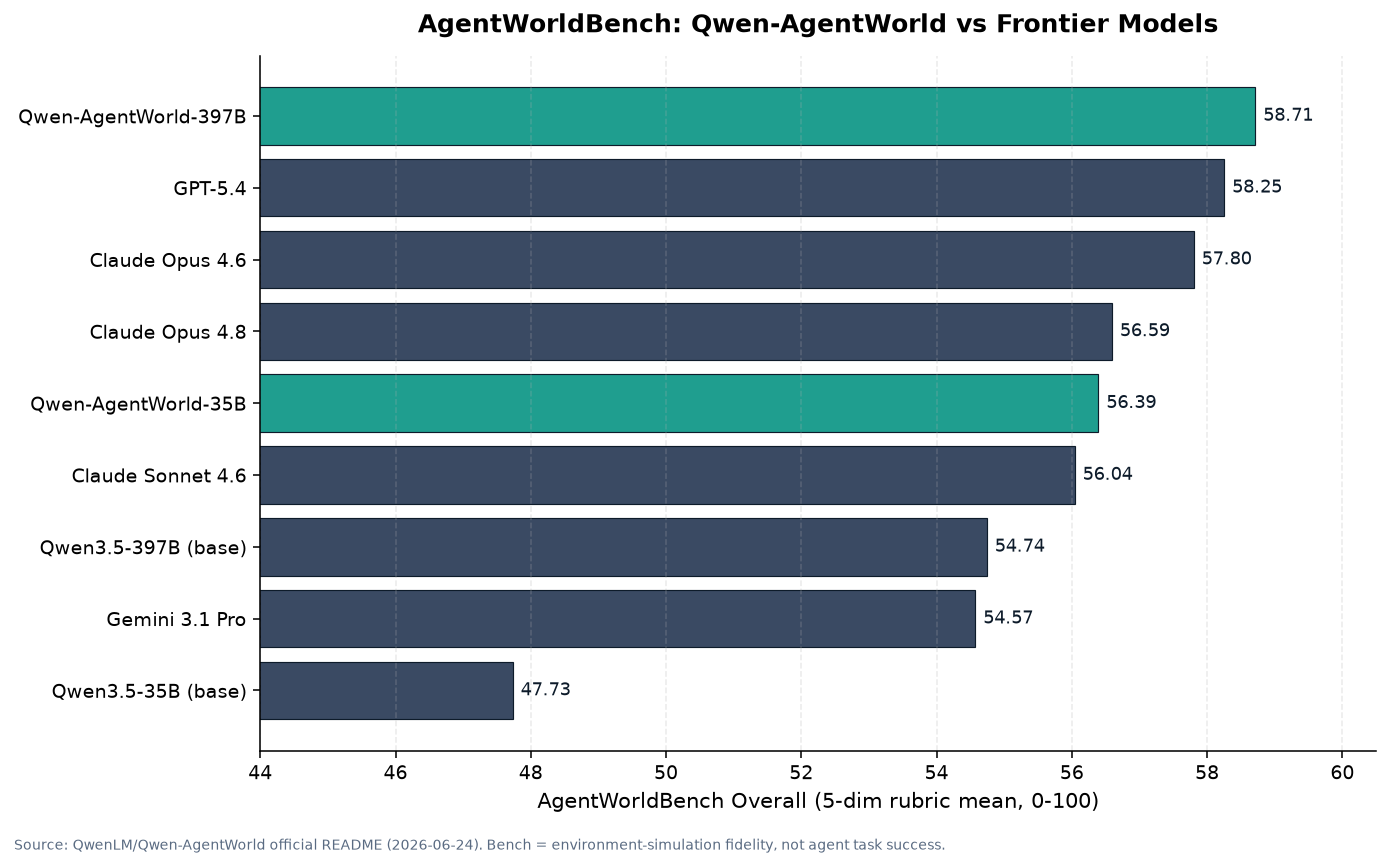 AgentWorldBench Overall 점수. 환경 시뮬레이션 충실도를 측정하며, 에이전트 과제 성공률과는 다른 지표입니다. 출처: QwenLM/Qwen-AgentWorld 공식 README.
AgentWorldBench Overall 점수. 환경 시뮬레이션 충실도를 측정하며, 에이전트 과제 성공률과는 다른 지표입니다. 출처: QwenLM/Qwen-AgentWorld 공식 README.
숫자로 정리하면 이렇습니다.
- Qwen-AgentWorld-397B-A17B: 58.71, 전체 1위입니다. GPT-5.4(58.25), Claude Opus 4.8(56.59), Gemini 3.1 Pro(54.57)를 모두 앞섭니다.
- Qwen-AgentWorld-35B-A3B: 56.39, 같은 크기의 베이스 모델 Qwen3.5-35B-A3B(47.73) 대비 +8.66 향상입니다. 월드 모델 학습만으로 8점 이상 오른 셈입니다.
 프런티어를 제친 모델과 실제로 내려받을 수 있는 모델이 다르다는 점을 구분합니다.
프런티어를 제친 모델과 실제로 내려받을 수 있는 모델이 다르다는 점을 구분합니다.
여기서 두 가지를 분명히 해야 합니다. 첫째, 이 벤치마크가 재는 것은 “에이전트가 과제를 잘 푸는가”가 아니라 “모델이 환경의 다음 상태를 얼마나 정확히 예측하는가”, 즉 시뮬레이터로서의 충실도입니다. 둘째, 프런티어 모델을 모두 제친 것은 397B이고, 공개된 35B는 56.39로 GPT-5.4와 Claude Opus 4.8보다는 살짝 아래입니다. 향상 폭은 인상적이지만 “공개 모델이 모든 폐쇄 모델을 이겼다”는 식의 단순화는 정확하지 않습니다.
월드 모델이 에이전트를 강하게 만드는 두 경로
Qwen-AgentWorld가 단순한 시뮬레이터에 그치지 않는 이유는, 이 월드 모델이 에이전트를 더 강하게 만드는 두 가지 경로를 함께 제시하기 때문입니다.
경로 1, 분리형 환경 시뮬레이터(Controllable Sim RL). 월드 모델을 환경 대신 사용해 에이전트를 강화학습시킵니다. 실제 환경을 수천 개씩 띄우는 대신, 통제 가능하고 확장 가능한 시뮬레이션 환경을 모델이 만들어냅니다. 보고서에 따르면 4천 개의 분포 밖(OOD) OpenClaw 환경에서 Sim RL을 적용했을 때, 베이스(65.4 / 47.9) 대비 Qwen-AgentWorld-397B-A17B를 환경으로 쓴 Sim RL이 69.7 / 55.0으로 올랐습니다. 흥미로운 점은 “통제된” 시뮬레이션이 “통제되지 않은” 것보다 나았다는 것입니다. 한 설정에서는 SFT 베이스 대비 통제 Sim RL이 +16.29 / +10.49 만큼 향상했습니다. 즉 실제 환경 학습만 했을 때보다 더 좋은 결과를 얻었습니다.
경로 2, 통합 에이전트 파운데이션(LWM 워밍업). 월드 모델 학습을 일종의 준비 운동으로 쓰는 방식입니다. 단일 턴, 비에이전트형 궤적으로 LWM RL 워밍업을 한 모델이, 멀티 턴·도구 호출형 에이전트 과제로 그대로 전이됩니다. 별도의 에이전트 전용 학습 없이도 예측 지식이 옮겨간다는 것이 핵심 주장입니다. Qwen3.5-35B-A3B-SFT에 LWM RL을 더했을 때 7개 벤치마크에서 다음과 같이 향상했습니다.
| 벤치마크 | SFT 베이스 | + LWM RL | 향상 |
|---|---|---|---|
| Terminal-Bench 2.0 | 33.25 | 39.55 | +6.30 |
| SWE-Bench Verified | 64.47 | 67.86 | +3.39 |
| SWE-Bench Pro | 42.18 | 47.42 | +5.24 |
| WideSearch F1 Item | 33.38 | 46.17 | +12.79 |
| Claw-Eval | 53.60 | 64.88 | +11.28 |
| QwenClawBench | 39.76 | 49.43 | +9.67 |
| BFCL v4 | 62.29 | 71.25 | +8.96 |
세 벤치마크는 완전히 도메인 밖이었는데도 향상이 나타났습니다. 환경을 예측하는 법을 배우는 것이 곧 환경에서 행동하는 법을 배우는 데 도움이 된다는, 다소 반직관적인 결과입니다.
실제로 어떻게 돌리나
공개된 35B-A3B 모델은 SGLang과 vLLM 같은 추론 프레임워크에서 바로 서빙할 수 있습니다. 공식 저장소가 제시하는 명령은 다음과 같습니다.
# vLLM으로 서빙
vllm serve Qwen/Qwen-AgentWorld-35B-A3B
# 또는 SGLang
python -m sglang.launch_server --model-path Qwen/Qwen-AgentWorld-35B-A3B
사용 방식은 일반적인 채팅 모델과 동일한 OpenAI 호환 인터페이스이지만, 시스템 프롬프트로 “어떤 환경을 시뮬레이션할지”를 지정한다는 점이 특징입니다.
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
messages = [
{
"role": "system",
"content": "You are a language world model simulating a Linux terminal environment. "
"Given the user's command, predict the terminal output.",
},
{"role": "user", "content": "ls -la /var/log"},
]
AgentWorldBench 평가도 공개되어 있어, 도메인별 JSONL(mcp_test.jsonl, terminal_test.jsonl 등)을 내려받아 5축 채점을 직접 재현할 수 있습니다. 다만 35B-A3B는 MoE 구조라도 GPU 메모리 요구가 작지 않아, 실서빙에는 적절한 가속기와 텐서 병렬 구성이 필요합니다. 저희는 이번 글에서 자체 GPU로 추론을 돌리지는 않았고, 공식 보고서와 저장소의 공개 수치만 근거로 분석했습니다. 직접 재현한 자체 측정치는 포함하지 않았습니다.
ThakiCloud K8s AI/ML SaaS 플랫폼 적용 및 시사점
저희 ThakiCloud는 쿠버네티스 위에서 Kueue로 GPU 워크로드를 스케줄링하고, vLLM으로 멀티테넌트 추론을 서빙하며, 고객별로 격리된 에이전트를 운영합니다. 이 관점에서 Qwen-AgentWorld가 던지는 시사점은 세 가지입니다.

첫째, 환경 시뮬레이션은 에이전트 학습의 비용 구조를 바꿀 수 있습니다. 고객 환경에서 에이전트를 강화학습시키려면 실제 환경을 수천 개 띄워야 하는데, 이는 GPU만이 아니라 환경 인프라(브라우저 풀, 샌드박스 터미널, 모바일 에뮬레이터)까지 함께 운영해야 한다는 뜻입니다. 월드 모델이 그 환경을 대체하면, 강화학습 루프를 모델 서빙 한 종류로 압축할 수 있습니다. Kueue 큐 하나로 통제되는 시뮬레이션 RL은 멀티테넌트 환경에서 운영 복잡도를 크게 낮춥니다.
둘째, 온프레미스·자기호스팅 친화적입니다. 35B-A3B는 Apache-2.0이라 상업적 활용과 자체 호스팅에 제약이 없습니다. 국내 공공·금융처럼 데이터가 외부로 나갈 수 없는 고객에게는, 고객 환경의 시뮬레이터를 외부 API가 아니라 우리 클러스터 안에 두는 선택지가 생깁니다. 환경을 모델로 캡슐화하면 민감한 운영 환경을 외부에 노출하지 않고도 에이전트를 학습·평가할 수 있습니다.
셋째, 평가 인프라로서의 가치입니다. AgentWorldBench의 5축 채점(형식·사실성·일관성·현실성·품질)은 그 자체로 멀티테넌트 에이전트 품질 게이트의 좋은 틀입니다. 고객에게 배포하기 전, 에이전트가 환경을 얼마나 정확히 이해하는지를 정량적으로 거를 수 있는 축을 제공합니다. 397B를 직접 서빙하지 못하더라도, 이 평가 설계와 공개된 35B 시뮬레이터는 내부 검증 파이프라인에 바로 녹일 수 있는 자산입니다.
물론 이것은 성숙 단계의 로드맵입니다. 당장 모든 고객 환경을 월드 모델로 치환하기는 어렵고, 시뮬레이터의 충실도가 떨어지는 도메인에서는 여전히 실제 환경 학습이 필요합니다. 다만 “환경을 모델이 대신 만든다”는 방향은 멀티테넌트 에이전트 플랫폼의 비용·격리 문제와 정확히 맞닿아 있어, 저희가 계속 추적할 가치가 충분합니다.
한계 및 반론

가장 먼저 짚을 것은 홍보 문구와 공개 범위의 간극입니다. 소셜미디어에서는 “Alibaba가 모든 폐쇄 모델을 이긴 에이전트 모델을 공개했고, 지금 로컬에서 돌려보라”는 식으로 퍼졌습니다. 그러나 프런티어를 제친 것은 공개되지 않은 397B이고, 실제로 내려받아 돌릴 수 있는 35B는 GPT-5.4·Claude Opus 4.8보다 약간 아래입니다. “이겼다”와 “공개했다”가 같은 모델을 가리키지 않는다는 점은 분명히 해야 합니다.
둘째, 벤치마크의 성격입니다. AgentWorldBench는 에이전트의 과제 성공률이 아니라 환경 예측의 충실도를 측정합니다. 환경을 정확히 예측한다고 해서 그 환경에서 과제를 잘 푼다는 보장은 직접적이지 않습니다. 경로 2의 전이 결과가 그 연결을 일부 보여주지만, 어디까지 일반화될지는 더 검증이 필요합니다.
셋째, 자기 구성·자기 채점의 한계입니다. 벤치마크를 만든 팀이 평가 축과 심판 모델(gpt-5.2)을 함께 설계했습니다. 이런 구성은 본질적으로 나쁜 것은 아니지만, 독립적인 제3자 재현이 쌓이기 전까지는 절대 수치를 보수적으로 읽는 편이 안전합니다.
넷째, 시뮬레이터의 환각 위험입니다. 월드 모델이 그럴듯하지만 틀린 환경 상태를 생성하면, 그 위에서 학습한 에이전트는 존재하지 않는 규칙을 배웁니다. 통제 가능성이 장점이자 위험인 셈입니다. 실제 환경과의 주기적 교정 없이 시뮬레이션에만 의존하는 학습은 분포 이동에 취약할 수 있습니다.
그럼에도 “에이전트를 똑똑하게 만들기 전에 환경을 이해하게 만든다”는 방향은 신선하고, 무엇보다 35B 모델과 벤치마크가 Apache-2.0으로 열려 있어 검증과 실험의 문이 닫혀 있지 않습니다. 과장된 헤드라인을 걷어내고 보면, 멀티테넌트 에이전트를 운영하는 플랫폼에게는 충분히 실용적인 연구입니다.
출처(Sources)
- Qwen-AgentWorld 기술 보고서(arXiv): arxiv.org/abs/2606.24597
- 공식 블로그: qwen.ai/blog?id=qwen-agentworld
- 깃허브: github.com/QwenLM/Qwen-AgentWorld
- 허깅페이스 모델/벤치마크: huggingface.co/collections/Qwen/qwen-agentworld
- Alibaba Qwen 공식 발표(X): x.com/Alibaba_Qwen/status/2069720365442719867
📄 심층 리뷰 전문(DOCX): 이 논문의 상세 피어리뷰를 Google Drive에서 다운로드할 수 있습니다.