Claude Code의 /dataviz 스킬: 차트를 코드가 아니라 설계로 다루기
개요
차트를 그리는 코드는 누구나 짤 수 있습니다. matplotlib으로 막대그래프를 뽑고, Recharts로 대시보드를 붙이는 일은 몇 줄이면 끝납니다. 문제는 그 결과물이 대부분 읽히지 않는다는 데 있습니다. 축이 0에서 시작하지 않아 차이가 과장되고, 계열마다 색이 제각각이라 범례를 세 번 확인해야 하고, 다크 모드로 바꾸면 대비가 무너져 글자가 사라집니다. 코드는 돌아가지만 그림은 의사결정을 돕지 못합니다.
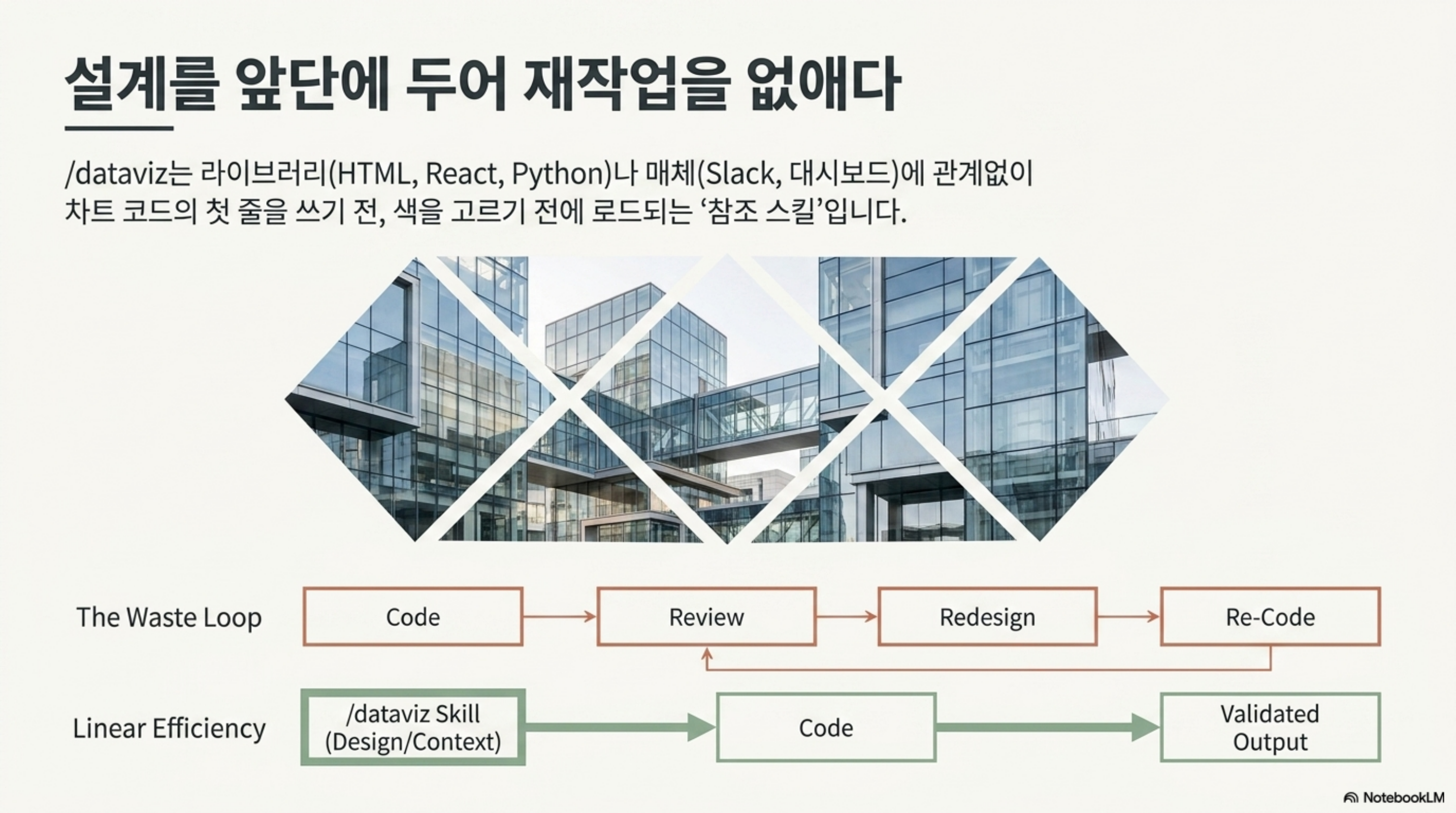
Claude Code 2.1.198은 이 간극을 겨냥한 내장 스킬 /dataviz를 추가했습니다. 공식 체인지로그는 “차트와 대시보드 설계 지침(chart and dashboard design guidance)”을 제공한다고만 짧게 적었지만, 실제로 하는 일은 차트를 코드 문제에서 설계 문제로 되돌리는 것입니다. 코드를 쓰기 전에 어떤 형태를 고를지, 색을 어떻게 배정할지, 접근성을 어떻게 지킬지를 먼저 컨텍스트에 얹습니다. ThakiCloud에서 GPU 사용량 대시보드나 모델 평가 리포트를 만들 때 반복되던 “일단 그리고 나중에 다듬기”의 순서를 뒤집는 도구라 눈여겨볼 만합니다.
/dataviz 스킬은 무엇인가
/dataviz는 어떤 출력 매체에서든 차트, 그래프, 대시보드를 만들기 직전에 읽는 참조 스킬입니다. HTML이나 React 아티팩트, 인라인 SVG, matplotlib이나 plotly나 d3나 Recharts 같은 라이브러리 코드, 렌더해서 업로드할 PNG, Slack으로 공유하는 차트까지 매체를 가리지 않습니다. 차트 코드의 첫 줄을 쓰기 전, 차트 색을 고르기 전, KPI 타일이나 미터나 지표 행을 배치하기 전에 먼저 로드하도록 설계되어 있습니다.
핵심은 특정 디자인 시스템에 묶이지 않는다는 점입니다. 스킬은 브랜드 중립적인 플레이스홀더 팔레트를 기본값으로 제공하고, 그 값을 각자의 브랜드 색으로 교체하도록 안내합니다. 즉 “이 색을 쓰세요”가 아니라 “색을 이렇게 고르는 방법을 쓰세요”에 가깝습니다. 방법론을 가르치기 때문에 프로젝트마다 팔레트가 달라도 같은 규율이 적용됩니다.
트리거되는 상황을 보면 스킬의 범위가 분명해집니다. 차트, 그래프, 플롯, 데이터 시각화, 대시보드, 애널리틱스라는 단어는 물론이고 범주형 색, 순차형과 발산형 팔레트, 지표 타일, 스파크라인, 히트맵, 범례, 축, 툴팁처럼 시각화의 구성 요소 하나하나가 진입점입니다. 차트 하나를 통째로 그리든 KPI 행 하나를 얹든 같은 지침을 거치게 됩니다.
이 스킬은 무엇을 컨텍스트에 얹는가
/dataviz가 로드하는 지침은 크게 네 덩어리로 나뉩니다. 폼 휴리스틱, 색 공식, 실행 가능한 검증기, 그리고 마크 사양과 인터랙션 규칙입니다.
flowchart TB
A["시각화 요청<br/>(차트·대시보드·KPI)"] --> B["폼 휴리스틱<br/>데이터 형태 → 차트 형태"]
B --> C["색 공식<br/>범주형·순차형·발산형 배정"]
C --> D["팔레트 검증기 실행<br/>대비·접근성 통과 여부"]
D --> E{"검증 통과?"}
E -->|"아니오"| C
E -->|"예"| F["마크 사양 + 인터랙션 규칙<br/>축·범례·툴팁"]
F --> G["일관된 시각화<br/>라이트·다크 동일 시스템"]
폼 휴리스틱은 데이터의 형태를 보고 차트의 형태를 결정하는 규칙입니다. 시계열인지, 분포인지, 부분과 전체의 관계인지, 지리 데이터인지에 따라 적합한 마크가 달라집니다. 이 단계가 있어야 “일단 파이 차트”라는 습관을 끊을 수 있습니다. 파이 차트가 대부분의 경우 나쁜 선택인 이유, 막대그래프의 축을 0에서 시작해야 하는 이유처럼 데이터 시각화 분야에서 오래 축적된 원칙이 여기에 코드화되어 있습니다. Edward Tufte나 Cole Nussbaumer Knaflic이 정리한 규범을 스킬이 실무 규칙으로 옮겨 놓은 셈입니다.
색 공식은 색을 장식이 아니라 데이터의 일부로 다룹니다. 범주형 데이터에는 서로 구분되는 색을, 순차형 데이터에는 밝기가 단계적으로 변하는 색을, 발산형 데이터에는 중앙을 기준으로 양쪽으로 갈라지는 색을 배정합니다. 계열별로 아무 색이나 찍는 대신 데이터의 의미 구조에 색을 맞추는 것입니다.
실행 가능한 팔레트 검증기가 이 스킬의 차별점입니다. 색을 고르는 지침에서 그치지 않고, 고른 팔레트가 실제로 읽히는지 코드로 검사합니다. 검증기는 색 대비와 접근성을 확인해서 라이트 모드와 다크 모드 양쪽에서 텍스트와 마크가 충분히 구분되는지 판정합니다. 사람의 눈대중이 아니라 결정론적 검사가 통과 여부를 소유하기 때문에, “괜찮아 보인다”는 주관을 배제합니다. 기본 팔레트는 references/palette.md에 검증을 통과한 값으로 문서화되어 있고, 그 파일의 값만 자기 브랜드 색으로 바꾸면 됩니다.
마크 사양과 인터랙션 규칙은 차트의 세부를 통일합니다. 축을 어떻게 그릴지, 범례를 어디에 둘지, 툴팁에 무엇을 담을지 같은 결정을 매번 새로 하지 않고 규칙으로 고정합니다. 결과적으로 서로 다른 사람이 서로 다른 라이브러리로 만든 차트가 하나의 시스템처럼 읽힙니다.
실제로 어떻게 쓰는가
사용법 자체는 단순합니다. 차트나 대시보드를 만들기 시작하기 전에 스킬을 불러오면, 위 네 덩어리의 지침이 컨텍스트에 들어옵니다. 그 뒤로는 어떤 라이브러리를 쓰든 같은 규율 위에서 코드가 생성됩니다.
주의할 점은 순서입니다. 스킬 설명이 반복해서 강조하는 것은 “차트 코드의 첫 줄을 쓰기 전에” 읽으라는 점입니다. 코드를 다 짜고 나서 색을 고치는 것은 이미 늦습니다. 축을 0에서 시작하지 않은 막대그래프를 사후에 바로잡으려면 스케일과 레이아웃을 다시 손봐야 하고, 다크 모드 대비 문제는 팔레트를 통째로 다시 짜야 하는 경우가 많습니다. 설계를 앞단에 두면 이런 재작업이 사라집니다.
Slack으로 공유하는 차트에도 같은 지침이 적용된다는 점은 실무에서 특히 유용합니다. 팀 채널에 붙이는 즉석 차트는 보통 가장 대충 만들어지고 가장 많이 읽히는 이중고를 겪는데, 스킬을 거치면 이런 차트도 정식 대시보드와 같은 규칙을 따르게 됩니다.
ThakiCloud 제품 적용 시사점
/dataviz가 던지는 메시지는 ThakiCloud가 두 제품에서 실천하는 원칙과 정확히 겹칩니다. 포맷과 품질을 모델의 즉흥에 맡기지 말고 검증된 골격에 채우게 만든다는 발상입니다.
ai-platform 렌즈에서 보면, 우리는 K8s 기반 AI/ML 인프라 위에서 GPU 사용량, Kueue 큐 상태, 모델 서빙 지연, 멀티테넌트별 비용 같은 지표를 끊임없이 시각화합니다. 이런 관측 대시보드는 운영자가 몇 초 안에 이상을 감지해야 하는 화면이라 시각적 위계가 곧 대응 속도입니다. 폼 휴리스틱으로 지표 성격에 맞는 차트를 고르고, 색 공식으로 정상과 경고와 장애를 색의 의미로 구분하고, 검증기로 다크 모드 대비를 보장하는 흐름은 운영 대시보드의 신뢰도를 그대로 끌어올립니다. 색을 장식이 아니라 상태 신호로 쓰는 규율은 온콜 대응에서 오판을 줄입니다.
Paxis 렌즈에서는 /dataviz 자체가 우리가 만드는 Agent-Native Cloud의 축소판입니다. Paxis는 ai-platform 위에서 도는 에이전트 제어 평면으로, 스킬을 일급 리소스로 다루고 960여 개의 스킬을 BM25로 선택해 격리 샌드박스에서 실행합니다. /dataviz가 “차트를 그리는 능력”을 하나의 스킬로 패키징해 필요할 때 컨텍스트에 얹는 방식은, Paxis의 Skill Harness가 지식과 규율을 스킬 단위로 묶어 재사용하는 구조와 같습니다. 특히 실행 가능한 팔레트 검증기는 우리가 여러 배치 스킬에서 지켜 온 원칙, 즉 숫자와 판정은 모델이 주장하지 않고 결정론적 코드가 소유한다는 규율의 데이터 시각화 버전입니다. 모델은 색을 제안하고, 코드가 그 색이 읽히는지 검사합니다. 이 분리가 있어야 여러 사람과 여러 에이전트가 만든 산출물이 하나의 시스템으로 수렴합니다.
두 렌즈는 서로를 보완합니다. ai-platform이 지표를 뽑아내고, Paxis가 그 지표를 일관된 시각 언어로 렌더하는 스킬을 안전하게 실행합니다. 저비용 인프라가 관측 가능성을 싸게 만들고, 스킬 하네스가 그 관측을 읽히는 그림으로 바꿉니다.
한계 및 반론
/dataviz는 만능이 아닙니다. 스킬이 얹는 것은 지침이지 자동 완성이 아니므로, 여전히 사람이나 에이전트가 차트를 짜야 합니다. 지침을 무시하고 코드를 먼저 쓰면 스킬을 불러온 의미가 없어집니다. 순서를 지키는 규율은 도구가 강제해 주지 않습니다.
또한 컨텍스트를 소비한다는 비용이 있습니다. 스킬을 로드하면 그만큼 토큰을 씁니다. 차트 한 장을 대충 그려도 되는 상황에서 매번 전체 지침을 얹는 것은 과잉일 수 있습니다. 품질이 결과물의 핵심인 대시보드와 리포트에는 값어치를 하지만, 일회성 스크래치 플롯에는 억지로 적용할 이유가 없습니다.
기본 팔레트가 브랜드 중립적이라는 점도 양날입니다. 교체하지 않고 그대로 쓰면 어느 회사 차트인지 알 수 없는 무색무취한 그림이 나옵니다. references/palette.md의 값을 자기 브랜드로 바꾸는 한 단계를 건너뛰면 일관성은 얻되 정체성은 잃습니다. 스킬은 방법을 주고, 브랜드를 입히는 마지막 결정은 여전히 우리 몫입니다.
관련 슬라이드
본문 내용을 NotebookLM(strategic_blue 스타일)으로 요약한 슬라이드입니다.



출처
- Claude Code CLI 2.1.198 체인지로그 (ClaudeCodeLog, X)
- Claude Code 내장
dataviz스킬 설명 및references/palette.md