تحليل المستندات بمستوى SOTA باستخدام نموذج بحجم 0.9B: تجربة عملية مع PaddleOCR-VL على النصوص العربية والكورية
 تعبير تجريدي عن مسار تحويل المستندات إلى بيانات منظمة.
تعبير تجريدي عن مسار تحويل المستندات إلى بيانات منظمة.
📄 المراجعة المتعمقة الكاملة (DOCX): نزّل المراجعة التفصيلية من Google Drive.
نظرة عامة
تحليل المستندات، أي تحويلها إلى بنية قابلة للقراءة آلياً، بات أكثر أهمية في عصر RAG والعوامل الذكية. فالصفحة الواحدة من PDF قد تجمع نصاً سردياً وجداول ومعادلات ومخططات وتخطيطاً متعدد الأعمدة، وعلى النموذج أن يفك هذا التشابك بترتيب قراءة دقيق حتى تستطيع النماذج اللغوية الكبيرة الاستفادة منه. حتى وقت قريب، كان هذا الميدان حكراً على النماذج متعددة الوسائط العملاقة كـ GPT-4o وGemini 2.5 Pro، أو على أدوات المعالجة الأنبوبية الثقيلة.
PaddleOCR-VL الصادر عن فريق PaddlePaddle (Baidu) يزعزع هذه المعادلة. فنموذجه الأساسي PaddleOCR-VL-0.9B لا يتجاوز 960 مليون معامل، نموذج رؤية-لغة بالغ الصغر، غير أنه يُفيد بأداء متصدر في تحليل المستندات على مستوى الصفحة كاملاً، وكذلك في التعرف على المكونات الفردية. الرخصة Apache-2.0 تتيح الاستخدام التجاري بحرية، ويشهد النموذج إقبالاً واسعاً على Hugging Face إذ تجاوز عدد التنزيلات 120,000 مرة.
في ThakiCloud نشغّل فعلياً بنية تحتية للاستدلال متعدد المستأجرين ومعالجة المستندات على منصة AI/ML SaaS مبنية على Kubernetes. لهذا لم نكتفِ بمراجعة النموذج نظرياً، بل ثبّتناه وأجرينا عليه استدلالاً فعلياً على مستندات تجمع الكورية والإنجليزية والعربية. نوضح هنا ما إذا كان النموذج الصغير جديراً بالاستخدام الفعلي، وأين يناسب منصتنا.
ما هذه التقنية؟
الفكرة المحورية في PaddleOCR-VL أنها لا تعتمد على نموذج ضخم واحد من البداية للنهاية يعالج كل شيء. فالأسلوب الشامل يعتمد على فك ترميز ذاتي الانحدار الطويل الذي يرفع تكلفة الكمون والذاكرة، ويُضخّم الهلوسة وعدم الاستقرار في التخطيطات المتعددة الأعمدة والمختلطة. عوضاً عن ذلك، تفصل PaddleOCR-VL المهمة إلى مرحلتين.
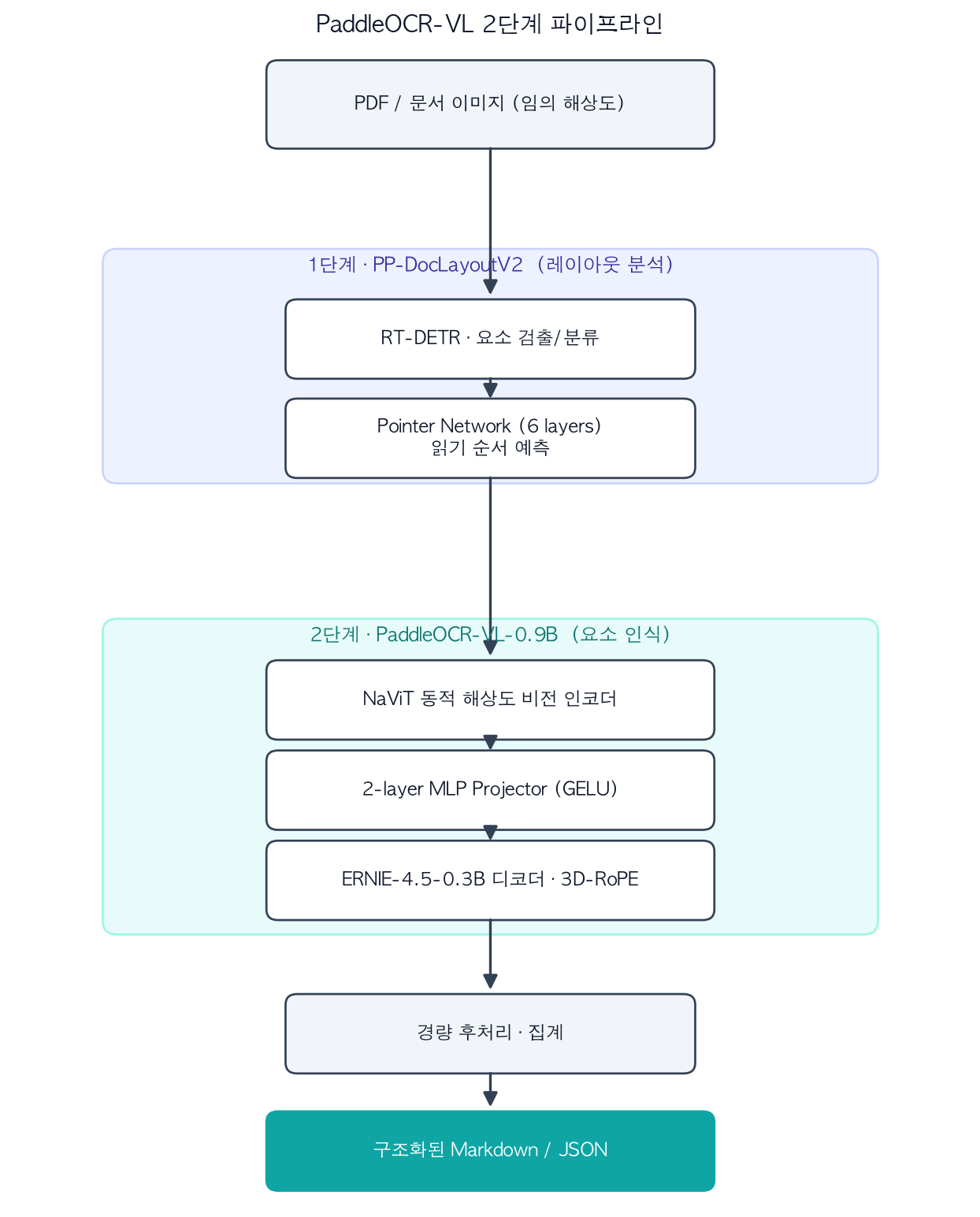 البنية ثنائية المراحل التي تفصل تحليل التخطيط عن التعرف على المكونات.
البنية ثنائية المراحل التي تفصل تحليل التخطيط عن التعرف على المكونات.
المرحلة الأولى، تحليل التخطيط (PP-DocLayoutV2): نموذج خفيف متخصص يرصد المناطق الدلالية في المستند ويصنّفها ويتنبأ بترتيب القراءة. يستخدم RT-DETR للكشف عن الكائنات، وشبكة مؤشر مكوّنة من ست طبقات محوّلة للتنبؤ بترتيب القراءة. بفصل استدلال التخطيط عن نموذج الرؤية-اللغة الثقيل، تحقق النماذج نتائج مستقرة حتى في التخطيطات متعددة الأعمدة.
المرحلة الثانية، التعرف على المكونات (PaddleOCR-VL-0.9B): تتلقى هذه المرحلة المناطق التي رصدتها المرحلة الأولى وتتعرف بدقة على النص والجداول والمعادلات والمخططات. تتبع البنية نمط LLaVA مع مشفّر بصري ذي دقة ديناميكية على غرار NaViT (مُهيَّأ من نموذج الرؤية Keye-VL) لمعالجة الصور بأي دقة دون تشويه. يربط مُسقِط MLP مزدوج الطبقات مع تفعيل GELU (بحجم دمج 2) السمات البصرية بفضاء تضمينات النموذج اللغوي، فيما يعمل المُفكِّك ERNIE-4.5-0.3B المعزز بـ 3D-RoPE مُفكِّكاً. اختيار نموذج لغوي صغير مقصود: كلما صغر المُفكِّك تسارع فك الترميز رمزاً بعد رمز.
تُكمل وحدة مُعالجة لاحقة خفيفة الدورة بدمج مخرجات المرحلتين في Markdown وJSON منظّمَين. يدعم النموذج 109 لغة تشمل الكورية واليابانية والعربية والسيريلية والديفانغاري (الهندية) إضافة إلى الأبجديات اللاتينية.
التثبيت والتكامل
لنُجرِ التثبيت بأنفسنا. البيئة: MacBook بمعالج Apple Silicon (macOS، معالج مركزي فقط، بلا تسريع GPU)، Python 3.12.8. تعمل PaddleOCR-VL فوق منظومة PaddlePaddle، فنثبّت الحزمتين التاليتين:
# التثبيت في البيئة الافتراضية المشتركة (.venv) وفق قواعد python-runtime
VIRTUAL_ENV="$PWD/.venv" uv pip install paddlepaddle paddleocr
# الإصدارات المثبتة: paddlepaddle==3.3.1, paddleocr==3.7.0
عند المحاولة الأولى للاستدلال ظهر الخطأ التالي:
RuntimeError: A dependency error occurred during pipeline creation.
Please refer to the installation documentation to ensure all required dependencies are installed.
يتطلب خط أنابيب PaddleOCR-VL تبعيات إضافية خاصة بتحليل المستندات. حلّينا الأمر بسطر واحد:
VIRTUAL_ENV="$PWD/.venv" uv pip install "paddleocr[doc-parser]"
شيفرة الاستدلال نفسها مختصرة؛ يقوم خط الأنابيب بتنزيل النماذج اللازمة تلقائياً:
from paddleocr import PaddleOCRVL
pipe = PaddleOCRVL() # تنزيل النموذج تلقائياً عند الاستدعاء الأول
out = pipe.predict("sample_doc.png") # صورة المستند ← مخرجات منظمة
for res in out:
res.save_to_markdown(save_path="paddleocr_out")
ثمة نقطة جديرة بالإشارة: اختارت paddleocr==3.7.0 تلقائياً PP-DocLayoutV3 نموذجاً للتخطيط، وPaddleOCR-VL-1.6-0.9B نموذجاً للتعرف. بمعنى أن الحزمة لا تجلب الإصدار الأوّلي الوارد في الورقة البحثية (2510.14528)، بل نموذج 1.6 المحدَّث ونموذج تخطيط أحدث. رقم “96.33% SOTA على OmniDocBench” الذي انتشر على تويتر ينتمي تحديداً إلى PaddleOCR-VL-1.6 (وفق OmniDocBench v1.6)، وهو مختلف عن الأرقام الأولية التي أوردتها الورقة البحثية. سنوضح هذا التمييز لاحقاً.
نتائج التجربة الفعلية
أنشأنا صورة اصطناعية تجمع الكورية والإنجليزية والعربية وأرقاماً ومعادلات بسيطة لاستخدامها في الاختبار، مستوحاة من فواتير ThakiCloud وتقارير التكاليف في صفحة واحدة. القياسات الفعلية في بيئة المعالج المركزي:
- تهيئة النموذج (الاستدعاء الأول، شاملاً التنزيل): 74.7 ثانية
- الاستدلال (predict): 32.65 ثانية / صفحة واحدة
- الوقت الإجمالي (من الاستيراد حتى الحفظ): 137.4 ثانية
- سجل بنية المُفكِّك: GQA (انتباه مجمّع الاستعلامات)، num_heads 16 / num_key_value_heads 2
كانت مخرجات Markdown للتعرف على النحو التالي:
## ThakiCloud Document Intelligence
Kubernetes AI/ML SaaS Platform - Invoice No. 2026-0623
타키클라우드 멀티테넌트 추론 비용 보고서
GPU hours: 1,284 Total: $9,640.00
E = mc^2 sum_{i=1}^{n} x_i
اللافت أن النموذج التقط العنوان الإنجليزي بوصفه ترويساً في Markdown (##)، وتعرّف بدقة على الجملة الكورية “타키클라우드 멀티테넌트 추론 비용 보고서”، وقرأ الأرقام والرموز النقدية ($9,640.00، GPU hours 1,284) دون أخطاء. جودة التعرف على الكورية مستقرة بشكل لافت لنموذج بهذا الحجم.
ثمة ملاحظة أمينة تستحق التسجيل: السطر العربي في صورتنا الاصطناعية لم يُحوَّل إلى نص، بل صُنِّف كمنطقة صورة. هذا ليس قصوراً في النموذج بل مشكلة في صورة الاختبار؛ إذ أن الرسم باستخدام PIL للعربية لم يعالج صحيح التشكيل واتصال الحروف وثنائية الاتجاه، فخرجت الحروف منفصلة، فاعتبرتها مرحلة التخطيط عنصراً مرسوماً. مسافة التحرير التي تُفيد بها الورقة للتعرف على الأسطر العربية هي 0.122 وهي منخفضة كافياً، ما يعني أن نتائج مختلفة ستظهر مع مستندات عربية حقيقية. هذه التجربة بحد ذاتها تمنحنا درساً تشغيلياً: جودة المعالجة الأولية والرسم تحدد جودة المخرجات.
فيما يلي الأرقام التي أوردتها الورقة البحثية من المعايير العامة. المخطط أدناه يعرض مسافات التحرير لعدد من اللغات من مجموع 109 لغة (الأقل كلما كان أفضل):
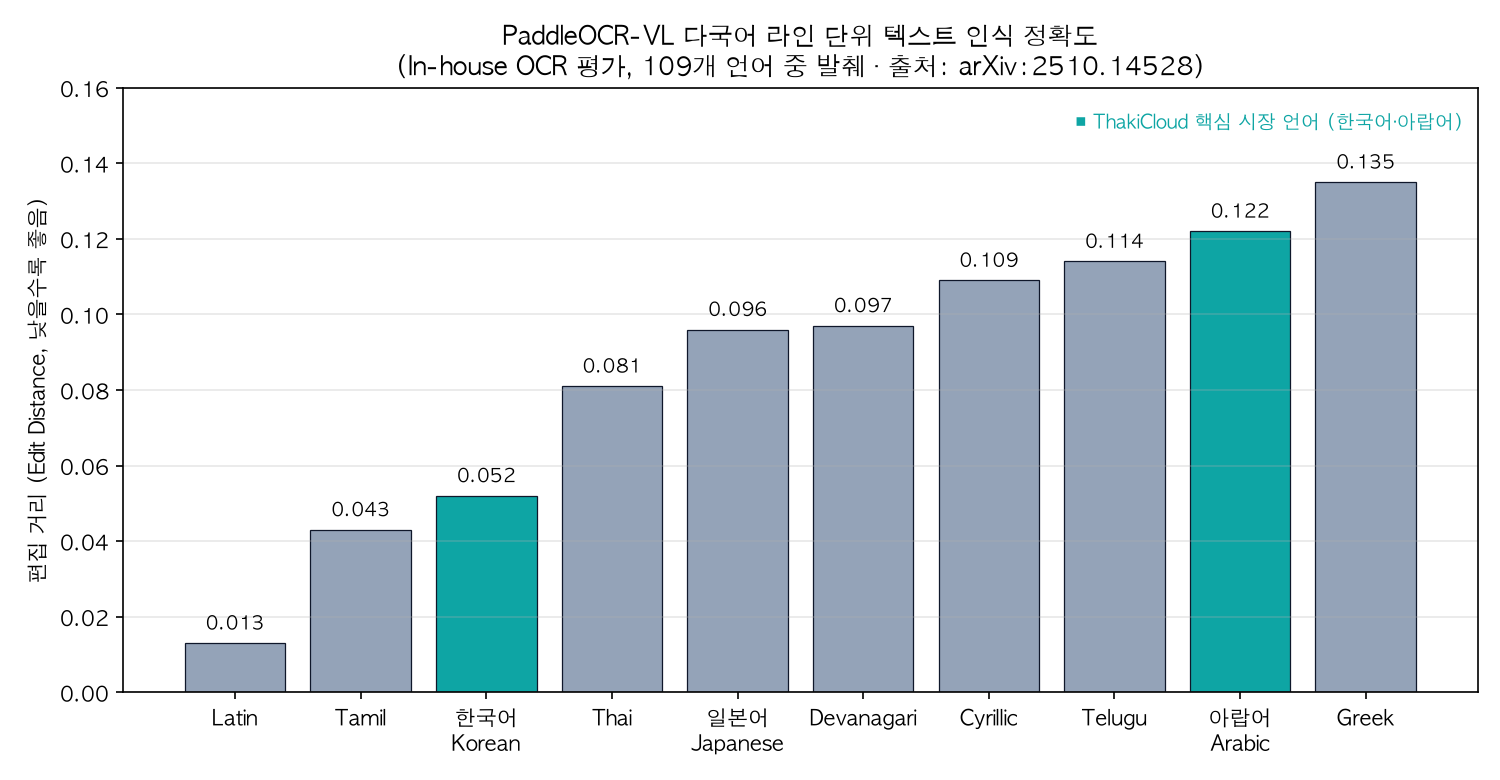 إبراز الكورية والعربية، وهما السوقان الرئيسيتان لـ ThakiCloud. المصدر: arXiv:2510.14528.
إبراز الكورية والعربية، وهما السوقان الرئيسيتان لـ ThakiCloud. المصدر: arXiv:2510.14528.
الكورية عند 0.052 والعربية عند 0.122، كلتا اللغتين المستهدفتين تُظهران مسافات تحرير جيدة. على صعيد الأداء الشامل على مستوى الصفحة، تُشير الورقة البحثية إلى أن النموذج حقق 92.86 في المجموع على OmniDocBench v1.5، متفوقاً على MinerU2.5-1.2B (90.67) الذي يليه مباشرة.
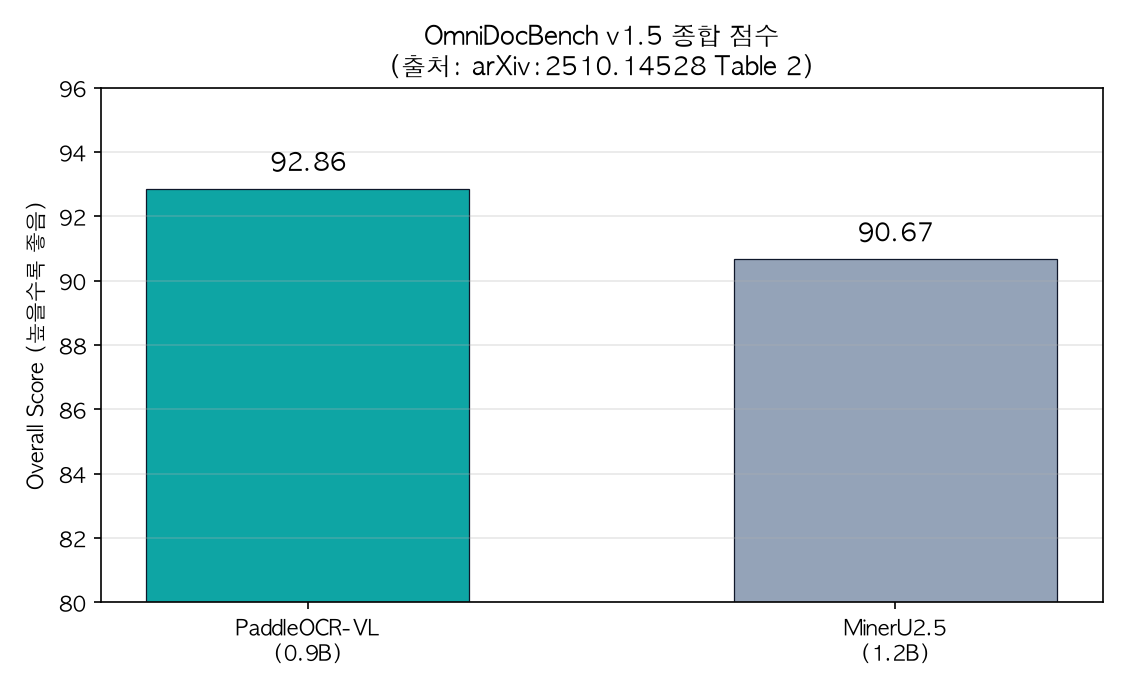 نموذج 0.9B يتفوق على نموذج 1.2B في الدرجة الإجمالية. المصدر: arXiv:2510.14528 Table 2.
نموذج 0.9B يتفوق على نموذج 1.2B في الدرجة الإجمالية. المصدر: arXiv:2510.14528 Table 2.
عند الاستشهاد بالأرقام لا بد من توضيح الإصدار. الورقة البحثية (2510.14528) أفادت بـ 92.86 على OmniDocBench v1.5؛ والإصدار اللاحق PaddleOCR-VL-1.5 أفاد بـ 94.5% على v1.5، فيما أفاد PaddleOCR-VL-1.6 بـ 96.33% على v1.6 كرقم [تقديري] (أرقام الإصدارات اللاحقة مستندة إلى تقارير منفصلة). الرقم 96.33% الذي ظهر على تويتر ينتمي إلى أحدث إصدار 1.6. كذلك تجدر الإشارة إلى أن سرعة الاستدلال المقاسة في الورقة تمت على NVIDIA A100 واحد بمعالجة دُفعية لـ 512 مستنداً باستخدام محركات خدمة عالية الأداء كـ vLLM وSGLang وFastDeploy. قياسنا لـ 32.65 ثانية/صفحة على المعالج المركزي هو رقم مرجعي لبيئة بلا تسريع، ولا يعكس الإنتاجية في بيئة الإنتاج.
دلالات التطبيق على منصة ThakiCloud K8s AI/ML SaaS
جاذبية هذا النموذج لا تكمن فقط في ارتفاع درجاته، بل في سهولة تشغيله لصغر حجمه. من منظور منظومة ThakiCloud:
- خدمة متعددة المستأجرين بتكلفة منخفضة: نموذج 0.9B يعمل على بطاقة GPU واحدة من الفئة الاستهلاكية أو الاقتصادية. نشره فوق جدولة GPU المستندة إلى Kueue ومحركات الخدمة vLLM وSGLang يتيح تشغيل نقاط نهاية منفصلة لتحليل مستندات كل مستأجر بتكلفة معقولة، مع التحكم الكامل في التكلفة عبر الاستدلال ذاتي الاستضافة بدلاً من دفع رسوم رمزية لنموذج ضخم.
- سيادة البيانات والتشغيل المحلي: المستندات كثيراً ما تحوي معلومات حساسة كفواتير وعقود وسجلات طبية ومالية يصعب إرسالها خارجياً. الاستضافة الذاتية لنموذج Apache-2.0 تتيح تقديم استخبارات المستندات دون إرسال البيانات إلى واجهات برمجية خارجية، بما يتوافق مع اشتراطات عزل الشبكة وقيود تصدير البيانات في القطاعات الحكومية والمالية.
- تعدد اللغات يعني ملاءمة السوق: يصدر مدونة ThakiCloud بالكورية والإنجليزية والعربية. من موقعنا المُطِل على السوقين الكوري والشرق أوسطي، معالجة الكورية (0.052) والعربية (0.122) بنموذج واحد بشكل موثوق يترجم مباشرة إلى ميزة تنافسية ويُقلل الحاجة إلى محركات OCR مختلفة لكل سوق.
- طرف المدخلات في خط أنابيب RAG: مخرجات Markdown وJSON المنظّمة تتغذى مباشرة في فهرسة RAG واستدعاءات أدوات الوكلاء. النص المحافظ على تخطيطه وترتيب قراءته يرفع جودة القطع ويُسهم مباشرة في دقة الاسترجاع.
في مرحلة أكثر نضجاً، يمكن فصل نموذج التخطيط من المرحلة الأولى عن نموذج التعرف من المرحلة الثانية كخدمتين مستقلتين: التخطيط على عقد المعالج المركزي، والتعرف بنموذج الرؤية-اللغة على عقد GPU. البنية المنفصلة على مرحلتين تُيسّر جدولة الموارد غير المتجانسة في بيئة Kubernetes.
القيود والاعتراضات
لا يصح الاكتفاء بالإيجابيات. إليك نقاط الضعف بناءً على القياس الفعلي والأدبيات:
- بطء على المعالج المركزي: 32.65 ثانية/صفحة التي قسناها غير مناسبة لمعالجة المستندات بكميات كبيرة. الاستخدام الفعلي يستلزم GPU ومحركات خدمة كـ vLLM وSGLang، وإنتاجيات الورقة المُبهرة تستند إلى بيئة دُفعية على A100.
- تبعيات البنية الثنائية: تحتاج إلى إدارة نموذجَي التخطيط والتعرف معاً، مما يزيد تكلفة النشر وإدارة توافق الإصدارات مقارنة بنموذج واحد. في الواقع تجلب الحزمة بشكل افتراضي PP-DocLayoutV3 + PaddleOCR-VL-1.6، وهذا التوليف قد يتغير بمرور الوقت.
- أرقام SOTA مرتبطة بإصدار محدد: 96.33% هو رقم الإصدار 1.6 على OmniDocBench v1.6، وليس العنوان الرئيسي للورقة الأساسية التي اقترحت 0.9B. الاستشهاد دون توضيح الإصدار والمعيار يُفضي إلى التضليل.
- الاعتماد على جودة المعالجة الأولية: كما أظهر اختبارنا العربي، جودة رسم الصورة ودقتها وتشكيل حروفها تحدد النتيجة. في خطوط الأنابيب الإنتاجية، مرحلة توحيد المدخلات لا تقل أهمية عن اختيار النموذج.
- ضعف التعرف على الجداول: أشارت الورقة البحثية نفسها إلى أن TEDS الخاصة بالجداول الإنجليزية على OmniDocBench v1.0 (88.0) منخفضة نسبياً (مع تفسير بتأثير أخطاء التعليق). المستندات الغنية بالجداول تستلزم تحققاً منفصلاً.
خلاصة القول، PaddleOCR-VL خيار مُغرٍ جداً بوصفه نموذج تحليل مستندات “صغيراً لكن قوياً” لاستخبارات المستندات ذاتية الاستضافة. غير أن استخراج قيمته الحقيقية في الإنتاج يتطلب معالجة ثلاثة تحديات تشغيلية معاً: خدمة GPU، وتثبيت الإصدارات، ومعالجة المدخلات الأولية.
المصادر
- ورقة PaddleOCR-VL البحثية (arXiv:2510.14528): Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
- بطاقة النموذج على Hugging Face: PaddlePaddle/PaddleOCR-VL
- الكود المصدري: github.com/PaddlePaddle/PaddleOCR
- أُجريت التجارب الواردة في هذا المقال على بيئة ThakiCloud (macOS، معالج مركزي) مباشرة، وأرقام المعايير المُستشهد بها مستقاة من الورقة البحثية المذكورة أعلاه.
📄 المراجعة المتعمقة الكاملة (DOCX): نزّل المراجعة التفصيلية من Google Drive.