Sakana Fugu: The Orchestration Era Where Models Command Models
Overview
For much of the past several years, AI progress has been driven by scale: train bigger models on more data, and compete on monolith benchmarks. But the hard problems of the real world demand a breadth of knowledge and skill that far exceeds any single benchmark score. The ability to judge which model fits which task, to divide planning from execution, and to combine the strengths of different models – collective intelligence – is emerging as the next axis of competition.
On June 22, 2026, Tokyo-based Sakana AI launched Sakana Fugu, a product aimed squarely at this shift. Fugu is a multi-agent system that dynamically coordinates multiple LLMs while presenting a single model API to the caller. What makes it notable is that Fugu itself is “a language model trained to call other models.” A model commands models.
This post analyzes Fugu’s architecture from the perspective of ThakiCloud, an operator of multi-tenant agent platforms. We examine why packaging orchestration inside a single model is a meaningful design choice, how to read the self-reported benchmarks, and what contradictions lurk in the product’s marketing claim that it reduces vendor lock-in.
What This Technology Is
Sakana Fugu is a multi-agent system that behaves like a single model. When a user sends a request to a single endpoint, Fugu decides how to handle it. Simple requests it handles directly; more complex tasks it routes to a coordinated team of specialist models. Model selection, delegation, verification, and synthesis all happen internally, so the complexity of a multi-agent system never surfaces in user code.
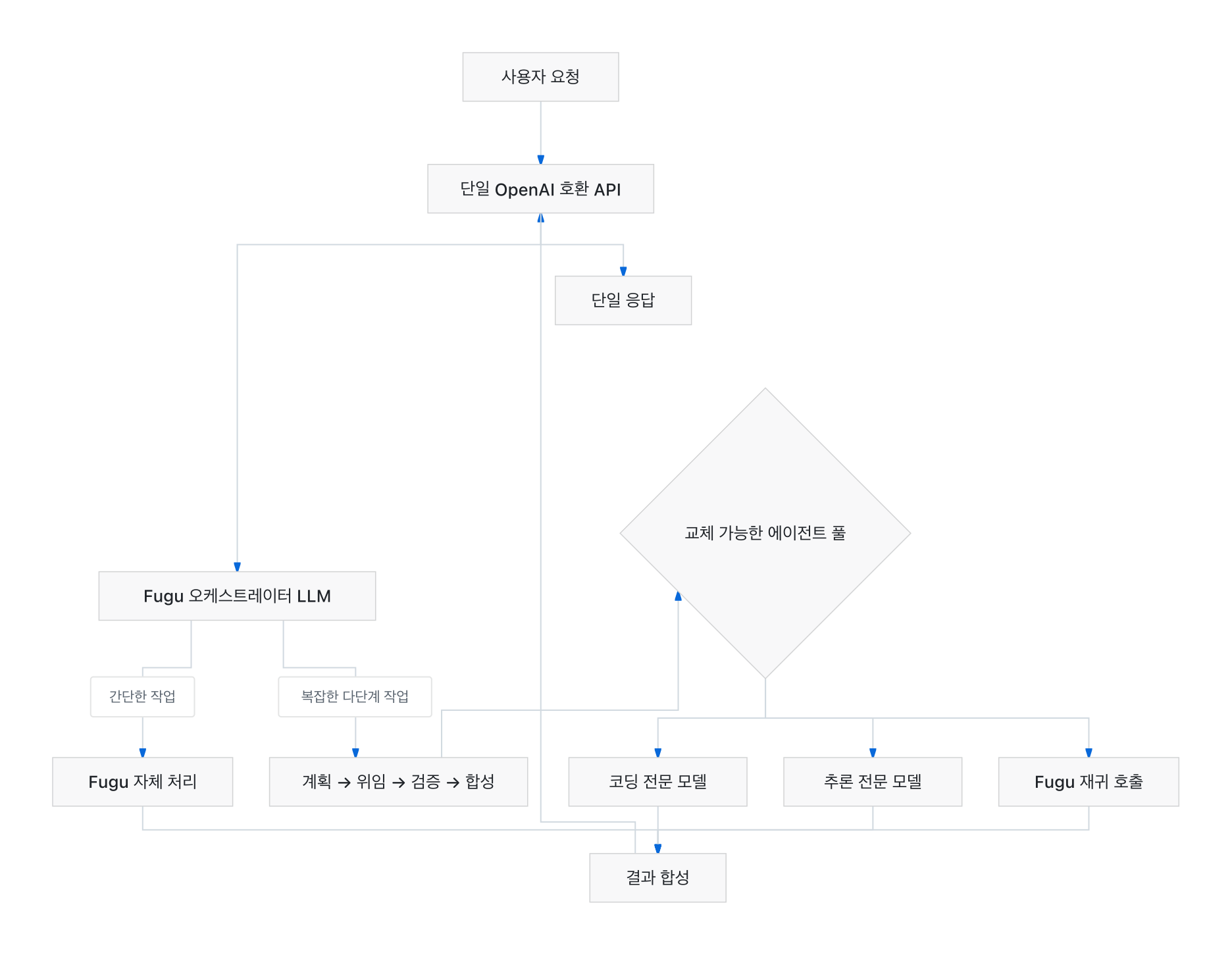
This is possible because Fugu is not a set of routing rules but a language model trained on orchestration itself. Fugu is specialized to understand when to delegate, how agents should communicate, and how to synthesize their outputs into a single trustworthy answer. The approach draws on two Sakana AI papers accepted at ICLR 2026: TRINITY (arXiv:2512.04695), which introduces an evolved LLM coordinator, and Conductor (arXiv:2512.04388), which studies learning to orchestrate agents in natural language.
One design detail worth noting: Fugu can recursively call its own instances within the agent pool. From the outside, you are calling one model; from the inside, a coordinated system of specialists is doing the work. The agent pool is designed to be swappable, with the stated goal of reducing dependence on any single provider.
Architecture: A Collaborative Ecosystem Behind a Single API
Fugu’s central claim is that “the orchestration model is the next frontier.” Since its founding, Sakana AI has argued that the most capable AI systems will be collaborative ecosystems, not isolated giant models. Fugu is the product manifestation of that belief.
Technically, Fugu handles four internal stages within a single API call:
- Selection: It reads the nature of the request and decides whether to handle it directly or which specialist models to engage.
- Delegation: It separates planning from execution and distributes sub-tasks to the appropriate agents.
- Verification: It checks each agent’s output internally.
- Synthesis: It combines the results into a single coherent answer.
All of this happens behind one line of OpenAI-compatible API. This contrasts with conventional multi-agent frameworks, which push complexity – graph definitions, message routing, state management – onto the developer. Fugu is an attempt to absorb that complexity into the model weights themselves. Compared to the multi-persona agent team structure ThakiCloud already operates, Fugu takes one step further: it makes the orchestrator a trained model rather than hand-written code.
Sakana AI has prior evidence for this direction. ALE-Agent, a coding orchestrator, placed 21st in a coding competition among 1,000 human experts. Fugu extends that experience into a general-purpose orchestration product.
Two Variants: Fugu and Fugu Ultra
At launch, Fugu is available in two variants sized for different workloads. Both are accessed through a single OpenAI-compatible API.
Fugu (standard) balances performance with low latency. It is a sensible default for interactive services such as coding assistance, code review, and chatbots. Teams with data, privacy, or compliance requirements can exclude specific agents from the pool. This opt-out capability is meaningful for regulated industries and customers with data-sovereignty requirements.
Fugu Ultra is tuned to maximize answer quality on difficult, multi-step problems. It draws on a deeper pool of specialist agents when accuracy and depth matter most. Early users have reportedly put Fugu Ultra to work on high-demand tasks such as AI research, paper reproduction, cybersecurity analysis, and literature and patent search.
The separation of these two variants is essentially a mechanism for exposing the cost-quality trade-off to the user. Orchestration inherently involves multiple model calls, so engaging a deeper pool drives up both latency and cost. Fugu surfaces that trade-off as two product lines.
How to Read the Benchmarks
Sakana AI announced that Fugu Ultra performs “shoulder-to-shoulder” with leading models such as Anthropic’s Fable 5 and Mythos Preview on challenging engineering, science, and reasoning benchmarks. That claim requires careful reading.
First, every baseline score other than Fugu’s own numbers comes from the respective model provider’s self-reports. This is not an independently controlled apples-to-apples comparison; it is a collection of self-announced figures. Second, the comparison targets – Fable 5 and Mythos Preview – are not publicly available and are not included in Fugu’s agent pool. Fugu is claiming near-parity with models it does not internally call. Third, the SWE-family tasks were scored using mini-swe-agent scaffolding. The choice of scaffolding materially affects results, so these cannot be treated as equivalent conditions.
At this point, the proposition that “Fugu Ultra is on par with frontier models” should be treated as a self-reported claim. The specific figures are compiled in Sakana AI’s technical report (github.com/SakanaAI/fugu), but until independent third-party verification accumulates, distinguishing marketing numbers from validated performance is prudent. This post does not cite individual unverified scores; it records only the nature of the claims.
Implications for ThakiCloud’s K8s AI/ML SaaS Platform
The questions Fugu raises map precisely onto ThakiCloud’s platform strategy. ThakiCloud operates multi-tenant agents across diverse customer environments, running an agent operations cloud called Praxis on top of K8s, Kueue-based GPU scheduling, and vLLM serving. The thesis Fugu is trying to prove – that “the orchestration layer itself becomes the product” – is the same direction we are already pursuing.
The core is hedging vendor lock-in. Sakana AI cited the risk of dependence on a single provider as the justification for launching Fugu. As the export-control episode around Anthropic’s Fable and Mythos models illustrated, regulatory boundaries or diplomatic policy shifts can change access to a specific API overnight. In critical sectors such as government, finance, and infrastructure, depending on a single company’s API is a real vulnerability. This logic is the same reason ThakiCloud has emphasized on-premises and self-hosting.
From ThakiCloud’s perspective, Fugu’s design offers two uses. First, it is valuable as a reference implementation of orchestration patterns. The structure of dynamically routing self-hosted open models on K8s – combining coding, reasoning, and domain-specialized models by task type – is an idea that maps directly onto Praxis agent operations. Second, opt-out-based compliance: the ability to exclude specific agents from the pool connects naturally to policies that restrict the set of permitted models per tenant in a multi-tenant environment.
Where ThakiCloud can differentiate from Fugu is clear, however. Fugu is a closed API; ThakiCloud offers a path to self-hosting the orchestration layer inside the customer’s own environment. For domestic customers that must address sovereignty, cost efficiency, and national-security requirements, the option to “put the orchestration inside our own cluster” is a decisive difference. Fine-tuning an open model at the level of Qwen3 for a specific domain, then self-hosting the orchestration layer on top of it, can deliver strong competitiveness at lower serving cost.
Limits and Counterarguments
Fugu is an interesting product, but its marketing logic has several points worth scrutinizing.
The biggest contradiction is that it creates a new dependency while claiming to reduce vendor lock-in. Fugu is a closed commercial API; it is not open-weight. A product launched on the logic that single-provider dependence is dangerous in turn requires dependence on a new single provider: Sakana AI. The fact that Fugu is not available in the EU/EEA at launch also demonstrates that this product, too, is subject to regulation and regional policy. Genuine vendor-lock-in hedging is only possible with self-hostable orchestration.
Second, cost and latency are unpredictable. A structure in which a model calls other models – and sometimes itself recursively – makes it hard to forecast how many model calls a single request will trigger internally. Modes like Fugu Ultra that engage deeper pools can deliver higher quality, but cost and latency may spike accordingly. For production teams managing SLAs and budgets, controlling this unpredictability is the key challenge.
Third, verification and debugging are harder. The fact that the internal delegation path is embedded in model weights is an advantage for ease of use, but it means that when a wrong answer appears, tracing which agent’s judgment caused the problem is difficult. In operational environments where observability matters, this opacity is a liability.
Fourth, as noted earlier, the performance claims are still at the self-reported stage. The comparison targets are non-public models not included in the pool, and the baselines are provider self-reports. Reserving judgment until independent reproduction and verification accumulate is the rational response.
Despite these reservations, the question Fugu raises – “Can orchestration be a learned capability rather than hand-written code?” – is one every multi-agent platform operator will have to face. ThakiCloud intends to answer that question with self-hostable, observable orchestration as its differentiator.
Sources
- Sakana AI, “Sakana Fugu: One Model to Command Them All”, 2026-06-22, sakana.ai/fugu-release
- Sakana Fugu Technical Report, Fugu Team, Sakana AI, 2026, github.com/SakanaAI/fugu
- Xu et al., “TRINITY: An Evolved LLM Coordinator”, ICLR 2026, arXiv:2512.04695
- Nielsen et al., “Learning to Orchestrate Agents in Natural Language with the Conductor”, ICLR 2026, arXiv:2512.04388
- THE DECODER, “Sakana AI’s Fugu orchestrates multiple LLMs to match Anthropic’s Fable and Mythos benchmarks”, 2026-06-22, the-decoder.com