Micron-Anthropic Partnership: Memory Becomes the Battleground of AI Infrastructure
Overview
The center of gravity in the AI race has been shifting from models to infrastructure, and within infrastructure, from compute to memory. GPU compute capacity has grown rapidly, but the real practical bottleneck for large language model inference has become how quickly data can be fed to that compute, which is to say, memory bandwidth.
On June 22, 2026, memory semiconductor company Micron and AI company Anthropic announced a strategic partnership. This goes well beyond a simple component supply contract: it bundles a multi-year supply agreement, co-design of memory and storage architecture for AI workloads, and an equity investment into a single comprehensive alliance. The partnership signals that memory is no longer a passive component but an active variable in AI system design.
This post reads the partnership through the lens of infrastructure technology rather than stock market reaction. It covers why memory has become the battleground of AI infrastructure, what co-designing memory and storage changes, and the implications for ThakiCloud as an operator of a K8s-based AI/ML serving platform.
What Happened
The core of the announced partnership has three components.
First, a multi-year supply agreement. Micron will supply Anthropic with high-bandwidth memory (HBM), DRAM, and solid-state drives (SSD), the key products for data center use. This is a long-term contract to secure stable supply volumes, not a one-off purchase.
Second, co-design of memory and storage architecture. The two companies agreed to jointly design memory and storage architectures optimized for AI workloads. In other words, this is a collaboration to align memory configuration and data paths with Anthropic’s model training and inference patterns. This is the aspect that most clearly distinguishes the deal from a plain supply contract.
Third, strategic equity investment. Micron made a strategic investment in Anthropic’s Series H funding round. The investment amount was not disclosed. Through this round, Anthropic was valued at approximately $965 billion [estimated], becoming the most valuable private AI company, with Samsung, SK hynix, Altimeter Capital, Sequoia, and Amazon among the reported participants. The agreement also includes deploying Claude across Micron’s internal operations.
Micron’s stock rose roughly 5.5% immediately after the announcement. The focus of this post, however, is not the share price but the technical implications this alliance carries for AI infrastructure design.
Why Memory Is the Bottleneck in AI Infrastructure
Inference for large language models is fundamentally a memory-bound workload. Every time a token is generated, the model’s full set of weights must be read from memory. No matter how fast the compute units are, if weights cannot be supplied quickly enough, the GPU sits idle waiting for data. As a result, inference throughput is often determined by memory bandwidth rather than compute capacity.
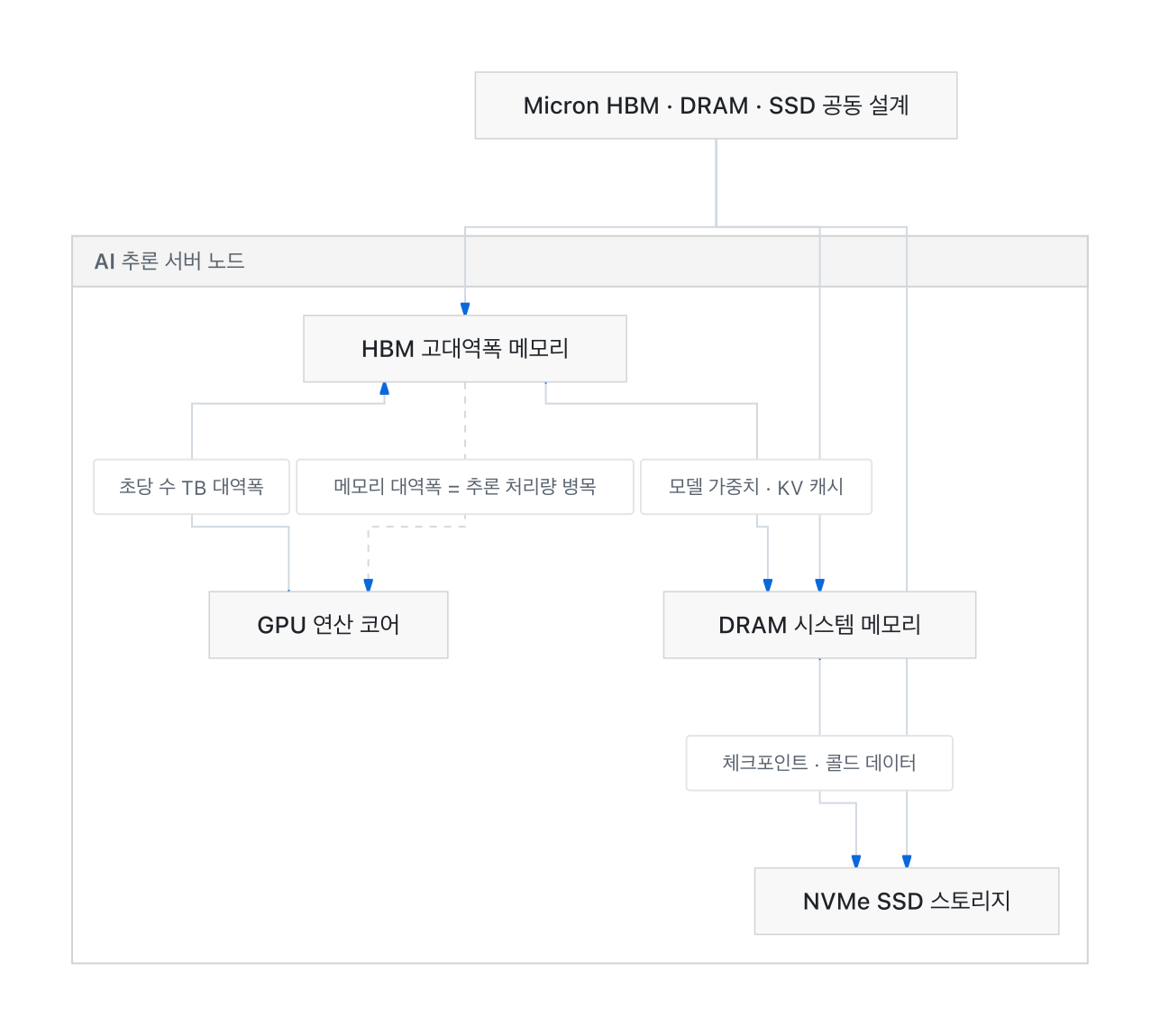
The memory hierarchy of an AI inference server is structured as shown in the diagram above.
- HBM (High-Bandwidth Memory): The ultra-fast memory closest to the GPU. It delivers bandwidth on the order of terabytes per second and holds active model weights and the KV cache. HBM is the direct bottleneck for inference throughput.
- DRAM (System Memory): Larger capacity than HBM but slower. Used to swap weights that do not fit in HBM or to hold larger contexts.
- SSD (Storage): Slowest but largest in capacity. Hosts model checkpoints, cold data, and an ever-growing share of KV cache offloading.
When a single company supplies the entire hierarchy, it becomes possible to optimize data movement across all layers under a coherent design philosophy. The fact that Micron covers HBM, DRAM, and SSD is the key strategic asset in this partnership.
What Co-Designing Memory and Storage Changes
Until now, memory has largely been purchased as a commodity to a standard specification. The noteworthy aspect of this partnership is that Micron and Anthropic will co-design memory and storage architectures tailored to AI workloads. This implies several shifts.
First, the data access patterns of inference and training can be directly reflected in memory design. For example, efficient paths for offloading the KV cache from HBM to DRAM or SSD, and structures that reduce the cost of crossing memory hierarchy boundaries during long-context processing, are problems that are better solved when the model provider and the memory provider design together.
Second, the partnership shows that AI infrastructure is becoming increasingly vertically integrated. It is a signal that frontier AI companies are trying to secure not just GPUs but also memory at the supply chain and design stage. The participation of memory companies like Samsung and SK hynix in the same Series H round can be read in the same light. Memory supply capability is being incorporated as part of AI competitiveness.
ThakiCloud K8s AI/ML SaaS Platform Perspective
This is a deal between large companies, but it carries direct lessons for ThakiCloud as an operator of a K8s-based AI/ML serving platform.
First, it reconfirms that memory is the starting point for serving cost optimization. ThakiCloud runs multi-tenant inference on top of vLLM and Kueue-based GPU scheduling. In this environment, the most effective lever for increasing throughput is often memory utilization, not compute. KV cache management, batching strategies, and model placement calibrated to HBM capacity are the key techniques for handling more concurrent requests on the same GPU. The reason technologies like vLLM’s PagedAttention receive attention ultimately comes down to memory efficiency.
Second, there is the economics of on-premises AI infrastructure. The trend of frontier companies securing memory as a strategic asset paradoxically highlights the value of on-premises self-hosting. When customers serve models on their own GPU and memory, the ability to tune the memory hierarchy to the workload determines total cost of ownership (TCO). ThakiCloud can provide more predictable and efficient inference costs than cloud API dependency by optimizing model placement and memory configuration within customer clusters.
Third, there is the sovereignty and supply chain perspective. The fact that memory has become the battleground of AI competition prompts a rethinking of the vulnerabilities in structures where domestic customers simultaneously depend on external clouds and external supply chains. Demand for keeping data and infrastructure in-house through on-premises and self-hosting, especially in domains subject to national security or regulatory requirements, strengthens in this context.
Caveats and Counter-Arguments
To avoid over-interpreting this partnership, several points deserve attention.
First, a substantial portion of the public information remains at the press release level. What specific technical outputs the co-design of memory and storage architecture will produce, and the amounts of investment and supply volumes involved, have not been disclosed. The practical impact of the partnership therefore needs to be confirmed through future products and data; assessment at this point is closer to an interpretation of direction.
Second, it is important to distinguish between commercial and financial motivations and technical significance. The equity investment and internal Claude deployment are mechanisms to strengthen business ties; they do not in themselves guarantee advances in memory technology. Figures like the $965 billion [estimated] valuation or the stock price gain reflect market expectations and do not connect directly to infrastructure performance.
Third, while the premise that memory bandwidth is the bottleneck holds broadly across inference workloads, it does not apply equally in all cases. With smaller models, high batch throughput, or compute-intensive stages, compute can be the bottleneck. The simplification that “more memory solves everything” should be resisted; measuring the bottleneck empirically for each workload and responding accordingly is the correct approach.
In conclusion, the Micron-Anthropic partnership is a meaningful signal that competition in AI infrastructure is expanding beyond compute to the entire memory hierarchy. ThakiCloud intends to use this trend as a foundation for strengthening our strengths in memory-efficient serving and on-premises economics.
Sources
- Micron Technology, “Micron and Anthropic Announce Strategic Agreement to Scale Next-Generation AI Infrastructure”, 2026-06-22, investors.micron.com
- Yahoo Finance, “Micron and Anthropic Announce Strategic Agreement to Scale Next-Generation AI Infrastructure”, 2026-06-22, finance.yahoo.com
- Crypto Briefing, “Micron signs supply agreement with Anthropic AI, invests in Series H round”, 2026-06-22, cryptobriefing.com