Sakana Fugu: 모델이 모델을 지휘하는 오케스트레이션 시대
개요
지난 몇 년간 AI의 발전은 대체로 규모의 힘으로 이루어졌습니다. 더 큰 모델을 더 많은 데이터로 학습시키는 단일 거대 모델(monolith) 경쟁이 중심이었습니다. 그러나 현실의 어려운 문제는 단일 벤치마크 점수를 훨씬 넘어서는 다양한 지식과 기술을 동시에 요구합니다. 어떤 작업에 어떤 모델이 적합한지 판단하고, 계획과 실행을 나누어 위임하며, 각 모델의 강점을 조합하는 능력, 즉 집단 지성(collective intelligence)이 다음 경쟁의 축으로 떠오르고 있습니다.
2026년 6월 22일, 도쿄에 본사를 둔 Sakana AI가 이 흐름을 정면으로 겨냥한 제품 Sakana Fugu를 공개했습니다. Fugu는 여러 LLM을 동적으로 조율하는 멀티에이전트 시스템이지만, 사용자에게는 단일 모델 API처럼 보입니다. 흥미로운 점은 Fugu 자체가 “다른 모델을 호출하도록 학습된 언어 모델”이라는 것입니다. 모델이 모델을 지휘합니다.
이 글은 멀티테넌트 에이전트 플랫폼을 운영하는 ThakiCloud의 관점에서 Fugu의 구조를 분석합니다. 오케스트레이션을 하나의 모델로 패키징한다는 설계가 왜 중요한지, 자체 발표 벤치마크를 어떻게 읽어야 하는지, 그리고 벤더 종속(vendor lock-in)을 줄인다는 이 제품의 마케팅 논리에 어떤 모순이 숨어 있는지를 함께 짚겠습니다.
이 기술은 무엇인가
Sakana Fugu는 단일 모델처럼 동작하는 멀티에이전트 시스템입니다. 사용자가 하나의 엔드포인트로 요청을 보내면 Fugu가 처리 방식을 스스로 결정합니다. 혼자 풀어도 충분한 요청은 직접 처리하고, 더 복잡한 작업은 전문 모델들로 구성된 팀을 꾸려 조율합니다. 모델 선택, 위임, 검증, 합성이 모두 내부에서 일어나기 때문에, 멀티에이전트 시스템의 복잡성이 사용자 코드까지 노출되지 않습니다.
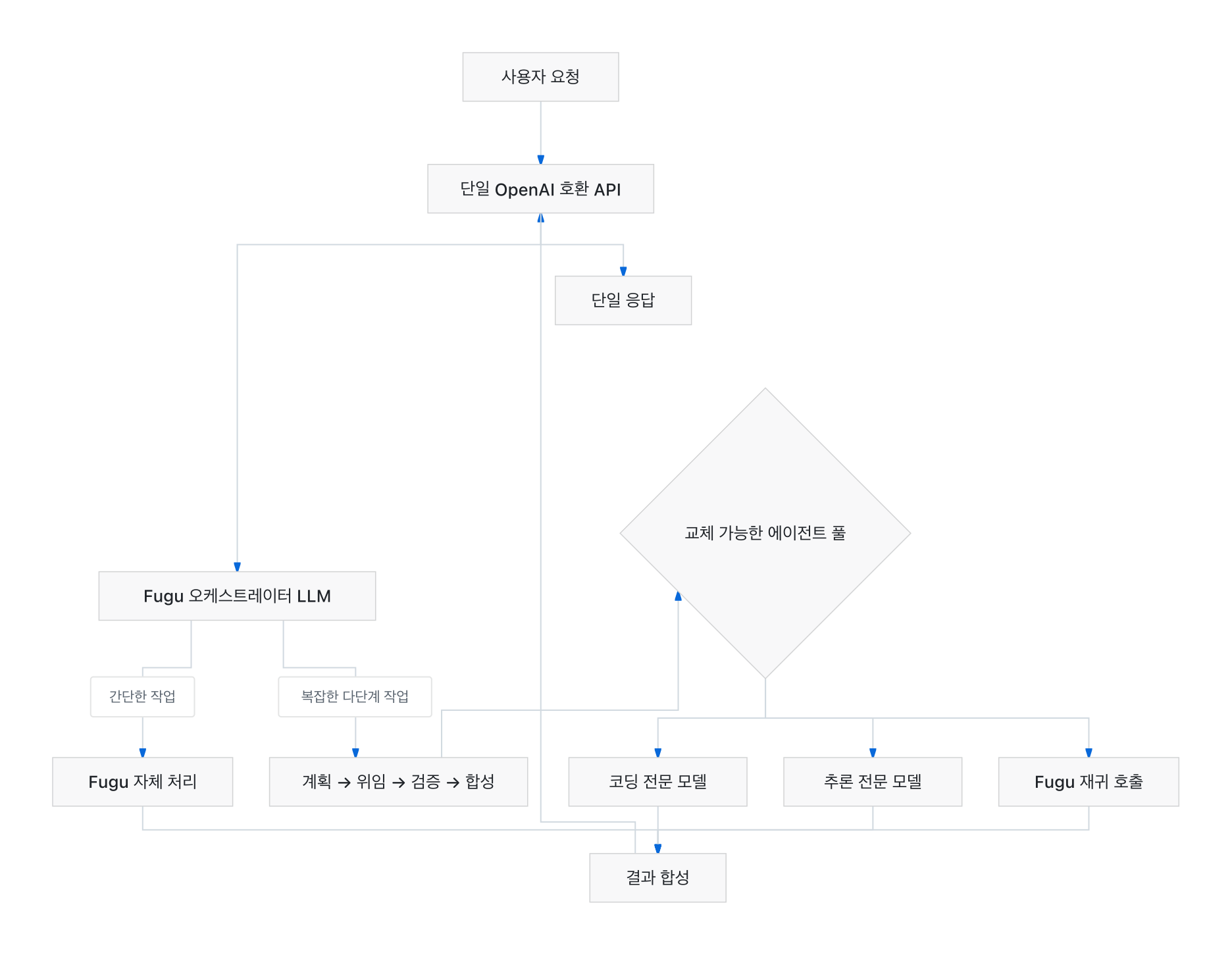
이 구조가 가능한 이유는 Fugu가 단순한 라우팅 규칙이 아니라 오케스트레이션 자체를 학습한 언어 모델이기 때문입니다. Fugu는 언제 위임해야 하는지, 에이전트들이 어떻게 소통해야 하는지, 그리고 그 결과를 어떻게 하나의 신뢰할 수 있는 답으로 합성하는지를 이해하도록 특화되어 있습니다. 이 접근은 Sakana AI가 ICLR 2026에 발표한 두 편의 연구, 즉 진화적 LLM 코디네이터를 다룬 TRINITY(arXiv:2512.04695)와 자연어로 에이전트를 조율하는 법을 학습한 Conductor(arXiv:2512.04388)에 기반을 두고 있습니다.
특히 눈에 띄는 설계는 Fugu가 에이전트 풀 안에서 자기 자신의 인스턴스를 재귀적으로 호출할 수 있다는 점입니다. 외부에서 보면 하나의 모델을 호출하는 것이지만, 내부에서는 전문가들로 구성된 조율 시스템이 작업을 수행하는 셈입니다. 에이전트 풀은 교체 가능(swappable)하도록 설계되어, 특정 공급자에 대한 의존을 줄이는 것을 목표로 합니다.
아키텍처: 단일 API 뒤의 협업 생태계
Fugu의 핵심 주장은 “오케스트레이션 모델이 다음 프런티어”라는 것입니다. Sakana AI는 창업 이래 가장 강력한 AI 시스템은 고립된 거대 모델이 아니라 협력하는 생태계가 될 것이라는 신념을 밝혀 왔습니다. Fugu는 이 신념을 제품으로 구현한 결과입니다.
기술적으로 Fugu는 다음 네 가지 내부 단계를 한 번의 API 호출 안에서 처리합니다.
- 선택(Selection): 요청의 성격을 파악해 직접 처리할지, 어떤 전문 모델을 동원할지 결정합니다.
- 위임(Delegation): 계획과 실행을 분리해 적절한 에이전트에게 하위 작업을 배분합니다.
- 검증(Verification): 각 에이전트의 결과를 내부적으로 점검합니다.
- 합성(Synthesis): 여러 결과를 하나의 일관된 답으로 통합합니다.
이 모든 과정이 OpenAI 호환 API 한 줄 뒤에서 일어납니다. 기존의 멀티에이전트 프레임워크가 개발자에게 그래프 정의, 메시지 라우팅, 상태 관리 같은 복잡성을 떠넘겼던 것과 대비됩니다. Fugu는 그 복잡성을 모델 가중치 안으로 흡수하려는 시도입니다. ThakiCloud가 이미 운영 중인 멀티페르소나 에이전트팀 구조와 비교하면, Fugu는 “오케스트레이터를 별도 코드가 아니라 학습된 모델로 만든다”는 점에서 한 걸음 더 나아간 접근으로 볼 수 있습니다.
Sakana AI는 이 방향에서 이미 실적을 보여 준 바 있습니다. 코딩 오케스트레이터인 ALE-Agent는 1,000명의 인간 전문가가 참가한 코딩 대회에서 21위를 기록했습니다. Fugu는 그 경험을 일반 목적 오케스트레이션 제품으로 확장한 결과물입니다.
두 가지 변형: Fugu와 Fugu Ultra
출시 시점에 Fugu는 워크로드에 맞춰 고를 수 있는 두 가지 모델로 제공됩니다. 둘 다 단일 OpenAI 호환 API로 접근합니다.
Fugu(기본)는 성능과 낮은 지연(latency)의 균형에 초점을 둡니다. 코딩과 코드 리뷰, 챗봇 같은 인터랙티브 서비스의 기본값으로 적합합니다. 데이터·프라이버시·컴플라이언스 요건이 있는 팀은 특정 에이전트를 풀에서 제외할 수 있습니다. 이 옵트아웃 기능은 규제 산업이나 주권(sovereignty) 요건이 있는 고객에게 의미가 큽니다.
Fugu Ultra는 어려운 다단계 문제에서 답변 품질을 극대화하도록 조정되어 있습니다. 정확도와 깊이가 중요할 때 더 두터운 전문 에이전트 풀을 동원합니다. 초기 사용자들은 AI 연구, 논문 재현, 사이버보안 분석, 문헌·특허 조사처럼 부하가 높은 작업에 Fugu Ultra를 활용했다고 합니다.
이 두 변형의 분리는 본질적으로 비용-품질 트레이드오프를 사용자가 선택하게 만드는 장치입니다. 오케스트레이션은 본질적으로 여러 모델 호출을 동반하므로, 깊은 풀을 동원할수록 지연과 비용이 함께 올라갑니다. Fugu는 이 트레이드오프를 두 개의 제품 라인으로 노출했습니다.
벤치마크는 어떻게 읽어야 하는가
Sakana AI는 Fugu Ultra가 엔지니어링·과학·추론 분야의 까다로운 벤치마크에서 Anthropic의 Fable 5, Mythos Preview 같은 선도 모델과 “어깨를 나란히 한다”고 발표했습니다. 그러나 이 주장은 신중하게 읽어야 합니다.
첫째, Fugu의 점수를 제외한 모든 베이스라인 점수는 각 모델 공급자가 공표한 값입니다. 동일한 조건에서 독립적으로 측정한 비교가 아니라, 자체 발표 수치를 모아 놓은 비교입니다. 둘째, 비교 대상인 Fable 5와 Mythos Preview는 일반에 공개되어 있지 않아 Fugu의 에이전트 풀에 포함되어 있지 않습니다. 즉 Fugu는 이 두 모델을 내부적으로 호출하지 않으면서도 그 점수에 근접한다고 주장하는 것입니다. 셋째, SWE 계열 작업의 채점에는 mini-swe-agent 스캐폴딩이 사용되었습니다. 스캐폴딩의 종류는 결과에 큰 영향을 미치므로, 동일 조건 비교로 보기는 어렵습니다.
따라서 현 시점에서 “Fugu Ultra가 프런티어 모델과 동급”이라는 명제는 자체 발표 기반의 주장으로 취급하는 것이 정확합니다. 구체적인 수치는 Sakana AI가 공개한 기술 보고서(github.com/SakanaAI/fugu)에 정리되어 있으나, 제3자 검증이 누적되기 전까지는 마케팅 수치와 검증된 성능을 구분하는 신중함이 필요합니다. 이 글에서는 검증되지 않은 개별 점수를 인용하지 않고, 주장의 성격만 기록합니다.
ThakiCloud K8s AI/ML SaaS 플랫폼 적용 및 시사점
Fugu가 던지는 화두는 ThakiCloud의 플랫폼 전략과 정확히 겹칩니다. ThakiCloud는 다양한 고객 환경에서 멀티테넌트 에이전트를 운영하며, K8s와 Kueue 기반 GPU 스케줄링, vLLM 서빙 위에 에이전트 운영 클라우드 Praxis를 올려 두고 있습니다. Fugu가 증명하려는 명제, 즉 “오케스트레이션 레이어 자체가 제품이 된다”는 주장은 우리가 이미 추구하는 방향과 같습니다.
핵심은 벤더 종속의 헤지입니다. Sakana AI는 Fugu의 출시 명분으로 단일 공급자 의존의 위험을 들었습니다. Anthropic의 Fable·Mythos 모델에 부과된 수출 통제 사례처럼, 규제 경계나 외교 정책 변화로 특정 API에 대한 접근이 하룻밤 사이에 바뀔 수 있다는 것입니다. 정부·금융·인프라처럼 중요한 영역에서 단일 회사의 API에 의존하는 것은 실질적 취약점입니다. 이 논리는 ThakiCloud가 온프레미스와 self-hosting을 강조해 온 이유와 동일합니다.
ThakiCloud 관점에서 Fugu의 설계는 두 가지로 활용할 수 있습니다. 첫째, 오케스트레이션 패턴의 참조 구현으로서 가치가 있습니다. 자체 호스팅한 오픈 모델들을 K8s 위에서 동적으로 라우팅하고, 작업 성격에 따라 코딩·추론·도메인 특화 모델을 조합하는 구조는 Praxis 에이전트 운영에 그대로 이식할 수 있는 아이디어입니다. 둘째, 옵트아웃 기반 컴플라이언스입니다. 특정 에이전트를 풀에서 제외하는 기능은 멀티테넌트 환경에서 테넌트별로 허용 모델을 제한하는 정책과 자연스럽게 연결됩니다.
다만 ThakiCloud가 Fugu와 차별화할 수 있는 지점은 분명합니다. Fugu는 닫힌 API이지만, ThakiCloud는 오케스트레이션 자체를 고객 환경 안에서 self-hosting할 수 있는 경로를 제공합니다. 주권과 비용 효율, 국가 보안 요건에 대응해야 하는 국내 고객에게는 “오케스트레이션을 우리 클러스터 안에 둔다”는 선택지가 결정적 차이가 됩니다. Qwen3 수준의 오픈 모델을 도메인에 맞춰 파인튜닝하고, 그 위에 오케스트레이션 레이어를 self-host한다면 낮은 서빙 비용에서 충분한 경쟁력을 확보할 수 있습니다.
한계 및 반론
Fugu는 흥미로운 제품이지만, 그 마케팅 논리에는 검토할 지점이 적지 않습니다.
가장 큰 모순은 벤더 종속을 줄인다면서 새로운 종속을 만든다는 점입니다. Fugu는 닫힌 상용 API로 제공되며 오픈웨이트가 아닙니다. 단일 공급자 의존이 위험하다는 논리로 출시된 제품이, 정작 Sakana AI라는 또 다른 단일 공급자에 대한 의존을 요구합니다. EU/EEA에서는 출시 시점에 제공되지 않는다는 점도, 결국 이 제품 역시 규제와 지역 정책의 영향을 받는다는 사실을 보여 줍니다. 진정한 벤더 종속 헤지는 self-hostable한 오케스트레이션에서만 가능합니다.
둘째, 비용과 지연의 불확실성입니다. 모델이 다른 모델들을 호출하고 때로는 자기 자신을 재귀적으로 호출하는 구조는, 하나의 요청이 내부적으로 몇 번의 모델 호출을 유발할지 예측하기 어렵게 만듭니다. Fugu Ultra처럼 깊은 풀을 동원하는 모드는 품질은 높지만 비용과 지연이 함께 치솟을 수 있습니다. 프로덕션에서 SLA와 예산을 관리해야 하는 입장에서는, 이 불확실성을 어떻게 통제할지가 관건입니다.
셋째, 검증과 디버깅의 난이도입니다. 내부 위임 경로가 모델 가중치 안에 감추어져 있다는 것은 사용 편의성에는 이점이지만, 잘못된 답이 나왔을 때 어느 에이전트의 어떤 판단이 문제였는지 추적하기 어렵다는 뜻이기도 합니다. 관측 가능성(observability)이 중요한 운영 환경에서는 이 불투명성이 부담이 될 수 있습니다.
넷째, 앞서 짚었듯 성능 주장이 아직 자체 발표 단계입니다. 비교 대상이 풀에 포함되지 않은 비공개 모델이고, 베이스라인이 공급자 자체 보고치라는 점에서, 독립적인 재현과 검증이 누적되기 전까지는 결론을 유보하는 것이 합리적입니다.
그럼에도 Fugu가 제기한 질문, 즉 “오케스트레이션을 별도 코드가 아니라 학습된 능력으로 만들 수 있는가”는 멀티에이전트 플랫폼을 운영하는 모두가 마주할 질문입니다. ThakiCloud는 이 질문에 대해 self-hostable하고 관측 가능한 오케스트레이션이라는 답으로 차별화를 이어 가고자 합니다.
출처
- Sakana AI, “Sakana Fugu: One Model to Command Them All”, 2026-06-22, sakana.ai/fugu-release
- Sakana Fugu Technical Report, Fugu Team, Sakana AI, 2026, github.com/SakanaAI/fugu
- Xu et al., “TRINITY: An Evolved LLM Coordinator”, ICLR 2026, arXiv:2512.04695
- Nielsen et al., “Learning to Orchestrate Agents in Natural Language with the Conductor”, ICLR 2026, arXiv:2512.04388
- THE DECODER, “Sakana AI’s Fugu orchestrates multiple LLMs to match Anthropic’s Fable and Mythos benchmarks”, 2026-06-22, the-decoder.com