A Pinch of Human Data Is Enough: Anchoring Self-Play Driving Policies to People via Regularization
Overview
As simulation makes experience essentially free to generate, one question keeps getting sharper: how much human data, and in what form, is actually worth using? In driving-policy learning this question is tied directly to cost. Collecting human driving demonstrations at scale is expensive and slow, while self-play inside a simulator is cheap and nearly unlimited.
A paper from NYU, Princeton, and collaborators, “Human-like autonomy emerges from self-play and a pinch of human data” (arXiv:2606.19370, June 2026), gives a crisp answer. As the title says, a pinch is enough. Concretely, just 30 minutes of human driving data, 2500x less than imitation learning, yields a more human-compatible policy. The entire training run finishes in 15 hours on a single consumer-grade GPU.
This article does more than report a driving result. From the perspective of a platform like ThakiCloud, which must train and align many agents in a multi-tenant environment, we examine why this design, “keep cheap synthetic experience as the main engine and apply expensive human signal only as a small regularization anchor,” aligns so well with our cost model.
📄 Full deep review (DOCX): Download the detailed peer review on Google Drive.
What This Research Is
Pure self-play reinforcement learning can train driving policies without any human data. The problem appears when the reward is only “reach the destination safely.” Under such a sparse reward, the policy converges on conventions that are effective but alien to humans. If reaching the goal by reversing, sideways, or even driving against traffic does not violate the reward, the model will happily do exactly that, because filling the reward is all that matters.
Prior fixes meant carefully engineering rewards or deploying domain randomization. Both are labor-intensive and brittle. This paper flips the idea. Instead of using human data as the main learning signal, it turns a behavioral cloning (BC) anchor policy into a regularization term. The reward stays minimal and sparse (+1 for reaching the goal, -1 for a collision or going off-road, 0 otherwise), and a KL term toward the anchor policy is added to the PPO loss. The strength is controlled by λ; when λ is 0 it reduces to plain self-play with no regularization.
The full structure is shown below. A cheap self-play engine is the main driver, and a 30-minute human anchor pulls the policy gently toward people through the thin string of KL regularization.
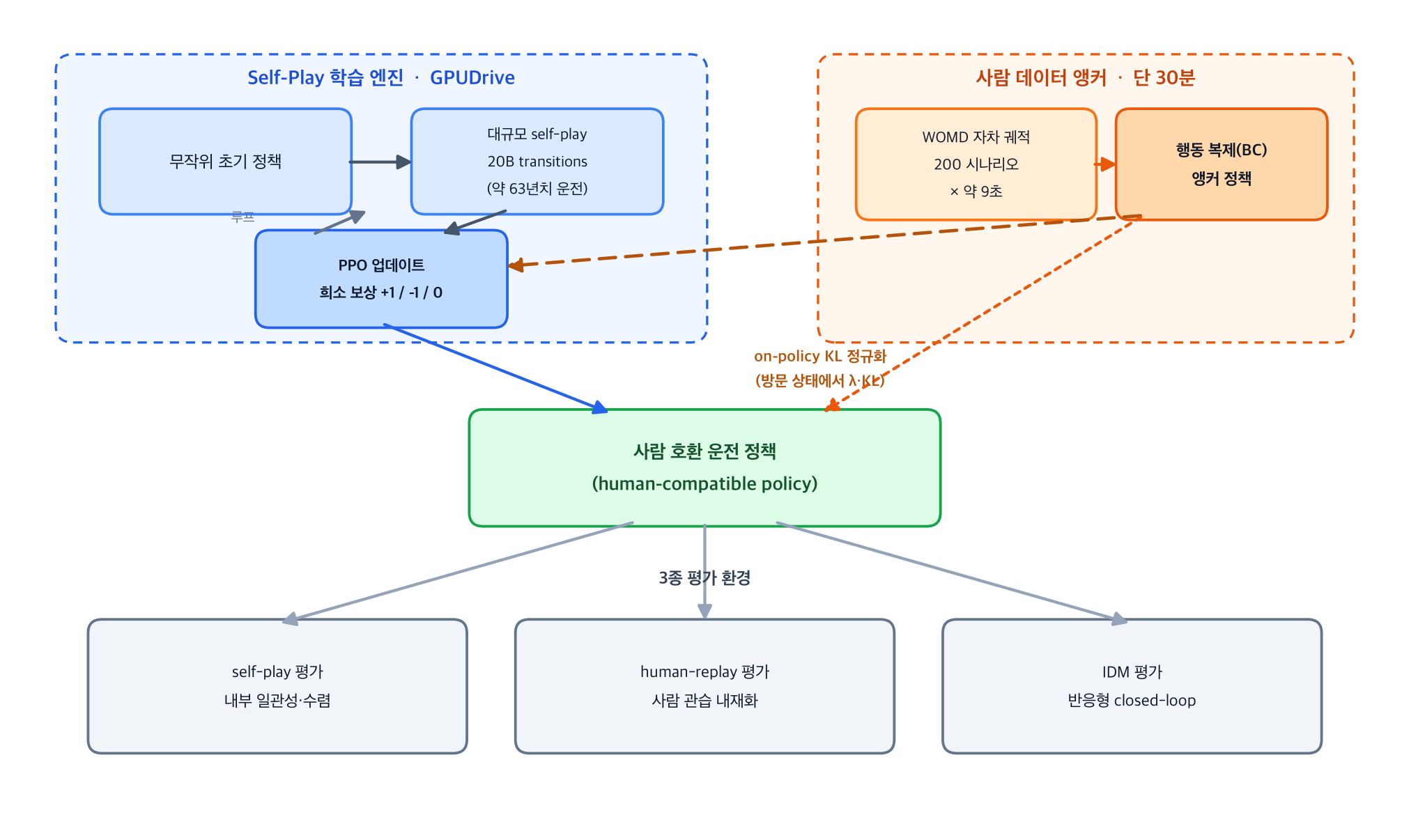
One design decision deserves emphasis. This KL term pulls the policy toward the anchor not on the offline logged data distribution but on the states the policy actually visits, which is on-policy regularization. If you regularize only on the offline BC distribution, you cannot prevent the policy from drifting away from the closed-loop state distribution it sees in practice. An on-policy KL, by contrast, draws the anchor in exactly at that distribution-shift point. It looks minor but it governs closed-loop stability.
The anchor policy itself is trained with BC on self-driving-car trajectories only. Surrounding vehicle trajectories are reconstructed by a perception stack, so they are noisy and of unguaranteed driving quality; only the cleanest signal, the ego trajectory, is used. Each scenario yields about 9 seconds of data, so 200 scenarios amount to roughly 30 minutes. The “2500x less” claim has an explicit derivation: 200 scenarios times 9 seconds is 30 minutes, while the full Waymo set of roughly 500,000 scenarios times 9 seconds is about 75,000 minutes, a ratio around 0.0004.
The Core Method: From Main Signal to Anchor
The skeleton of the method is clean. The loss is PPO’s clipped surrogate policy-gradient term plus a value loss and an entropy bonus, with a KL regularization term added on top. It is less a new algorithm than a careful combination of well-known components.
The real contribution lies not in algorithmic novelty but in the cleanliness of measurement that the infrastructure enabled. The authors scaled self-play experience to 20 billion transitions on the high-throughput simulator GPUDrive, which corresponds to roughly 63 years of human driving. Prior work was capped by simulator speed (about 2000 steps per second) at 140 million transitions and around 5 days of training, leaving no room to study scaling of human-data quantity as an independent axis. By removing the throughput bottleneck with GPUDrive, the experiment of separately scaling “self-play quantity” and “human-data quantity” became possible for the first time.
This separation reveals an interesting asymmetry. Self-play transitions are scaled up to 20 billion, while human data is already near saturation at 30 minutes. Using a 30-hour anchor changes little. The marginal utility of additional human data flattens quickly, and that is the empirical basis for the message that a pinch is enough.
Real Experimental Results
The dataset is the Waymo Open Motion Dataset (WOMD). For the human-replay evaluation that measures human compatibility, scenarios are filtered to raise the interaction signal. Among 10,000 held-out validation scenarios, the ego trajectory is scored by how much it crosses other agents’ trajectories, keeping only the top 200 interactive scenes such as merges, yields, and busy intersections that genuinely require coordination.
The core results are summarized in the chart below. Every figure is reported by the paper; none are invented.
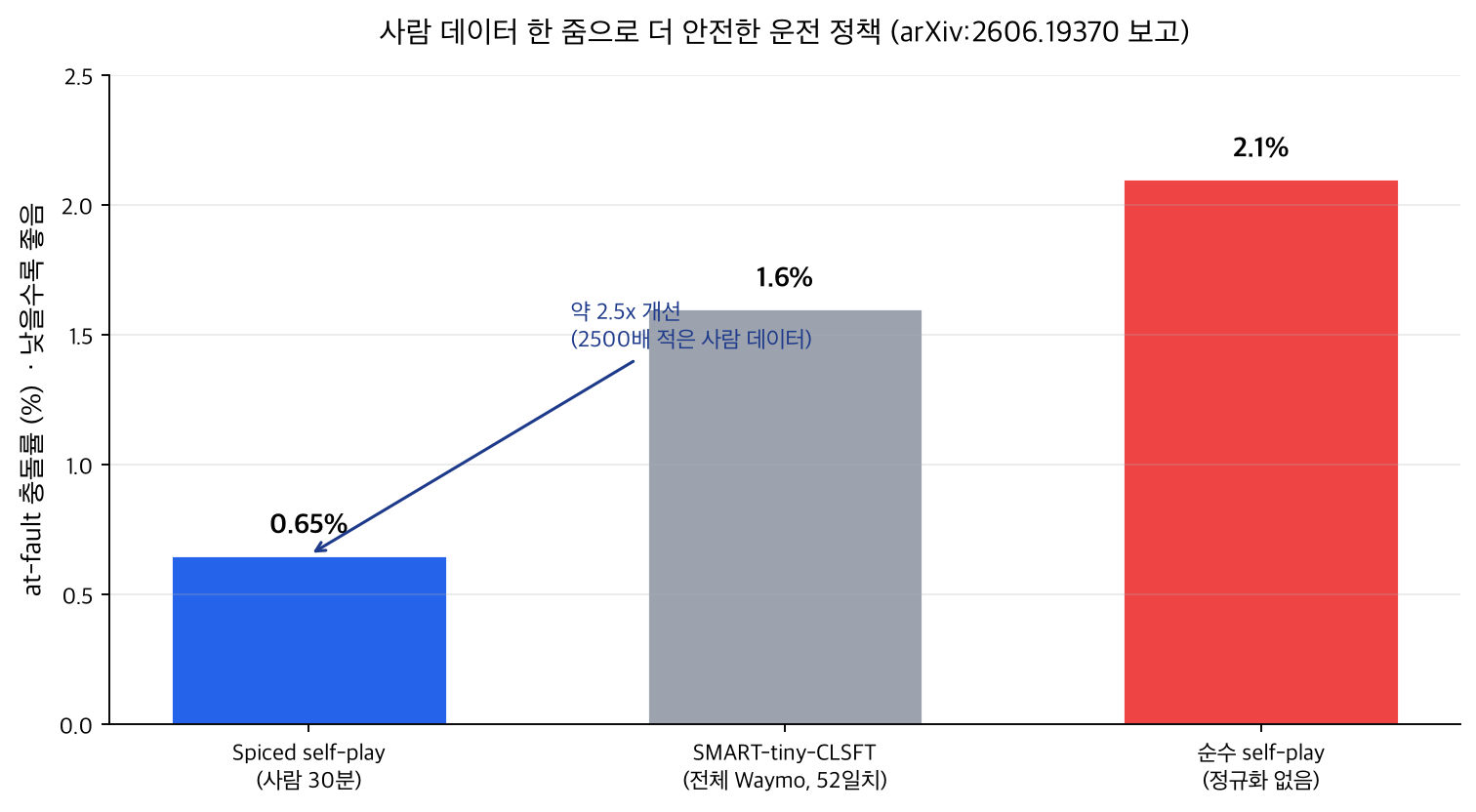
The key points are as follows.
- Spiced self-play achieves an at-fault collision rate of 0.6 to 0.7% with between 30 minutes and 3 hours of data. Compared with the imitation-learning baseline SMART-tiny-CLSFT (1.6%, trained on the full Waymo set, about 52 days of data), that is roughly a 2.5x improvement.
- Pure self-play with no regularization had an at-fault collision rate of 2.1%. Adding just a pinch of anchor made it about 3.5x safer.
- The evaluation avoids single-metric bragging. It looks at score, completion rate, collision rate, at-fault collision rate, and collision-severity Δv across three environments: self-play (all agents share the policy), human-replay (only the ego is the policy, the rest replay logs), and IDM (others are rule-based and reactive).
Internal consistency also differs. Spiced self-play keeps the collision rate below 1.5% in both the self-play environment and human-log cross-play, while the imitation-learning baseline climbs to about 6% in the self-play environment, showing weaker consistency. The authors explain that the non-stationarity of the self-play environment, a changing partner distribution where an initially near-random opponent gradually becomes competent, actually helps convergence toward mutually consistent conventions.
Not every picture is rosy, however. The Waymo Open Sim Agent Challenge (WOSAC) meta-score for distributional realism rises from 0.68 for pure self-play to 0.725 for the regularized version, but the gain is small relative to the dramatic safety improvement and is nearly insensitive to added data. A policy can be safe yet still less human-like distributionally, a point we return to below.
Application to the ThakiCloud K8s AI/ML SaaS Platform
Driving itself is not ThakiCloud’s direct domain. Yet the methodological lessons of this paper transfer almost directly to our multi-agent, reinforcement-learning, and alignment infrastructure.
First, the principle of “human data as a lightweight anchor, not the main signal” aligns with the cost model of our self-harness and agent-evolution loops. ThakiCloud already runs a pattern of “start cheap, escalate to expensive only via retrospection and verification”: run low-cost workers first and promote to a higher-tier model only when repeated failure is detected. This paper quantitatively backs the reinforcement-learning version of that pattern, where cheap synthetic experience is the main engine and expensive human demonstrations are merely a small regularization anchor. We can borrow it as a benchmark for “how little human labeling we can use while keeping alignment” in training and tuning our agent fleet.
Second, the idea of on-policy KL regularization has strong potential to combine with our fan-out verification gate. We could release many workers freely like self-play, then anchor them with a small set of human-approved golden traces under KL regularization to suppress divergence into alien conventions such as hallucination or format drift. The key is to apply the regularization not on a static offline golden set but on the states the workers actually visit, a structure worth a PoC on our platform.
Third, the asymmetry between safety metrics and distributional realism is a warning for our evaluation design. Bragging about quality with a single aggregate score hides stagnation on other axes like distributional realism. The gates should be owned by code, but the standard should be a multi-layer evaluation harness that separately measures safety, realism, and consistency rather than a single number.
Finally, there is one clear bragging point. A cost structure of 15 hours on a single consumer-grade GPU points in exactly the direction ThakiCloud has emphasized: on-premises, cost efficiency, and self-hosting. It means alignment experiments like this can be reproduced and operated at reasonable cost on our K8s stack, scheduling GPUs with Kueue and serving with vLLM, without a massive human-data pipeline.
Limitations and Counterarguments
It is a solid piece of experimental science, but read critically, three tensions remain.
The biggest weakness is that the generalization claim rests on a single domain, driving. The conclusion repeatedly hints that “the lessons may generalize beyond driving,” yet every experiment is on Waymo driving data. There is no validation in other domains where the premise “simulation is cheap and the desired-behavior metric is clear” holds, such as negotiation, cooperative games, or robotics. It falls short of the universality the title’s “emerges” suggests.
Second, the asymmetry between distributional-realism gains and safety gains is not fully explained. The WOSAC meta-score moving from 0.68 to 0.725 is modest next to the large collision-rate improvement, and it is insensitive to more data. A policy can be safe yet still less human-like distributionally, which is in tension with the strong title “human-like autonomy emerges.” The body not confronting this gap head-on leaves room for over-claiming.
Third, the limitation in the hardest coordination scenarios is quarantined in the limitations section. The authors themselves admit performance drops on the top 200 hardest interactive scenarios. If the highest-density merges and intersections, where safety matters most, are the weakest, that weakness deserves to sit next to the main result rather than be deferred. Beyond this, the sensitivity analysis of the regularization strength λ is thin, and there is insufficient examination of whether a single anchor policy captures the diversity of human driving.
In sum, rather than a new algorithm, the essence is scaling an existing idea cleanly on a high-throughput simulator to nail down “a pinch of human data is enough.” Reproducibility, multi-layer evaluation, and honest comparison with prior work are strengths; the single-domain generalization claim and the stagnation in distributional realism are weaknesses. For a platform like ours, it reads as a persuasive case for a cost model that maintains alignment while minimizing expensive human signal.
Sources
- Paper: Human-like autonomy emerges from self-play and a pinch of human data (arXiv:2606.19370), https://arxiv.org/abs/2606.19370
- Hugging Face Papers: https://hf.co/papers/2606.19370
- Project page (videos and full source): https://spiced-self-play.com/
📄 Full deep review (DOCX): Download the detailed peer review on Google Drive.