Stop Hand-Writing SKILL.md: A Deep Dive into Hermes Agent’s /learn Command
 The concept of /learn expressed as scattered knowledge fragments from multiple directions crystallizing into a single structured output.
The concept of /learn expressed as scattered knowledge fragments from multiple directions crystallizing into a single structured output.
Overview
The most common way to teach an agent a new capability has been to write a skill file by hand. A skill is ultimately just one Markdown document, but authoring it from scratch while respecting the required frontmatter and section order takes more effort than it sounds. That friction is especially real for things that live in your head but are tedious to write down - internal API usage, deployment runbooks, and repetitive procedures.
The /learn command that Nous Research added to its Hermes Agent framework on June 24, 2026, eliminates the hand-authoring step entirely. Point it at a directory, a URL, a conversation you just finished, or a pasted note, and the live agent collects the material directly using its own tools and authors a standard-compliant SKILL.md. The demo video shared on X by tonbistudio - showing multiple sources being combined into a skill - sparked a lot of attention, and since ThakiCloud already had Hermes Agent installed internally, we decided to verify it firsthand.
ThakiCloud runs multi-tenant agents on a Kubernetes-based AI/ML SaaS platform. The idea of an agent building its own procedural memory in a form that humans can gate and review maps directly onto the principle we call Thin Harness, Fat Skills: capabilities belong in skills, not in the harness. /learn lowers the barrier to creating those skills, which makes it more than a convenience feature.
What This Technology Is
/learn is not a separate ingestion engine. The key insight is that it constructs a standard-guided prompt and hands it to the agent as an ordinary single turn. Source collection therefore uses the tools the agent already has. Local directories are read with read_file and search_files; online documentation is fetched with web_extract; workflows carried out together in the current conversation are captured directly from conversation context.
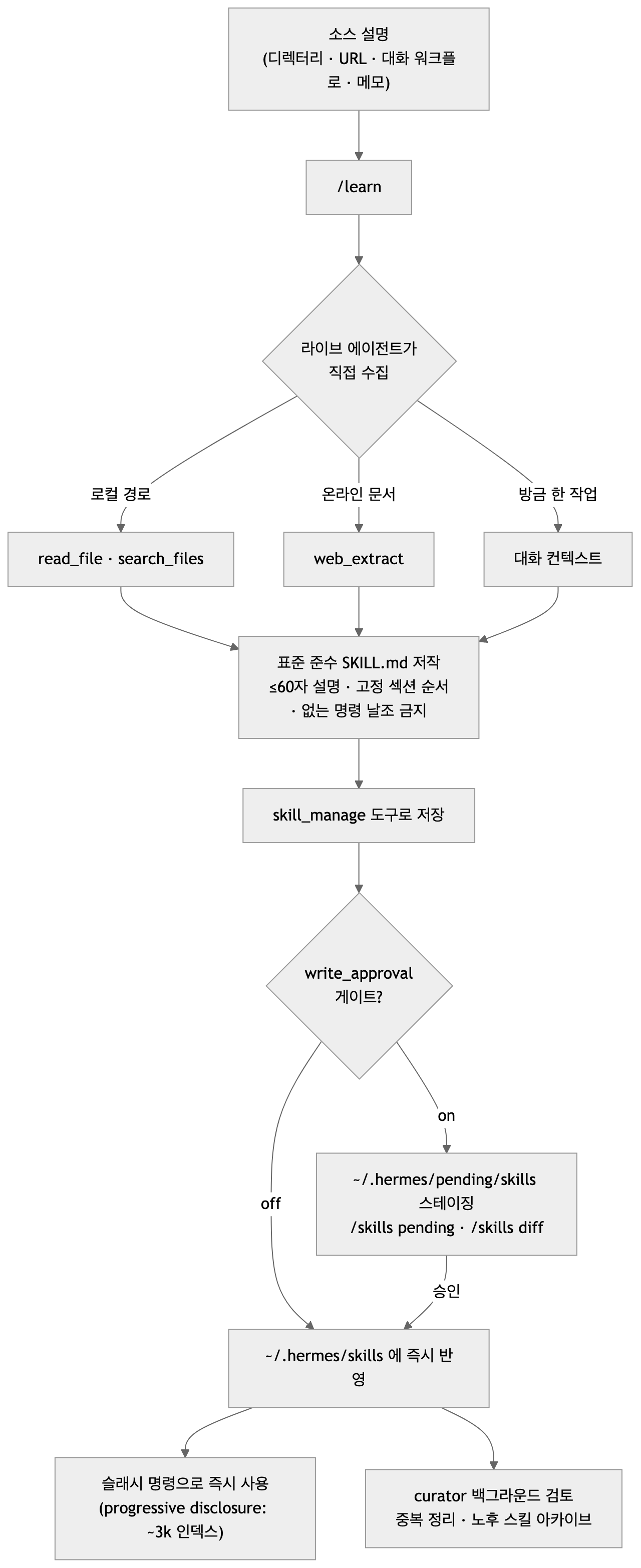 The complete /learn path: starting from a source description, collecting via agent tools, authoring a standard SKILL.md, and passing through the write_approval gate and curator.
The complete /learn path: starting from a source description, collecting via agent tools, authoring a standard SKILL.md, and passing through the write_approval gate and curator.
Four source types are accepted. The following examples are taken verbatim from the official documentation:
# Local SDK or documentation directory (read via read_file / search_files)
/learn the REST client in ~/projects/acme-sdk, focus on auth + pagination
# Online documentation page (fetched via web_extract)
/learn https://docs.example.com/api/quickstart
# A workflow you just completed with the agent in this conversation
/learn how I just deployed the staging server
# A pasted note or verbally described procedure
/learn filing an expense: open the portal, New > Expense, attach the receipt, submit
The agent organizes the collected material according to the “house authoring standard”: descriptions capped at 60 characters, a fixed section order, framing based on Hermes tools, and a rule against inventing commands that do not exist. The resulting SKILL.md consists of YAML frontmatter and fixed body sections:
---
name: my-skill
description: Brief description of what this skill does
version: 1.0.0
platforms: [macos, linux]
metadata:
hermes:
tags: [python, automation]
category: devops
---
# Skill Title
## When to Use
Conditions that trigger this skill.
## Procedure
1. First step
2. Second step
## Pitfalls
- Known failure modes and solutions
## Verification
How to confirm the skill is working.
Storage is handled by the skill_manage tool. One important safety mechanism is attached here. When skills.write_approval is enabled, every skill write by the agent is staged to ~/.hermes/pending/skills/ instead of being applied immediately. A human can review pending changes with /skills pending, inspect the full diff with /skills diff <id>, and then approve or reject. This gate applies equally to skills created in a foreground turn and to skills proposed by the background self-improvement review.
Because there is no separate ingestion engine, /learn works identically across the CLI, the TUI, messaging gateways, and the dashboard. It does not matter whether the terminal backend is local, Docker, or remote. In the dashboard, a “Learn a skill” button appears on the Skills page and assembles a /learn request from a directory field, a URL field, and a free-text box.
The official documentation identifies three usage scenarios. First, internal API onboarding: run /learn against a private documentation URL and it produces a skill covering authentication, pagination, and common calls; new team members then invoke it as a slash command. Second, deployment runbook capture: step through a staging deployment with the agent, then run /learn how I just deployed the staging server and the procedure becomes repeatable across CLI and chat platforms. Third, bundling repetitive tasks: a skill bundle lets a single slash command load the review, test, and PR skills together.
# ~/.hermes/skill-bundles/backend-dev.yaml
name: backend-dev
description: Backend feature work - review, test, PR workflow.
skills:
- github-code-review
- test-driven-development
- github-pr-workflow
instruction: |
Always start by writing failing tests, then implement.
The skill system also offers an opt-out path if you want to start from a clean slate. hermes skills opt-out stops seeding bundle skills, and hermes skills opt-in --sync restores them. The platforms field hides incompatible skills on unsupported operating systems, and conditional fields expose a skill only when a specific toolset is present, giving fine-grained control over what surfaces in any given environment.
Installation and Integration
We verified the Hermes Agent installation in our ThakiCloud environment directly. The binary lives at ~/.local/bin/hermes and actually runs on Python from ~/hermes-agent/venv.
$ ~/.local/bin/hermes --version
Hermes Agent v0.16.0 (2026.6.5) · upstream 40cea4d5
Python: 3.11.13
OpenAI SDK: 2.24.0
All skills are stored in ~/.hermes/skills/, which is the single source of truth. Because Hermes is compatible with the agentskills.io open standard, you can configure multiple tools to share-scan the same skills folder:
# ~/.hermes/config.yaml
skills:
external_dirs:
- ~/.agents/skills
- /home/shared/team-skills
- ${SKILLS_REPO}/skills
That external_dirs setting is the crux of the platform perspective we cover later. We pulled the list of installed skills directly. 78 skills are currently installed, categorized under apple, autonomous-ai-agents, creative, and others:
$ ~/.local/bin/hermes skills list
Installed Skills
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━┓
┃ Name ┃ Category ┃ Source ┃ Trust ┃ Status ┃
┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━┩
│ claude-code │ autonomous-ai-agents │ builtin │ builtin │ enabled │
│ architecture-diagram│ creative │ builtin │ builtin │ enabled │
│ humanizer │ creative │ builtin │ builtin │ enabled │
│ excalidraw │ creative │ builtin │ builtin │ enabled │
└─────────────────────┴──────────────────────┴─────────┴─────────┴─────────┘
Every installed skill automatically becomes a slash command. Typing the name alone - /excalidraw - loads the skill and the agent asks how it can help; supplying an argument such as /plan design a rollout for migrating our auth provider processes the request immediately. The skill management subcommands are extensive:
$ ~/.local/bin/hermes skills --help
{browse, search, install, inspect, list, check, update, audit,
uninstall, reset, opt-out, opt-in, repair-official, publish,
snapshot, tap, config}
A mechanism to prevent unbounded skill accumulation is also built in. The curator runs a secondary model in the background on a schedule, reviewing agent-created skills to consolidate duplicates and archive stale ones. Bundle skills and hub-installed skills are never touched; archives are recoverable and there is no automatic deletion:
$ ~/.local/bin/hermes curator --help
{status, run, pause, resume, pin, unpin, restore,
list-archived, archive, prune, backup, rollback}
Progressive disclosure for token cost management is confirmed as well. At level 0, an index of roughly 3,000 tokens containing only name and description loads first; the full content loads only when the work actually requires it:
Level 0: skills_list() -> [{name, description, category}, ...] (~3k tokens)
Level 1: skill_view(name) -> Full content + metadata
Level 2: skill_view(name, path) -> Specific reference file
What We Actually Tested
There is a limitation that must be stated honestly here. The version installed at ThakiCloud is v0.16.0 (2026.6.5), which predates the June 24, 2026 release that introduced /learn. Because the binary reports “Up to date” based on the local git checkout, upstream new releases are not applied automatically. We therefore could not run /learn in our environment and capture output metrics. The constraint encountered during reproduction attempts: the installed version predates /learn, so the command itself is absent.
What we could verify, we measured directly. The skill system skeleton that /learn writes into is fully operational in our environment. All 78 skills surface as slash commands, and the skill_manage-based agent self-authoring path, the skills.write_approval staging gate, the curator background cleanup, and progressive disclosure indexing are all present in the installed version. In other words, what /learn adds is a thin entry point that, given a source description, constructs a standard prompt and feeds it into the existing authoring pipeline. The heavy machinery underneath has already been verified.
The behavior of /learn itself was cross-verified against the official documentation and the June 24, 2026 MarkTechPost report. Both sources describe the same facts: four source types, read_file / search_files / web_extract as collection tools, a 60-character description cap with fixed section order, skill_manage storage, and the write_approval gate. Rather than fabricate numbers, we clearly delineate what has been verified and what has not.
Updating to the upstream release would allow us to run /learn directly and measure output quality. However, that update could affect the running multi-tenant environment, so the safe path is to verify first in an isolated profile before rolling it in. We plan to capture actual /learn output in a follow-up post.
Implications for ThakiCloud’s Kubernetes AI/ML SaaS Platform
/learn is interesting not simply because it is convenient, but because it directly addresses three problems that a multi-tenant agent platform has to solve.
The first is the cost of capturing domain knowledge. Every customer has different deployment runbooks, internal APIs, and incident response procedures. Having a human translate each of these into a SKILL.md slows onboarding. /learn turns “convert this work we just finished into a skill” into a single command that immediately converts procedural memory into a reusable asset. A staging deployment a operator walks through once becomes a repeatable command available across both CLI and chat.
The second is governance. ThakiCloud serves customers who require on-premises and self-hosted deployments, as well as environments that must meet National Intelligence Service security requirements. An agent that can write its own skills is powerful, but it also introduces the risk of unreviewed procedures accumulating automatically. The write_approval gate, which stages every skill write to ~/.hermes/pending/skills/, persists across restarts, and lets a human inspect the full diff via /skills diff before applying it, is well-suited to these environments. The design deliberately separates the benefits of automation from the control of human review.
The third is cross-tool skill sharing. Hermes’s external_dirs configuration allows multiple AI tools to share the same skills folder. ThakiCloud already operates more than 1,000 skills internally using the same agentskills.io standard. Connecting Hermes to that shared directory means a skill authored in one place works across Claude Code, Cursor, and Hermes without duplication. This is the practical implementation of Thin Harness, Fat Skills - the principle that capabilities accumulate in skills rather than in the harness - which is how you build assets that compound in value even as harnesses change.
The roughly 3,000-token progressive disclosure index also matters from a serving cost perspective. Even as the skill count grows into the hundreds, only the index enters the context on every turn; full content loads on demand. For a team running multi-tenant vLLM serving and managing per-token costs, the pattern of decoupling skill count from context cost is worth adopting directly.
Limitations and Counter-Arguments
The most significant limitation is that a human still has to review the output. /learn has a rule against inventing commands that do not exist, but the possibility that a small model misjudges what it has learned remains. The official documentation acknowledges this and recommends enabling write_approval when using a smaller model or in security-sensitive environments. In other words, /learn eliminates authoring cost but does not eliminate review cost. In fact, because skill creation becomes easier, the absence of a review gate and curator cleanup could accelerate the accumulation of low-quality skills.
Second, the trustworthiness of the source determines the trustworthiness of the output. If a document fetched with web_extract is inaccurate or outdated, the skill built on top of it inherits the same errors. The convenience of creating a skill from a single URL transfers the responsibility for source verification to the user.
Third, the clear gap in this verification is that our installed version predates /learn, so we could not measure actual output. The behavior is cross-verified through official documentation and press coverage, but metrics such as output quality, authoring time, and standard-compliance rate were not captured directly. We will obtain those numbers by running the upstream version in an isolated profile and publish them in a follow-up post.
In summary, /learn substantially reduces the friction of creating skills while moving the natural review step that friction used to provide into an explicit gate and a curator. For teams operating multi-tenant agent platforms, it reads more accurately as a governance design choice than as a convenience feature.
Sources
- Hermes Agent official documentation, Skills System: https://hermes-agent.nousresearch.com/docs/user-guide/features/skills
- MarkTechPost, “Nous Research Adds /learn to Hermes Agent’s Skills System” (2026-06-24): https://www.marktechpost.com/2026/06/24/nous-research-adds-learn-to-hermes-agents-skills-system-capturing-workflows-as-slash-commands-without-hand-writing-skill-md/
- NousResearch/hermes-agent (GitHub): https://github.com/NousResearch/hermes-agent
- Original tweet (demo video, tonbistudio): https://x.com/hjguyhan/status/2070135061429854577