SKILL.md를 손으로 쓰지 않습니다: Hermes Agent의 /learn 명령을 뜯어봤습니다
 여러 방향에서 흩어진 지식 조각이 하나의 구조화된 산출물로 결정화되는 모습으로 표현한 /learn의 개념.
여러 방향에서 흩어진 지식 조각이 하나의 구조화된 산출물로 결정화되는 모습으로 표현한 /learn의 개념.
개요
에이전트에게 새 능력을 가르치는 가장 흔한 방법은 스킬 파일을 손으로 쓰는 것이었습니다. 스킬은 결국 마크다운 한 장이지만, 정해진 프런트매터와 섹션 순서를 지켜 처음부터 작성하는 일은 생각보다 품이 듭니다. 사내 API 사용법, 배포 런북, 반복 작업 절차처럼 머릿속에는 있지만 글로 옮기기 귀찮은 것들이 특히 그렇습니다.
Nous Research가 2026년 6월 24일 자사 에이전트 프레임워크 Hermes Agent에 추가한 /learn 명령은 이 손으로 쓰는 단계를 통째로 없앱니다. 디렉터리, URL, 방금 끝낸 대화, 붙여넣은 메모 중 무엇이든 가리키면 라이브 에이전트가 자료를 직접 수집해 표준을 지킨 SKILL.md를 저작합니다. 트위터에서 tonbistudio가 여러 소스를 모아 스킬로 만드는 데모 영상을 공유하면서 화제가 됐고, 마침 ThakiCloud는 이미 사내에서 Hermes Agent를 설치해 운용하고 있어 직접 검증해 봤습니다.
ThakiCloud는 쿠버네티스 기반 AI/ML SaaS 플랫폼에서 멀티테넌트 에이전트를 운용합니다. 에이전트가 스스로 절차적 기억을 쌓고, 그 기억을 사람이 검토할 수 있게 게이트를 거는 구조는 저희가 “얇은 harness, 두꺼운 스킬(Thin Harness, Fat Skills)” 원칙으로 정리해 온 방향과 정확히 맞닿아 있습니다. 능력은 harness가 아니라 스킬에 쌓는다는 원칙입니다. /learn은 그 스킬을 만드는 진입장벽을 낮추는 도구이므로, 단순한 편의 기능 이상으로 볼 여지가 있습니다.
이 기술은 무엇인가
/learn은 별도의 인제스천 엔진이 아닙니다. 핵심은 “표준을 안내하는 프롬프트를 만들어 에이전트에게 평범한 한 턴으로 넘긴다”는 점입니다. 그래서 소스를 수집하는 일도 에이전트가 이미 가진 도구로 처리합니다. 로컬 디렉터리는 read_file과 search_files로 읽고, 온라인 문서는 web_extract로 가져오며, 방금 대화에서 함께 진행한 워크플로는 대화 컨텍스트 그대로 캡처합니다.
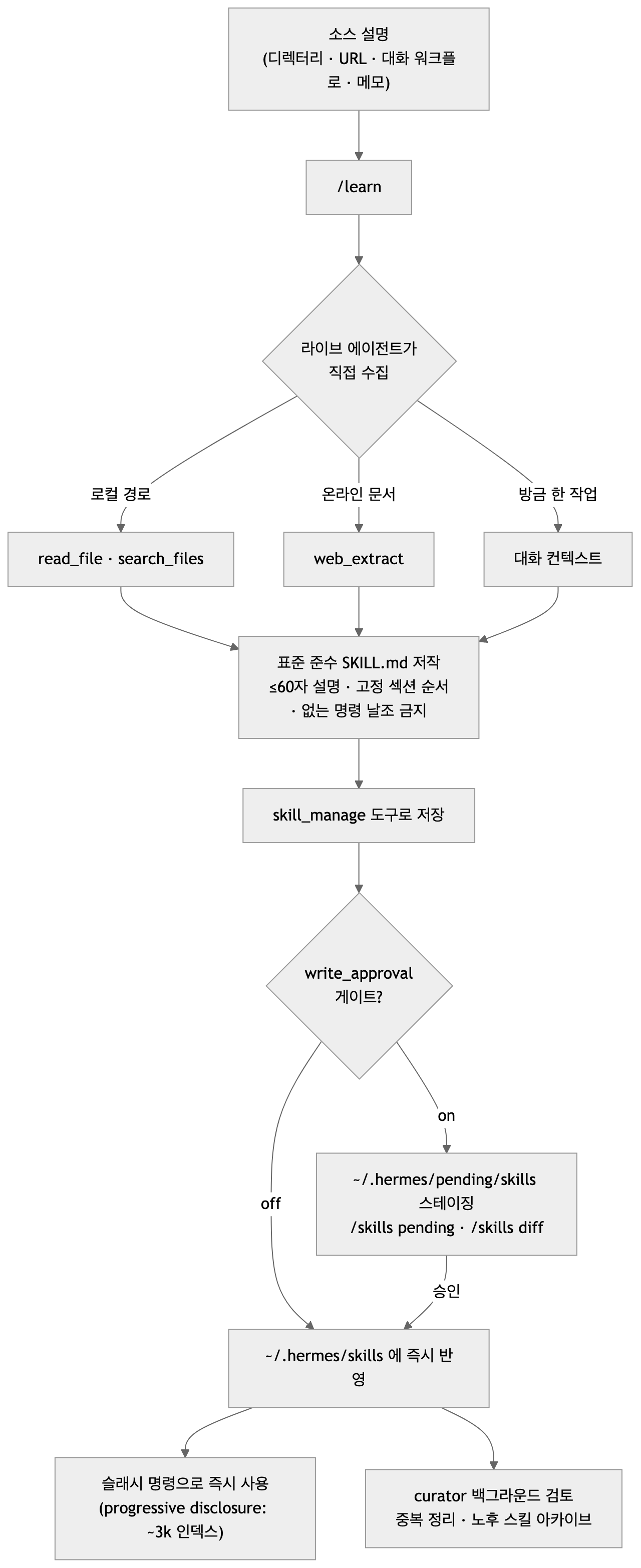 소스 설명에서 시작해 에이전트 도구로 수집하고, 표준 SKILL.md를 저작한 뒤 write_approval 게이트와 curator를 거치는 /learn의 전체 경로.
소스 설명에서 시작해 에이전트 도구로 수집하고, 표준 SKILL.md를 저작한 뒤 write_approval 게이트와 curator를 거치는 /learn의 전체 경로.
받아들이는 소스는 네 종류입니다. 공식 문서에 실린 예시를 그대로 옮기면 다음과 같습니다.
# 로컬 SDK 또는 문서 디렉터리 (read_file / search_files로 읽음)
/learn the REST client in ~/projects/acme-sdk, focus on auth + pagination
# 온라인 문서 페이지 (web_extract로 가져옴)
/learn https://docs.example.com/api/quickstart
# 방금 이 대화에서 에이전트와 함께 진행한 워크플로
/learn how I just deployed the staging server
# 붙여넣은 메모 또는 말로 설명한 절차
/learn filing an expense: open the portal, New > Expense, attach the receipt, submit
에이전트는 수집한 자료를 “하우스 저작 표준”에 맞춰 정리합니다. 설명(description)은 60자 이하, 섹션 순서는 고정, 프레이밍은 Hermes 도구 기준이며, 존재하지 않는 명령을 지어내지 않는다는 규칙입니다. 결과물인 SKILL.md는 YAML 프런트매터와 고정된 본문 섹션으로 이뤄집니다.
---
name: my-skill
description: Brief description of what this skill does
version: 1.0.0
platforms: [macos, linux]
metadata:
hermes:
tags: [python, automation]
category: devops
---
# Skill Title
## When to Use
이 스킬을 트리거하는 조건.
## Procedure
1. 첫 번째 단계
2. 두 번째 단계
## Pitfalls
- 알려진 실패 모드와 해결책
## Verification
동작을 확인하는 방법.
저장은 skill_manage 도구가 담당합니다. 여기서 중요한 안전장치가 하나 붙습니다. skills.write_approval을 켜 두면 에이전트의 모든 스킬 쓰기가 곧바로 반영되지 않고 ~/.hermes/pending/skills/에 스테이징됩니다. 사람은 /skills pending으로 대기 중인 변경을 보고 /skills diff <id>로 전체 diff를 확인한 뒤 승인하거나 거부합니다. 이 게이트는 포그라운드 턴에서 만든 스킬뿐 아니라 백그라운드 자기개선 리뷰가 제안한 스킬에도 똑같이 적용됩니다.
별도 인제스천 엔진이 없다는 설계 덕분에 /learn은 CLI, TUI, 메시징 게이트웨이, 대시보드에서 동일하게 동작합니다. 터미널 백엔드가 로컬이든 도커든 원격이든 상관없습니다. 대시보드에서는 Skills 페이지에 “Learn a skill” 버튼이 생겨 디렉터리 입력란, URL 입력란, 자유 텍스트 박스로 /learn 요청을 구성해 실행합니다.
공식 문서가 제시하는 활용 시나리오는 세 가지로 정리됩니다. 첫째는 사내 API 온보딩입니다. 비공개 문서 URL에 /learn을 실행하면 인증, 페이지네이션, 자주 쓰는 호출을 담은 스킬이 만들어지고, 새 팀원은 이를 슬래시 명령으로 호출합니다. 둘째는 배포 런북 캡처입니다. 에이전트와 함께 스테이징 배포를 한 번 진행한 뒤 /learn how I just deployed the staging server를 실행하면 그 절차가 CLI와 채팅 플랫폼 전반에서 반복 가능해집니다. 셋째는 반복 작업 묶기입니다. 스킬 번들을 쓰면 슬래시 명령 하나로 리뷰, 테스트, PR 스킬을 한꺼번에 로드합니다.
# ~/.hermes/skill-bundles/backend-dev.yaml
name: backend-dev
description: Backend feature work - review, test, PR workflow.
skills:
- github-code-review
- test-driven-development
- github-pr-workflow
instruction: |
Always start by writing failing tests, then implement.
스킬 시스템 자체에는 빈 상태로 시작하는 선택지도 있습니다. hermes skills opt-out으로 번들 스킬 시딩을 멈추고, hermes skills opt-in --sync로 되돌립니다. platforms 필드로 호환되지 않는 운영체제에서는 스킬을 숨기고, 조건부 필드로 특정 toolset이 있을 때만 스킬을 노출하는 등 노출 제어도 세밀합니다.
설치 및 통합
ThakiCloud 환경에 설치된 Hermes Agent를 직접 확인했습니다. 바이너리는 ~/.local/bin/hermes에 있고, 실제로는 ~/hermes-agent/venv의 파이썬에서 구동됩니다.
$ ~/.local/bin/hermes --version
Hermes Agent v0.16.0 (2026.6.5) · upstream 40cea4d5
Python: 3.11.13
OpenAI SDK: 2.24.0
스킬은 모두 ~/.hermes/skills/에 모여 있고, 이 디렉터리가 단일 진실원입니다. agentskills.io 오픈 표준과 호환되므로, 여러 도구가 공유하는 스킬 폴더를 함께 스캔하도록 설정할 수도 있습니다. 이 외부 디렉터리 설정이 뒤에서 다룰 플랫폼 관점의 핵심입니다.
# ~/.hermes/config.yaml
skills:
external_dirs:
- ~/.agents/skills
- /home/shared/team-skills
- ${SKILLS_REPO}/skills
설치된 스킬 목록을 직접 뽑아 봤습니다. 현재 78개의 스킬이 설치되어 있고, 카테고리는 apple, autonomous-ai-agents, creative 등으로 분류됩니다.
$ ~/.local/bin/hermes skills list
Installed Skills
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━┓
┃ Name ┃ Category ┃ Source ┃ Trust ┃ Status ┃
┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━┩
│ claude-code │ autonomous-ai-agents │ builtin │ builtin │ enabled │
│ architecture-diagram│ creative │ builtin │ builtin │ enabled │
│ humanizer │ creative │ builtin │ builtin │ enabled │
│ excalidraw │ creative │ builtin │ builtin │ enabled │
└─────────────────────┴──────────────────────┴─────────┴─────────┴─────────┘
설치된 모든 스킬은 자동으로 슬래시 명령이 됩니다. /excalidraw처럼 이름만 부르면 스킬이 로드되어 에이전트가 무엇을 도울지 되묻고, /plan design a rollout for migrating our auth provider처럼 인자를 함께 주면 그 요청을 바로 처리합니다. 스킬 관리 서브커맨드도 풍부합니다.
$ ~/.local/bin/hermes skills --help
{browse, search, install, inspect, list, check, update, audit,
uninstall, reset, opt-out, opt-in, repair-official, publish,
snapshot, tap, config}
스킬이 무한정 쌓이는 문제를 막는 장치도 내장되어 있습니다. curator는 보조 모델이 백그라운드에서 주기적으로 에이전트가 만든 스킬을 검토해 중복을 정리하고 노후 스킬을 아카이브하는 작업입니다. 번들 스킬과 허브에서 설치한 스킬은 절대 건드리지 않으며, 아카이브는 복구 가능하고 자동 삭제는 일어나지 않습니다.
$ ~/.local/bin/hermes curator --help
{status, run, pause, resume, pin, unpin, restore,
list-archived, archive, prune, backup, rollback}
토큰 비용을 누르는 progressive disclosure도 그대로 확인됩니다. 0단계에서는 이름과 설명만 담긴 약 3,000토큰짜리 인덱스가 먼저 로드되고, 작업이 실제로 필요할 때만 전체 내용이 로드됩니다.
Level 0: skills_list() → [{name, description, category}, ...] (~3k 토큰)
Level 1: skill_view(name) → 전체 내용 + 메타데이터
Level 2: skill_view(name, path) → 특정 참조 파일
실제 실험 결과
여기서 정직하게 기록해야 할 한계가 있습니다. ThakiCloud에 설치된 버전은 v0.16.0 (2026.6.5)로, /learn이 추가된 2026년 6월 24일자 릴리스보다 앞섭니다. 바이너리가 로컬 git 체크아웃을 기준으로 “Up to date”라고 보고하기 때문에 업스트림 신규 릴리스가 자동 반영되지는 않았습니다. 그래서 이번 글에서는 /learn을 우리 환경에서 직접 실행해 결과 수치를 캡처하지는 못했습니다. 재현 시도 중 제약: 설치본 버전이 /learn 도입 이전이라 명령 자체가 부재합니다.
대신 검증할 수 있는 것은 모두 실측했습니다. /learn이 결과물을 꽂아 넣는 스킬 시스템의 골격은 우리 환경에서 그대로 동작합니다. 78개의 스킬이 슬래시 명령으로 노출되고, skill_manage 기반의 에이전트 자가 저작 경로와 skills.write_approval 스테이징 게이트, curator 백그라운드 정리, progressive disclosure 인덱싱이 모두 설치본에 존재합니다. 즉 /learn이 추가한 것은 “소스를 가리키면 표준 프롬프트를 만들어 기존 저작 경로에 태운다”는 얇은 진입점이고, 그 아래의 무거운 부분은 이미 검증된 상태입니다.
/learn의 동작 자체는 공식 문서와 2026년 6월 24일 MarkTechPost 보도로 교차 검증했습니다. 두 소스 모두 네 가지 소스 유형, read_file/search_files/web_extract 수집 도구, 60자 설명 제약과 고정 섹션 순서, skill_manage 저장과 write_approval 게이트라는 동일한 사실을 기술합니다. 수치를 지어내는 대신, 검증된 범위와 검증하지 못한 범위를 분명히 나눠 둡니다.
업스트림으로 업데이트하면 /learn을 직접 돌려 산출물 품질을 측정할 수 있습니다. 다만 그 업데이트는 운용 중인 멀티테넌트 환경에 영향을 줄 수 있어, 격리된 프로파일에서 먼저 검증한 뒤 반영하는 것이 안전합니다. 후속 글에서 실제 /learn 산출물을 캡처해 보강할 예정입니다.
ThakiCloud 쿠버네티스 AI/ML SaaS 플랫폼 적용 및 시사점
/learn이 흥미로운 이유는 단순히 편하기 때문이 아니라, 멀티테넌트 에이전트 플랫폼이 풀어야 하는 세 가지 문제와 정면으로 맞닿기 때문입니다.
첫째는 도메인 지식의 캡처 비용입니다. 고객사마다 배포 런북, 사내 API, 인시던트 대응 절차가 다릅니다. 이것을 매번 사람이 SKILL.md로 옮기면 도입 속도가 느려집니다. /learn은 “방금 함께 끝낸 작업을 스킬로 만들어라”는 한 줄로 절차적 기억을 즉시 자산화합니다. 운영자가 한 번 시연한 스테이징 배포가 CLI와 채팅 양쪽에서 재사용 가능한 명령이 되는 식입니다.
둘째는 거버넌스입니다. ThakiCloud는 온프레미스와 self-hosting을 요구하는 고객, 그리고 국가정보원 보안 요구를 충족해야 하는 환경을 함께 다룹니다. 에이전트가 스스로 스킬을 쓰는 능력은 강력하지만, 동시에 검토되지 않은 절차가 자동으로 쌓이는 위험이기도 합니다. write_approval 게이트가 모든 스킬 쓰기를 ~/.hermes/pending/skills/에 스테이징하고, 재시작 후에도 유지하며, /skills diff로 전체 변경을 사람이 확인하게 만드는 구조는 이런 환경에 적합합니다. 자동화의 편익과 사람 검토의 통제를 분리해 둔 설계입니다.
셋째는 도구 간 스킬 공유입니다. Hermes의 external_dirs 설정은 여러 AI 도구가 같은 스킬 폴더를 공유하도록 허용합니다. ThakiCloud는 이미 사내에서 1,000개가 넘는 스킬을 동일한 agentskills.io 표준으로 운용하고 있습니다. Hermes를 이 공유 디렉터리에 연결하면, 한 곳에서 작성한 스킬이 Claude Code, Cursor, Hermes를 가로질러 동작합니다. 이것이 바로 능력을 harness가 아니라 스킬에 쌓는다는 “얇은 harness, 두꺼운 스킬” 원칙의 실천이며, harness가 바뀌어도 복리가 쌓이는 자산을 만드는 방법입니다.
progressive disclosure의 약 3,000토큰 인덱스도 서빙 비용 관점에서 중요합니다. 스킬이 수백 개로 늘어도 매 턴 컨텍스트에 들어가는 것은 인덱스뿐이고, 전체 내용은 필요할 때만 로드됩니다. 멀티테넌트로 vLLM 서빙을 운용하며 토큰 단가를 관리하는 입장에서, 스킬 수와 컨텍스트 비용을 분리하는 이 패턴은 그대로 채택할 가치가 있습니다.
한계 및 반론
가장 큰 한계는 산출물 품질을 사람이 결국 검토해야 한다는 점입니다. /learn은 “없는 명령을 지어내지 않는다”는 규칙을 두지만, 작은 모델이 무엇을 배웠는지 잘못 판단할 가능성은 남습니다. 공식 문서도 이 점을 인정하며 작은 모델을 쓰거나 보안이 중요한 환경에서는 write_approval을 켤 것을 권합니다. 즉 /learn은 작성 비용을 없애지만 검토 비용을 없애지는 못합니다. 오히려 스킬 생성이 쉬워지는 만큼, 검토 게이트와 curator의 정리가 없으면 저품질 스킬이 빠르게 쌓이는 역효과가 생길 수 있습니다.
둘째, 소스의 신뢰도가 산출물의 신뢰도를 결정합니다. web_extract로 가져온 외부 문서가 부정확하거나 오래됐다면, 그 위에서 만들어진 스킬도 같은 오류를 물려받습니다. URL 한 줄로 스킬을 만든다는 편의는 곧 출처 검증 책임을 사용자에게 넘긴다는 뜻이기도 합니다.
셋째, 이번 검증의 명백한 공백은 우리 설치본이 /learn 이전 버전이라 실제 산출물을 측정하지 못했다는 것입니다. 동작 사실은 공식 문서와 보도로 교차 검증했지만, 산출물 품질, 저작 소요 시간, 표준 준수율 같은 수치는 직접 캡처하지 못했습니다. 이런 수치는 격리 프로파일에서 업스트림 버전을 돌린 뒤 후속 글에서 보강하겠습니다.
결론적으로 /learn은 스킬을 만드는 마찰을 크게 줄이는 동시에, 그 마찰이 수행하던 자연스러운 검토 단계를 게이트와 curator로 옮긴 설계입니다. 멀티테넌트 에이전트 플랫폼을 운용하는 입장에서는 편의 기능이 아니라 거버넌스 설계로 읽는 편이 정확합니다.
출처 (Sources)
- Hermes Agent 공식 문서, Skills System: https://hermes-agent.nousresearch.com/docs/user-guide/features/skills
- MarkTechPost, “Nous Research Adds /learn to Hermes Agent’s Skills System” (2026-06-24): https://www.marktechpost.com/2026/06/24/nous-research-adds-learn-to-hermes-agents-skills-system-capturing-workflows-as-slash-commands-without-hand-writing-skill-md/
- NousResearch/hermes-agent (GitHub): https://github.com/NousResearch/hermes-agent
- 원 트윗(데모 영상 공유, tonbistudio): https://x.com/hjguyhan/status/2070135061429854577