0.9B로 문서 파싱 SOTA: PaddleOCR-VL을 직접 설치해 한국어·아랍어로 돌려봤습니다
 수많은 문서가 구조화된 데이터로 정리되는 과정을 추상적으로 표현했습니다.
수많은 문서가 구조화된 데이터로 정리되는 과정을 추상적으로 표현했습니다.
📄 심층 리뷰 전문(DOCX): 이 논문의 상세 피어리뷰를 Google Drive에서 다운로드할 수 있습니다.
개요
문서를 기계가 읽을 수 있는 구조로 바꾸는 작업, 즉 문서 파싱은 RAG와 에이전트 시대에 다시 중요해졌습니다. PDF 한 장에는 본문, 표, 수식, 차트, 다단 레이아웃이 뒤섞여 있고, 이걸 정확한 읽기 순서로 풀어내야 LLM이 제대로 활용할 수 있기 때문입니다. 그동안 이 영역은 GPT-4o나 Gemini 2.5 Pro 같은 거대 멀티모달 모델, 또는 무거운 파이프라인 도구가 주도해 왔습니다.
PaddlePaddle 팀(Baidu)이 공개한 PaddleOCR-VL은 이 구도를 흔드는 모델입니다. 핵심 모델인 PaddleOCR-VL-0.9B는 파라미터가 약 9.6억 개에 불과한 초소형 비전-언어 모델인데도, 페이지 단위 문서 파싱과 요소 단위 인식 모두에서 최상위 성능을 보고합니다. 라이선스는 Apache-2.0으로 상업적 활용이 자유롭고, 허깅페이스에서 이미 12만 회 이상 다운로드되며 검증받고 있습니다.
저희 ThakiCloud는 쿠버네티스 기반 AI/ML SaaS 플랫폼에서 멀티테넌트 추론과 문서 처리 워크로드를 직접 운영합니다. 그래서 이 모델을 글로만 소개하지 않고, 실제로 설치해 한국어·영어·아랍어가 섞인 문서로 추론을 돌려봤습니다. 작은 모델이 정말 쓸 만한지, 그리고 우리 플랫폼 관점에서 어디에 맞는지를 실측과 함께 정리합니다.
이 기술은 무엇인가
PaddleOCR-VL의 핵심 설계 사상은 “거대한 종단간(end-to-end) VLM 하나로 모든 걸 처리하지 않는다”입니다. 종단간 방식은 긴 자기회귀 디코딩에 의존하기 때문에 지연과 메모리 비용이 크고, 다단·혼합 레이아웃에서 환각과 불안정성이 두드러집니다. 그래서 PaddleOCR-VL은 작업을 두 단계로 분리합니다.
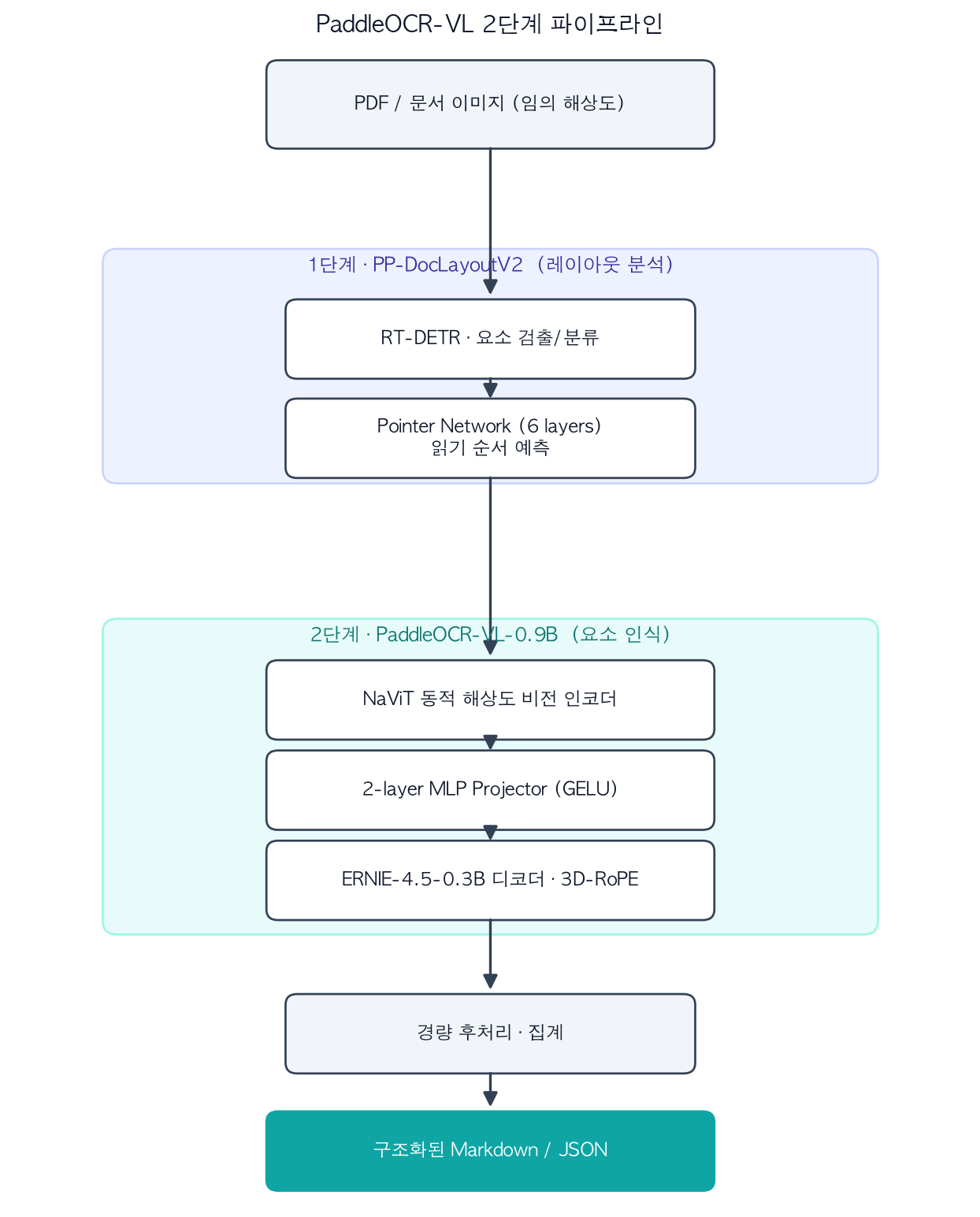 레이아웃 분석과 요소 인식을 분리한 2단계 구조입니다.
레이아웃 분석과 요소 인식을 분리한 2단계 구조입니다.
1단계, 레이아웃 분석(PP-DocLayoutV2): 가벼운 전용 모델이 문서에서 의미 영역을 찾고 분류한 뒤 읽기 순서를 예측합니다. 객체 검출에는 RT-DETR을, 읽기 순서 예측에는 6개 트랜스포머 레이어로 구성된 포인터 네트워크를 씁니다. 무거운 VLM에 레이아웃 추론까지 떠넘기지 않고 분리함으로써, 다단 레이아웃에서도 안정적인 결과를 얻습니다.
2단계, 요소 인식(PaddleOCR-VL-0.9B): 1단계가 잡아준 영역을 받아 본문, 표, 수식, 차트를 세밀하게 인식합니다. 구조는 LLaVA 계열을 따르되, 비전 인코더로 NaViT 방식의 동적 해상도 인코더(Keye-VL 비전 모델에서 초기화)를 써서 임의 해상도 이미지를 왜곡 없이 처리합니다. 여기에 GELU 활성화를 쓰는 2층 MLP 프로젝터(merge size 2)가 시각 특징을 언어 모델 임베딩 공간으로 잇고, 디코더로는 ERNIE-4.5-0.3B에 3D-RoPE를 더해 사용합니다. 디코더가 작을수록 토큰당 디코딩이 빨라지므로, 작은 언어 모델을 고른 것은 속도를 위한 의도적 선택입니다.
마지막으로 경량 후처리 모듈이 두 단계 출력을 합쳐 구조화된 Markdown과 JSON으로 만들어 줍니다. 이 모델이 지원하는 언어는 109개로, 라틴 문자뿐 아니라 한국어, 일본어, 아랍어, 키릴 문자, 데바나가리(힌디) 등 서로 다른 문자 체계를 폭넓게 다룹니다.
설치 및 통합
직접 설치해 보겠습니다. 환경은 Apple Silicon 맥북(macOS, CPU 전용, GPU 가속 없음), Python 3.12.8입니다. PaddleOCR-VL은 PaddlePaddle 생태계 위에서 동작하므로 다음 두 패키지를 설치합니다.
# 공유 가상환경(.venv)에 설치 (python-runtime 규칙)
VIRTUAL_ENV="$PWD/.venv" uv pip install paddlepaddle paddleocr
# 설치된 버전: paddlepaddle==3.3.1, paddleocr==3.7.0
첫 추론 시도에서는 다음 오류가 났습니다.
RuntimeError: A dependency error occurred during pipeline creation.
Please refer to the installation documentation to ensure all required dependencies are installed.
PaddleOCR-VL 파이프라인은 문서 파싱 전용 의존성을 추가로 요구합니다. 다음 한 줄로 해결했습니다.
VIRTUAL_ENV="$PWD/.venv" uv pip install "paddleocr[doc-parser]"
추론 코드 자체는 짧습니다. 파이프라인이 필요한 모델을 자동으로 내려받습니다.
from paddleocr import PaddleOCRVL
pipe = PaddleOCRVL() # 첫 호출 시 모델 자동 다운로드
out = pipe.predict("sample_doc.png") # 문서 이미지 → 구조화 결과
for res in out:
res.save_to_markdown(save_path="paddleocr_out")
여기서 한 가지 짚을 점이 있습니다. paddleocr==3.7.0은 파이프라인을 만들 때 레이아웃 모델로 PP-DocLayoutV3를, 인식 모델로 PaddleOCR-VL-1.6-0.9B를 자동으로 선택했습니다. 즉 패키지가 논문(2510.14528)의 초기 버전이 아니라 그 이후 갱신된 1.6 모델과 더 최신 레이아웃 모델을 기본값으로 끌어옵니다. 트위터에서 화제가 된 “OmniDocBench 96.33% SOTA”는 바로 이 PaddleOCR-VL-1.6(OmniDocBench v1.6 기준)의 수치이며, 0.9B를 처음 제안한 기반 논문이 보고한 점수와는 버전이 다릅니다. 이 구분은 뒤에서 다시 정리합니다.
실제 실험 결과
테스트 문서로는 한국어·영어·아랍어와 숫자, 간단한 수식이 섞인 합성 이미지를 만들어 입력했습니다. ThakiCloud의 청구서·비용 보고서를 흉내 낸 1페이지짜리 문서입니다. CPU 환경에서 측정한 실제 수치는 다음과 같습니다.
- 모델 초기화(첫 호출, 다운로드 포함): 74.7초
- 추론(predict): 32.65초 / 1페이지
- 전체 소요(임포트~저장): 137.4초
- 디코더 구조 로그: GQA(grouped-query attention), num_heads 16 / num_key_value_heads 2
인식 결과 Markdown은 다음과 같았습니다.
## ThakiCloud Document Intelligence
Kubernetes AI/ML SaaS Platform - Invoice No. 2026-0623
타키클라우드 멀티테넌트 추론 비용 보고서
GPU hours: 1,284 Total: $9,640.00
E = mc^2 sum_{i=1}^{n} x_i
주목할 점은, 영어 제목을 Markdown 헤딩(##)으로 잡아내고, 한국어 문장 “타키클라우드 멀티테넌트 추론 비용 보고서”를 정확히 인식했으며, 숫자와 통화 표기($9,640.00, GPU hours 1,284)도 오차 없이 읽었다는 것입니다. 0.9B 모델치고 한국어 인식 품질이 상당히 안정적이었습니다.
한 가지 정직하게 기록할 부분이 있습니다. 제가 만든 합성 이미지의 아랍어 줄은 텍스트로 전사되지 않고 이미지 영역으로 분류됐습니다. 이는 모델 결함이라기보다 테스트 이미지 쪽 문제입니다. PIL로 아랍어를 렌더링할 때 글자 연결(shaping)과 양방향(bidi) 처리가 제대로 되지 않아 글자가 분리된 형태로 그려졌고, 레이아웃 단계가 이를 그림으로 판단한 것으로 보입니다. 논문이 보고하는 아랍어 라인 인식 편집 거리는 0.122로 충분히 낮으므로, 실제 아랍어 문서라면 다른 결과가 나옵니다. 이 경험 자체가 “전처리·렌더링 품질이 결과를 좌우한다”는 운영상의 교훈을 줍니다.
논문이 공개 벤치마크에서 보고한 수치도 함께 봅니다. 아래는 기반 논문(arXiv:2510.14528)이 109개 언어 중 일부에 대해 보고한 라인 단위 텍스트 인식 편집 거리입니다(낮을수록 좋음).
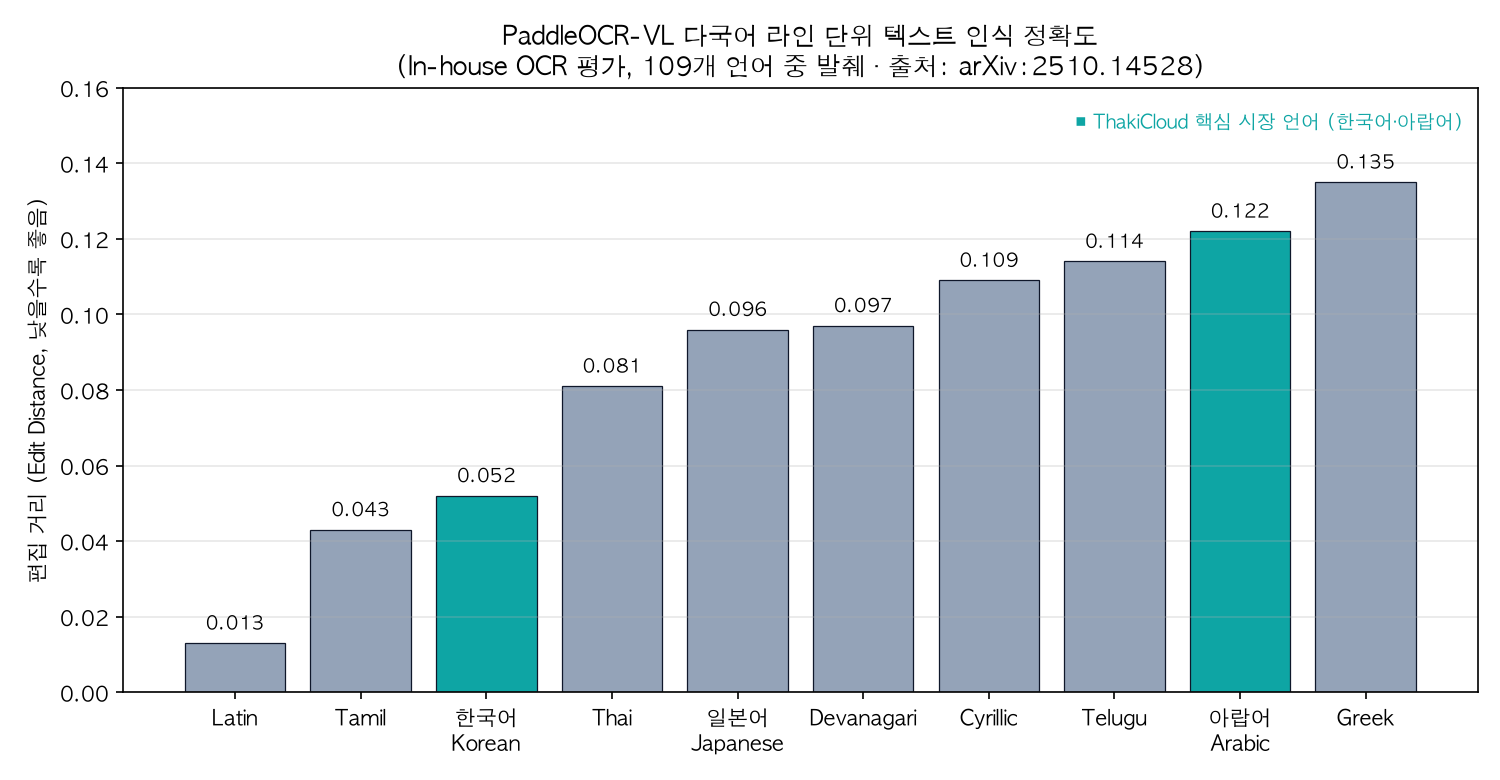 ThakiCloud의 핵심 시장 언어인 한국어와 아랍어를 강조했습니다. 출처: arXiv:2510.14528.
ThakiCloud의 핵심 시장 언어인 한국어와 아랍어를 강조했습니다. 출처: arXiv:2510.14528.
한국어는 0.052, 아랍어는 0.122로, ThakiCloud가 주목하는 두 시장 언어 모두 양호한 편집 거리를 보입니다. 페이지 단위 종합 성능에서도 기반 논문은 OmniDocBench v1.5 종합 점수 92.86으로 차순위 MinerU2.5-1.2B(90.67)를 앞섰다고 보고합니다.
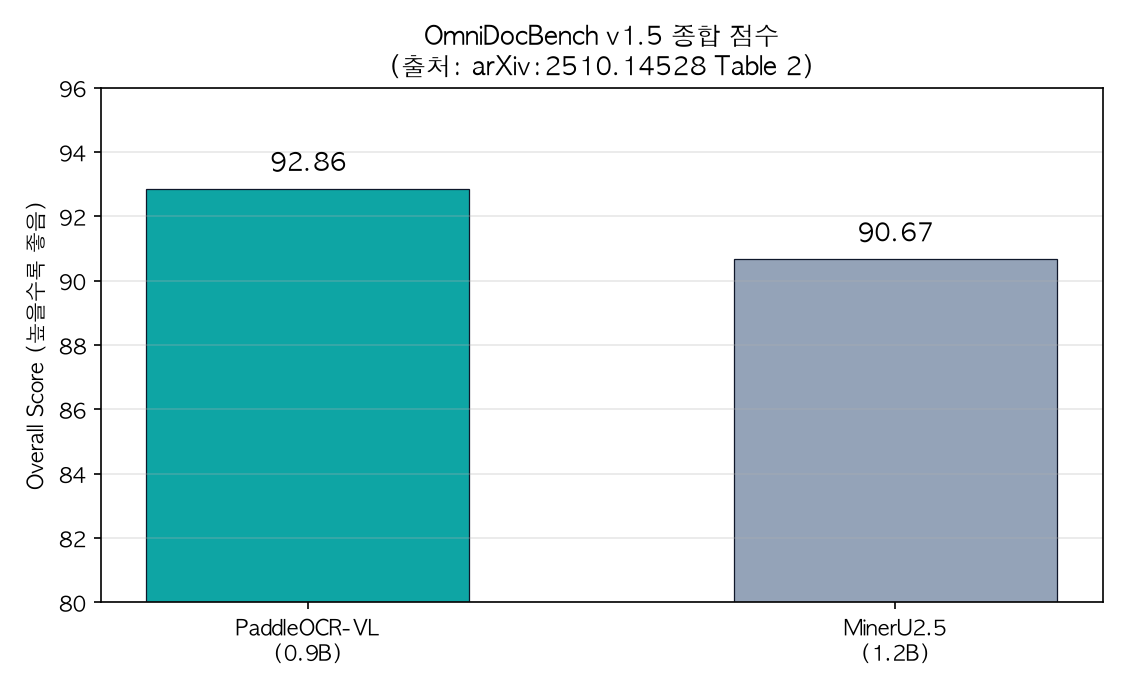 0.9B 모델이 1.2B 모델을 앞선 종합 점수입니다. 출처: arXiv:2510.14528 Table 2.
0.9B 모델이 1.2B 모델을 앞선 종합 점수입니다. 출처: arXiv:2510.14528 Table 2.
수치를 인용할 때는 버전을 분명히 해야 합니다. 기반 논문(2510.14528)은 OmniDocBench v1.5에서 92.86을 보고했고, 이후 후속 버전인 PaddleOCR-VL-1.5는 v1.5에서 94.5%, PaddleOCR-VL-1.6은 v1.6에서 96.33%를 [추정]치로 보고합니다(후속 버전 수치는 별도 리포트 기준). 트위터에서 본 96.33%는 가장 최신 1.6 버전의 점수입니다. 한편 논문이 측정한 추론 속도는 단일 NVIDIA A100에서 PDF를 512개씩 배치 처리하고 vLLM·SGLang·FastDeploy 같은 고성능 서빙 엔진을 쓴 환경 기준이라는 점도 함께 기억해야 합니다. 저희가 CPU에서 잰 32.65초/페이지는 가속 없는 환경의 참고치이며, 프로덕션 처리량과는 다릅니다.
ThakiCloud K8s AI/ML SaaS 플랫폼 적용 시사점
이 모델이 흥미로운 이유는 단순히 점수가 높아서가 아니라, 작아서 운영하기 쉽다는 점 때문입니다. ThakiCloud의 스택 관점에서 의미를 정리하면 이렇습니다.
- 저비용 멀티테넌트 서빙: 0.9B 모델은 컨슈머급 또는 보급형 GPU 한 장에도 올라갑니다. 저희가 운영하는 Kueue 기반 GPU 스케줄링과 vLLM·SGLang 서빙 위에 올리면, 테넌트별 문서 파싱 엔드포인트를 합리적인 비용으로 다중 배치할 수 있습니다. 거대 VLM을 호출할 때마다 드는 토큰 비용 없이, 자체 호스팅 추론으로 단가를 통제하는 구조입니다.
- 데이터 주권과 온프레미스: 문서에는 청구서, 계약서, 의료·금융 기록처럼 외부로 내보내기 어려운 정보가 많습니다. Apache-2.0 라이선스의 모델을 온프레미스로 self-hosting 하면, 데이터를 외부 API에 보내지 않고도 문서 인텔리전스를 제공할 수 있습니다. 국내 공공·금융 환경의 망분리·데이터 반출 제약에도 부합하는 방향입니다.
- 다국어가 곧 시장 적합성: 저희 블로그는 한국어·영어·아랍어로 함께 발행됩니다. 한국 시장과 중동 시장을 동시에 바라보는 입장에서, 한국어(0.052)와 아랍어(0.122)를 한 모델로 안정적으로 처리한다는 점은 그대로 제품 경쟁력이 됩니다. 시장마다 다른 OCR 엔진을 붙일 필요가 줄어듭니다.
- RAG 파이프라인의 입력단: 구조화된 Markdown·JSON 출력은 그대로 RAG 인덱싱과 에이전트 도구 호출의 입력이 됩니다. 레이아웃·읽기 순서가 보존된 텍스트는 청크 품질을 높여 검색 정확도에 직접 기여합니다.
성숙 단계에서는 1단계 레이아웃 모델과 2단계 인식 모델을 별도 서비스로 분리해, 레이아웃은 CPU 노드에, VLM 인식은 GPU 노드에 배치하는 식의 이종 스케줄링도 가능합니다. 두 단계로 분리된 구조가 오히려 쿠버네티스 환경의 자원 배치에 유리하게 작용합니다.
한계 및 반론
장점만 보면 곤란합니다. 실측과 문헌을 바탕으로 약점도 분명히 적습니다.
- CPU에서는 느립니다: 저희가 잰 32.65초/페이지는 대량 문서 처리에는 적합하지 않습니다. 실사용에는 GPU와 vLLM·SGLang 같은 서빙 엔진이 사실상 필수이며, 논문의 인상적인 처리량도 A100 배치 환경 수치입니다.
- 2단계 구조의 의존성: 레이아웃 모델과 인식 모델 두 개를 함께 관리해야 합니다. 단일 모델보다 배포·버전 정합성 관리 비용이 늘어납니다. 실제로 패키지가 기본값으로 PP-DocLayoutV3 + PaddleOCR-VL-1.6을 끌어오는 등, 버전 조합이 시점에 따라 바뀔 수 있습니다.
- SOTA 수치는 버전에 묶여 있습니다: 96.33%는 1.6 버전의 OmniDocBench v1.6 점수이지, 0.9B를 처음 제안한 기반 논문의 헤드라인이 아닙니다. 인용할 때 버전과 벤치마크 판을 함께 밝히지 않으면 오해를 부릅니다.
- 전처리 품질 의존: 저희 아랍어 테스트가 보여줬듯, 입력 이미지의 렌더링·해상도·문자 셰이핑 품질이 결과를 좌우합니다. 실데이터 파이프라인에서는 입력 정규화 단계가 모델 선택만큼 중요합니다.
- 표 인식의 약점 보고: 기반 논문도 OmniDocBench v1.0의 영어 표 TEDS(88.0)가 상대적으로 낮다고 적었습니다(주석 오류 영향이 있다고 설명하지만). 표가 많은 문서라면 별도 검증이 필요합니다.
종합하면, PaddleOCR-VL은 “작지만 강한” 문서 파싱 모델로서 자체 호스팅 문서 인텔리전스에 매우 매력적인 선택지입니다. 다만 프로덕션에서는 GPU 서빙, 버전 고정, 입력 전처리라는 세 가지 운영 과제를 함께 풀어야 진가가 나옵니다.
출처(Sources)
- PaddleOCR-VL 논문(arXiv:2510.14528): Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
- 허깅페이스 모델 카드: PaddlePaddle/PaddleOCR-VL
- 소스 코드: github.com/PaddlePaddle/PaddleOCR
- 본문 실험은 ThakiCloud 환경(macOS, CPU)에서 직접 수행했으며, 인용한 벤치마크 수치는 위 논문 보고치입니다.
📄 심층 리뷰 전문(DOCX): 이 논문의 상세 피어리뷰를 Google Drive에서 다운로드할 수 있습니다.