MiniMax-M3: 428B MoE 멀티모달, 1M 컨텍스트와 MSA로 M2.7 대비 prefill 9배 빨라졌다
⏱️ 예상 읽기 시간: 8분
무엇이 새로운가
MiniMaxAI가 MiniMaxAI/MiniMax-M3를 공개했습니다. M2.7의 후속 모델로, 가장 눈에 띄는 변화는 속도입니다. 자체 보고 기준으로 M2 대비 prefill 9배, decode 15배 빠르며 per-token compute를 1/20 수준으로 줄였다고 밝혔습니다. 이 수치는 독립 검증이 없는 개발사 주장이므로 직접 태스크에서 확인해야 하지만, 방향성은 명확합니다. 1M 토큰 컨텍스트를 실용적인 속도로 처리하겠다는 설계 의도입니다.
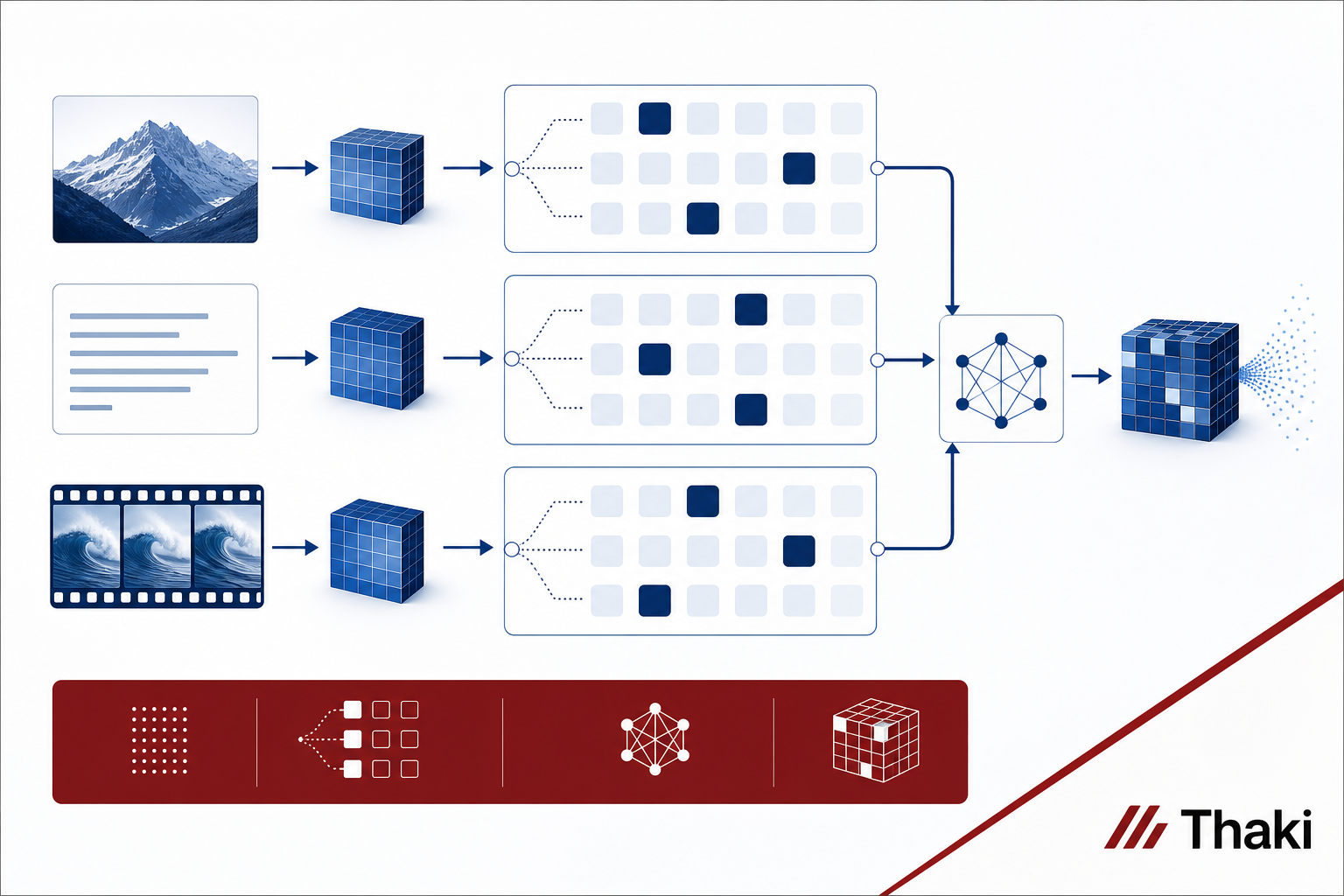
모달리티는 텍스트, 이미지, 비디오 세 가지를 네이티브로 처리합니다. 텍스트 전용이던 이전 세대와 달리 시각 정보를 입력받아 에이전트나 코딩 태스크에 활용할 수 있습니다. HuggingFace 태그에 agent, coding, video가 명시되어 있습니다.
아키텍처
총 파라미터는 약 428B이고 활성 파라미터는 약 23B입니다. MoE 구조에서 토큰당 실제 계산에 참여하는 전문가 수가 이 23B를 결정합니다. 전문가 개수나 레이어 수 같은 세부 MoE 파라미터는 모델 카드에 공개되어 있지 않습니다.
핵심 기술은 MiniMax Sparse Attention(MSA)입니다. 논문은 arXiv:2606.13392에 공개되어 있습니다. 표준 full attention의 O(n^2) 복잡도를 어텐션 희소화로 완화해 1M 컨텍스트를 현실적인 비용으로 처리합니다. 1M 컨텍스트를 지원하는 모델은 이미 여럿 나왔지만, MoE와 희소 어텐션을 함께 적용해 decode throughput까지 끌어올린 점이 M3의 차별점입니다.
추론 모드는 세 가지입니다. thinking=enabled는 chain-of-thought 스타일 추론, thinking=adaptive는 태스크 복잡도에 따라 자동 전환, thinking=disabled는 직접 응답입니다. 권장 추론 파라미터는 temperature 1.0, top_p 0.95, top_k 40입니다.
dtype은 BF16과 F32를 지원합니다. FP8은 M2.7에서 지원되었으나 M3 모델 카드에는 FP8 언급이 없습니다. 실제 배포 전 확인이 필요합니다.
벤치마크
공식 모델 카드에 구체적인 벤치마크 수치는 없습니다. 기재된 정보는 M2 대비 속도 향상 수치뿐입니다. 외부 리더보드나 독립 평가 결과는 arXiv:2606.13392 논문과 함께 확인하는 것이 맞습니다.
지원 언어 목록도 모델 카드에 명시되어 있지 않습니다. 멀티링귀얼 지원 여부는 직접 테스트로 확인해야 합니다.
서빙과 배포
M3는 SGLang, vLLM, Transformers, Ollama, llama.cpp, LM Studio, Jan을 공식 지원합니다. 온프렘 K8s 환경이라면 SGLang이나 vLLM을 Deployment로 띄우고 HTTP 서빙하는 경로가 현실적입니다.
428B 모델을 BF16으로 올리면 약 856GB VRAM이 필요합니다. H100 80GB 기준 11장, H200 141GB 기준 7장이 이론치입니다. MoE 특성상 토큰당 23B만 활성화되므로 실제 throughput은 dense 428B보다 훨씬 낫지만, 전체 파라미터를 VRAM에 올려야 한다는 점은 달라지지 않습니다.
양자화된 변형이 23종 공개되어 있습니다. 4비트 또는 8비트 양자화를 쓰면 GPU 요구량을 절반 이하로 줄일 수 있습니다. 단 양자화 버전별 품질 저하 정도는 직접 평가해야 합니다.
vLLM으로 M3를 서빙할 때는 tensor parallelism 설정이 필수입니다.
vllm serve MiniMaxAI/MiniMax-M3 \
--tensor-parallel-size 8 \
--dtype bfloat16 \
--max-model-len 65536
1M 전체 컨텍스트를 올리려면 KV 캐시 메모리까지 고려해 max-model-len을 조정해야 합니다. 테스트는 짧은 컨텍스트부터 시작해 점진적으로 늘리는 것이 안전합니다.
SGLang의 경우 MoE 모델에 최적화된 expert parallelism을 활용할 수 있습니다.
python -m sglang.launch_server \
--model-path MiniMaxAI/MiniMax-M3 \
--tp 8 \
--dtype bfloat16
라이선스
라이선스는 minimax-community입니다. Apache-2.0이나 MIT가 아닌 자체 라이선스입니다. 상업적 사용 조건, 재배포 제약, 파생 모델 규정이 표준 오픈소스와 다를 수 있습니다. 프로덕션 배포 전 LICENSE 원문을 반드시 검토해야 합니다.
ThakiCloud 관점
Kueue와 MoE 서빙 자원 관리. 428B MoE 모델은 GPU 자원 요구량이 크고 요청 패턴에 따라 throughput 변동이 큽니다. ThakiCloud 플랫폼에서는 Kueue의 ResourceFlavor와 ClusterQueue로 M3 전용 GPU 풀을 격리하고, 배치 추론과 온라인 서빙을 WorkloadPriorityClass로 분리하면 자원 경합 없이 운영할 수 있습니다.
1M 컨텍스트와 멀티모달 에이전트 파이프라인. M3의 1M 컨텍스트와 이미지/비디오 입력 능력은 문서 분석, 코드 저장소 전체 탐색, 영상 이해 에이전트 구축에 활용 가능합니다. 현재 ThakiCloud의 Kueue 기반 배치 파이프라인에 M3 서빙 엔드포인트를 붙이면 긴 컨텍스트가 필요한 태스크를 배치로 처리하는 구조를 만들 수 있습니다. 단 자원 비용이 크므로 태스크별로 실제 컨텍스트 길이가 얼마나 필요한지 먼저 측정하는 것이 선행되어야 합니다.
M2.7 기반 워크로드가 이미 있다면 M3로 업그레이드할 때 추론 파라미터(thinking 모드)와 멀티모달 입력 처리 부분을 별도로 검토해야 합니다. 드롭인 교체가 아니라 인터페이스 변경이 수반됩니다.